本文來自格隆匯專欄:半導體行業觀察
伴隨着英偉達AI芯片的熱賣,HBM(高帶寬內存)成為了時下存儲中最為火熱的一個領域,不論是三星、海力士還是美光,都投入了大量研發人員與資金,力圖走在這條賽道的最前沿。
HBM 的初衷,是為了向 GPU 和其他處理器提供更多的內存,但隨着GPU 的功能越來越強大,需要更快地從內存中訪問數據,以縮短應用處理時間。例如,在機器學習訓練運行中,大型語言模型 (LLM) 可能需要重複訪問數十億甚至數萬億個參數,而這可能需要數小時或數天才能完成。
這也讓傳輸速率成為了HBM的核心參數,而已有的HBM都採用了標準化設計:HBM 存儲器堆棧通過微凸塊連接到 HBM 堆棧中的硅通孔(TSV 或連接孔),並與放置在基礎封裝層上的中間件相連,中間件上還安裝有處理器,提供 HBM 到處理器的連接。與普通的DRAM相比,如此設計的HBM能夠垂直連接多個DRAM,能顯著提升數據處理速度,
目前,HBM 產品以HBM(第一代)、HBM2(第二代)、HBM2E(第三代)、HBM3(第四代)、HBM3E(第五代)的順序開發,最新的HBM3E是HBM3的擴展版本,速率達到了8Gbps。
但對於AI芯片來説,光靠傳統的硅通孔已經無法滿足廠商對於速率的渴求,內存廠商和標準機構正在研究如何通過使用光子等技術或直接在處理器上安裝 HBM,從而讓像GPU 這樣的加速處理器可以獲得更快的內存訪問速度。
誰才是新方向?
雖然目前業界都在集中研發HBM3的迭代產品,但是廠商們為了爭奪市場的話語權,對於未來HBM技術開發有着各自不同的見解與想法。
三星
三星正在研究在中間件中使用光子技術,光子通過鏈路的速度比電子編碼的比特更快,而且耗電量更低。光子鏈路可以飛秒速度運行。這意味着10-¹⁵個時間單位,即四十億分之一(十億分之一的百萬分之一)秒。在最近舉行的開放計算項目(OCP)峯會上,以首席工程師李彥為代表的韓國巨頭先進封裝團隊介紹了這一主題。

除了使用光子集成電路外,另一種方法是將 HBM 堆棧更直接地連接到處理器(上圖中的三星邏輯圖)。這將涉及謹慎的熱管理,以防止過熱。這意味着隨着時間的推移,HBM 堆棧可以升級,以提供更大的容量,但這需要一個涵蓋該領域的行業標準才有可能實現。
SK海力士
據韓媒報道,SK海力士還在研究 HBM 與邏輯處理器直接連接的概念。這種概念是在混合使用的半導體中將 GPU 芯片與 HBM 芯片一起製造。芯片製造商將其視為 HBM4 技術,並正在與英偉達和其他邏輯半導體供應商洽談。這個想法涉及內存和邏輯製造商共同設計芯片,然後由台積電(TSMC)等晶圓廠運營商製造。
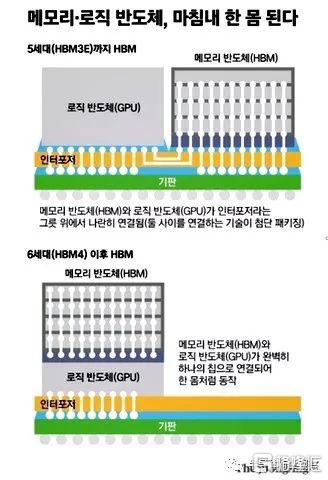
這有點類似於內存處理(PIM)的想法,如果最終不能成為行業標準的話,很可能會變成事實上的廠商獨佔。
美光
Tom's Hardware 報道稱,美光與市場上的其他公司正在開展 HBM4 和 HBM4e 活動。美光目前正在生產 HBM3e gen-2 內存,採用 8層垂直堆疊的 24GB 芯片。美光的 12 層垂直堆疊 36GB 芯片將於 2024 年第一季度開始出樣。它正與半導體代工運營商台積電合作,將其 gen-2 HBM3e 用於人工智能和 HPC 設計應用。
美光表示,其目前的產品具有高能效,對於安裝了1000萬個GPU的設備來説,每個HBM堆棧能節省約5瓦的功耗,預計五年內將比其他HBM產品節省高達5.5億美元的運營開支。
下一代HBM
2015年以來,從HBM1到HBM3e,它們都保留了相同的1024位(每個堆棧)接口,即具有以相對適中的時鐘速度運行的超寬接口,為了提高內存傳輸速率,下一代HBM4可能需要對高帶寬內存技術進行更實質性的改變,即從更寬的2048位內存接口開始。
出於多種技術原因,業界打算在不增加 HBM 存儲器堆棧佔用空間的情況下實現這一目標,從而將下一代 HBM 存儲器的互連密度提高一倍。HBM4 會在多個層面上實現重大技術飛躍。在 DRAM 堆疊方面,2048 位內存接口需要大幅增加內存堆疊的硅通孔數量。同時,外部芯片接口需要將凸塊間距縮小到遠小於 55 微米,而 HBM3 目前的凸塊總數(約)為 3982 個,因此需要大幅增加微型凸塊的總數。
內存廠商表示,他們還將在一個模塊中堆疊多達 16 個內存模塊,即所謂的 16-Hi 堆疊,從而增加了該技術的複雜性。(從技術上講,HBM3 也支持 16-Hi 堆疊,但到目前為止,還沒有製造商真正使用它)這將使內存供應商能夠顯著提高其 HBM 堆疊的容量,但也帶來了新的複雜性,即如何在不出現缺陷的情況下連接更多的 DRAM 凸塊,然後保持所產生的 HBM 堆疊適當且一致地短。
在阿姆斯特丹舉行的台積電 OIP 2023 會議上,台積電設計基礎設施管理主管這樣説道:"因為[HBM4]不是將速度提高了一倍,而是將[接口]引腳增加了一倍。這就是為什麼我們要與所有三家合作伙伴合作,確保他們的 HBM4(採用我們的先進封裝方法)符合標準,並確保 RDL 或 interposer 或任何介於兩者之間的產品都能支持(HBM4 的)佈局和速度。因此,我們會繼續與三星、SK 海力士和美光合作"。
目前,台積電的 3DFabric 存儲器聯盟目前正致力於確保 HBM3E/HBM3 Gