






本文來自格隆匯專欄:半導體行業觀察
以英特爾4004的誕生為開端,五十年的微處理器歷史已經書寫完成。幾乎沒有一個領域像微處理器那樣發展的如此迅速,在短短五十年間,微處理器的發展跨越了七個數量級--從2300個晶體管到540億個。最初的4位單個ALU設計已經演變成眾核巨無霸,這些進步幾乎為人類生活的每個方面提供了動力。
為了説明這些變化,MPR重點突顯了一些能定義整個行業的產品,包括英特爾8088、MIPS R2000、DEC Alpha 21164、英特爾Core Duo、IBM Power8和NvidiaA100。每一個產品都通過頻率和微體系結構的升級展示出不斷增長的性能。
在過去的50年裏,晶體管數量的上升與戈登-摩爾的預測(摩爾定律)保持了驚人的一致,即晶體管的數量每兩年就會翻一番。將這一翻倍速度應用於4004的晶體管,預測2020年將出現540億個晶體管的處理器,如圖1所示,Nvidia通過A100實現了這一目標。儘管晶體管數量仍然與性能密切相關,但在這段期間,各公司也通過電路結構和微體系結構創新提高了性能。
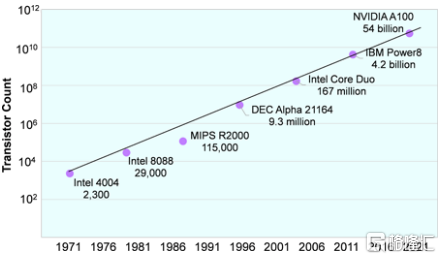
圖1 50年的晶體管數量
(按照摩爾定律,這一數字穩定的每兩年翻一倍。Nvidia的A100,當前達到光罩孔極限尺寸的芯片(reticle-size chip),完美的匹配這一預測。(數據來源:各個廠商))
一個人的軍隊推出4004
英特爾於1971年發佈了其4位4004處理器,在兩英寸晶圓上以10微米的工藝製造它。與以前擁有幾十或幾百個晶體管的集成電路相比,它是當時最先進的設計,包括2250個晶體管。然而,它是由單獨一名工程師費德里科-法金(Federico Faggin)創造的,他每週工作80小時,以按期交付740kHz的處理器(見MPR 12/18/06,"英特爾4004的35週年")。除了設計邏輯和電路之外,他還必須手工切割用於製造光學掩模的紅寶石薄膜。在一個自我陶醉的時刻,設計師在一個掩模上刻下了“F.F.”。
4004只實現了46條指令,其中5條是雙倍長度。該處理器集成了一個單一的ALU,在8個時鐘週期內完成4位加法(和大多數其他指令),使其有效執行率低於0.1MHz。儘管有一個完整的CPU,尺寸為12平方毫米,但4004無法獨立運行,因為除了64位(16x4位)寄存器文件外,它缺乏任何存儲器。因此,Faggin還交付了4001 ROM芯片、4002總線接口芯片、4002 RAM芯片和4003總線接口芯片。
4004徹底改變了市場,因為它是第一個軟件可編程的芯片。它首先服務於Busicom公司的141-PF計算器,因為該公司擁有該設計的獨家權利。但Intel意識到可編程性使這一設計適用於廣泛的系統,因此它通過談判達成協議,允許Intel向其他客户出售4004,從而開創了微處理器市場。即使在1971年,該公司也着眼於遊戲市場;例如,4004最終進入了彈球機,為曾經的純機械遊戲增添了光彩。
8088為IBM個人電腦提供動力
16位的Intel 8088於1979年投入生產。如圖2所示,該公司使用其3微米技術製造了這個包含29000個晶體管的芯片。峯值速度徘徊在5MHz左右。英特爾在其新建的以色列海法實驗室創造了8088。該處理器與8086基本相同,後者引入了x86指令集,但8088將外部總線接口減少到8位以降低系統成本。與8086一樣,它有一個6字節的取指隊列,一個16位的ALU和16位的寄存器。它的簡單流水線有兩個流水段:取指/譯碼和執行。

圖2 AMD的8088芯片晶片管芯照片
(8088有33平方毫米和29,000個晶體管。雖然芯片最早是Intel設計的,許多類似AMD的廠商獲得了設計授權能夠進行製造。(照片源自Pauli Rautakorpi《維基百科<https://en.wikipedia.org/wiki/Intel_8088#/media/File:AMD_8088_die.JPG>》,按照CC BY 3.0授權))
然而,與8086相比,8088由於其較窄的數據總線和較小的預取隊列而出現性能問題。它體現了順序處理器的低效率:例如,程序員需要將長指令與短指令交錯使用,以避免瓶頸。8088在調用、跳轉和中斷方面也有困難,因為這些指令重置了預取隊列,可能需要15個週期來重新填充。4004需要定製存儲芯片,而8088可以使用商品RAM和ROM。客户通常將8088與英特爾的8位鎖存器8282處理器、8284時鐘發生器、8位8287驅動器、8288總線控制器、8259總線仲裁器和8087數學協處理器配對使用。
8088在第一台IBM PC中贏得了一個重要的設計,確保了英特爾和x86體系結構在個人電腦PC革命的長期中心地位。英特爾並不是唯一一家提供8088解決方案的公司;IBM要求有第二個供應來源,因此英特爾將8088設計授權給AMD、NEC、德州儀器和其他公司。在這一時期,授權處理器是很常見的,但英特爾最終在1985年的80386時代停止了這種做法。
MIPS提供了第一個RISC處理器
MIPS計算機系統公司在1986年提供了MIPSISA的第一個商業實現,從而震撼了計算機體系結構的世界。R2000是第一個商業化的RISC體系結構,啟動了RISC與CISC的辯論。這款32位110,000晶體管的芯片有三個速度等級:8.3MHz、12.5MHz和15MHz。MIPS是第一批無工廠產線的處理器供應商之一,將R2000外包給Sierra半導體公司並使用其2微米的雙層金屬CMOS工藝(見MPR 2/89,"MIPS挑戰SPARC和88000")。
R2000的執行引擎有一個ALU和一個乘法/除法單元。簡化的RISC結構在每個時鐘週期處理一條指令,遠遠超過了競爭性的CISC處理器。該CPU有五個流水段,使其成為未來幾十年內的順序RISC設計模板,包括RISC-V的RocketCPU。像同時期的80386一樣,R2000需要外部芯片來實現高速緩衝存儲和(可選擇)執行浮點(FP)運算。
R2000在工作站和服務器製造商中特別受歡迎。其強大的數學性能使MIPS成為工程師和科學家的理想選擇,而ISA因其優化的軟件棧而變得更加流行。編譯器設計者幫助創建了最早的ISA模擬器之一,這加速了UNIX在MIPS機器上的應用。
DEC在性能上壓倒了英特爾
如圖3所示,Alpha 21164是一款野獸般的微處理器。數字設備公司(DEC)於1994年發佈,它的最高頻率為300MHz(見MPR 9/12/94,"Digital公司以21164引領潮流")。七級流水線比任何競爭者的設計都要深,使該處理器具有速度優勢。21164實現了DEC專有的64位Alpha體系結構,支持UNIX和OpenVMS。該公司用自己的0.5微米工藝製造該芯片,塞進了930萬個晶體管。

圖3 DEC公司Alpha 21264的晶片管芯照片
(這款芯片在當時是龐然大物,尺寸為314平方毫米。主頻300MHz,遠遠超過其他競爭芯片。(照片源自Pauli Rautakorpi《維基百科<https://en.wikipedia.org/wiki/Intel_8088#/media/File:AMD_8088_die.JPG>》,按照CC BY 3.0授權))
21164的超標量微體系結構與最近的處理器相似。它集成了一個8KB的指令緩存,並將指令傳遞給一個寬度為4的譯碼器,該解碼器每個週期向執行引擎發出四條譯碼後的指令。21164包括兩個整數單元和兩個浮點單元用於算術運算。它還實現了一個片上二級緩存,容量為96KB。該設計有一個43位的虛擬地址空間和一個40位的物理地址空間,使其能夠處理比同時代更多的存儲。8TB的虛擬內存和1TB的DRAM。這種地址空間為需要大型數據集的應用提供了獨特的優勢。
在發佈時,21164擴大了DEC的性能領先優勢:它在SPECint95中的得分是15.4,在SPECfp95中的得分是21.1,在這兩個方面都超過了英特爾的Pentium。由Alpha 21164驅動的系統因此完成了新的壯舉,如CAD建模,多媒體編輯,甚至是視頻會議。1994年,DEC公司處於世界之巔,因為它的Alpha組合提供了無可匹敵的性能。但是,當英特爾的Pentium Pro(P6)到來時,好日子就結束了,它使用RISC技術來提高x86性能。從那時起,RISC在PC和服務器中的受歡迎程度急劇下降,DEC在2001年放棄了Alpha。
酷睿雙核是第一個多核PC處理器
英特爾在2006年發佈了Core Duo,這是第一個多核的個人電腦PC處理器。服務器之前已經採用了多核芯片,但該公司將這種方法帶到了個人電腦上,為筆記本電腦和台式機提供了兩種不同的設計(見MPR 10/3/05,"Yonah做雙核的權利")。該公司在其65納米節點上製造了管芯面積為143平方毫米的台式機版本(Conroe),包裝了2.91億個晶體管。它的頻率達到3.0GHz,同時運行32位和64位x86體系結構。在英特爾的高主頻NetBurst方法火了之後,Conroe是第一批使用Core微體系結構的處理器之一,該體系結構仍然是該公司目前旗艦CPU的基礎。
酷睿雙核Core Duo開啟了今天的多核運動,併成為中心。通過將兩個CPU裝在一個管芯Die上以填補其晶體管預算,英特爾大大提升了性能。另一個選擇是建立一個更復雜的單核CPU,相對於上一代產品,其尺寸增加了一倍,但這被證明是不可行的。亂序的Core CPU核心集成了一個32KB的指令和數據緩存,四個解碼器,一個96個條目的重排緩衝器,以及五個用於內存和算術操作的執行端口。它集成了一個128位SIMD單元,用於加速英特爾的向量(SSE)擴展。
新的雙核處理器不僅因其性能而聞名,而且還因其(當時)令人印象深刻的65W功耗TDP等級而聞名。然而,雙核模式給軟件帶來了問題,這些軟件被設計為在單個CPU上運行。工程師需要實現多線程編程模型。發佈升級的軟件花了幾年時間;在這期間,很少有用户能看到承諾的性能提升。
Power8將多線程帶入一個新的水平
到2014年,多線程軟件已經成為常態,但Power8將多線程帶到了一個新的水平。2014年發佈的它是一個多線程的怪物,包裝了12個核心,有96個線程(見MPR 12/29/14,"Power8衝擊商業市場")。IBM用22納米絕緣體上硅(SOI)工藝製造了這顆190W的芯片。即使按照現代標準,它也是巨大的,面積為650mm2,裝有42億個晶體管,如圖4所示。這也是第一個可供商業購買的POWER芯片。

圖4 Power8的晶片管芯照片
(在2014年,IBM通過12核,每核4線程將多線程推進到新的高度。22納米的晶片管芯尺寸是650平方毫米,同時封裝了42億晶體管。(由IBM拍攝的晶片管芯照片))
在設計Power8時,片上存儲器成為IBM的重點。該芯片每個內核採用512KB的二級緩存,96MB的嵌入式DRAM(eDRAM)用於L3緩存。eDRAM的使用是獨一無二的:它使IBM能夠在芯片上集成大量的存儲,而單靠SRAM是不可能做到的。即使是巨大的內核數量,Power8的速度也達到了3.6GHz。該設計的特點是具有14個執行單元的特別寬的執行引擎,可以處理分支以及整數、浮點、定點和向量操作。廣泛的執行引擎幫助Power8在IPC方面超過了競爭對手。
該處理器仍然讓Intel在服務器市場上賺到錢。Power8的價格比英特爾的旗艦產品至強E5-2699v3低30%,提供類似的整數性能和領先的浮點性能。全球的銀行家和零售商都受益於定點的十進制引擎,它加速了傳統的Cobol軟件。儘管有更好的性能和更低的價格,但該處理器缺乏X86兼容性,使其在IBM自己的系統之外沒有獲得吸引力。
Nvidia A100達到了光照極限(Reticle Limit)
Nvidia的A100最能代表當今的高性能處理器,它使用專門的體系結構在一個流行的應用程序上實現了領先的性能。該公司的GPU已經成為神經網絡訓練的代名詞(見MPR 6/8/20,"Nvidia A100在AI性能方面名列前茅")。在過去十年中,人工智能應用的普及率飆升,觸及日常生活的許多方面。但神經網絡帶來的巨大計算壓力造成了對專門硬件的需求。用於數據中心400W的A100 GPU在20年第二季度投入量產,並立即成為AI的熱門產品。它具有540億個晶體管;在7納米統一中,826毫米的巨大芯片測試了台積電的光照尺寸極限。
A100實現了Nvidia的AmpereGPU體系結構,以加速AI訓練和推理。VLIW配置減少了指令調度邏輯,許多SIMD單元有利於計算神經網絡經常採用的大型卷積。該芯片有108個GPU核心,包含矩陣乘法單元和向量ALU。它的發佈使英偉達處於人工智能市場的頂端。該公司圍繞A100及其他基於GPU的人工智能加速器建立了一個龐大的軟件生態系統,其目標是幾乎所有可以想象的領域,從醫療保健到農業到分子動力學。
摩爾定律的勝利
如表1所示,在過去的50年裏,單個芯片上的晶體管數量已經爆炸性增長。表中的每個產品都需要重大的工藝技術進步,從光學光刻到紫外線、多重曝光,以及今天的EUV(見MPR 5/20/19,"EUV工藝達到大規模生產")。晶體管面積下降了200萬倍。隨着缺陷率的下降和工藝的改進,晶片管芯尺寸也在增加,允許每個芯片有更多的晶體管。這些因素使更復雜的微體系結構、更多的片上存儲器,以及最終每片更多的內核成為可能,提高了性能。
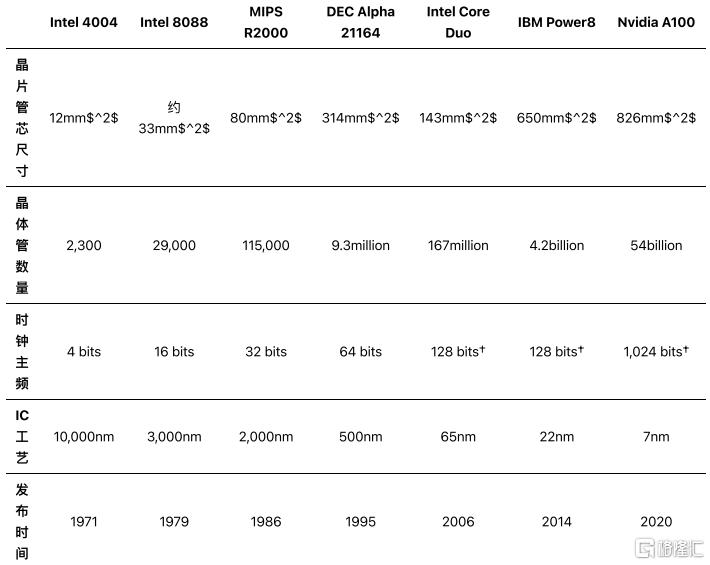
表1 歷史上的MPU對比
(50多年來,晶體管數量猛增。這種增長之所以可能,是因為主流工藝技術的改進。†使用了向量(SIMD)單元。(來源:廠商))
對於基於CPU的處理器,頻率上升了四個數量級。4004開始時不到1MHz,但現代Intel處理器可以達到5,200MHz。CPU設計者使用了兩種技術來提高時鐘頻率:一種是依靠代工廠提高晶體管速度,另一種是通過微體系結構的升級來實現收益。
雖然A100是一個GPU,但MPR仍然認為它是一個處理器,因為它加載和執行指令。MPR把Nvidia的芯片包括在內,以強調GPU和AI產品現在是如何推動摩爾定律的。最先進的設計有數百個1,024位的ALU,與原始微處理器上的單一4位ALU相比,相差甚遠。
我們是如何走到今天的?
沒有一篇文章能涵蓋微處理器50年的全部歷史。MPR的精心策劃包括了其認為在這個時間段內具有代表性的產品,強調了處理器所經歷的許多結構變化。最早的例子只能執行最基本的功能,如加法,而且缺乏片上存儲器。隨着時間的推移,設計者集成了一些功能,如浮點單元和總線接口,而這些功能以前是在獨立的芯片上。
一旦整個CPU都在芯片上,公司開始增加更多的CPU。數據路徑從4位擴展到64位,對於專門的SIMD單元來説甚至更寬(在這個過程中消耗了許多晶體管)。緩存在20世紀80年代開始成為一種外部功能,在20世紀90年代轉移到芯片上,並發展成為今天覆雜的多級緩存。更深的流水線實現了更高的時鐘速度,但它們需要更多的緩衝器和旁路邏輯,進一步增加了晶體管數量。
雖然更深的流水線和更寬的執行單元等技術似乎已經達到了極限,但芯片設計者仍在試圖通過嘗試不同的方法來提高性能,如特定應用和異構體系結構。當他們缺乏更好的想法時,他們會增加更多的CPU內核,儘管很少有PC應用能夠使用它們。
相對於人類歷史的跨度,50年幾乎是一個小點。然而,在這個微不足道的時期,微處理器的發展速度令人難以置信。它們無處不在,從微波爐到自動駕駛汽車。當人們花時間欣賞微處理器時,也必須記住這項寶貴的發明是如何從簡陋的4004開始的。








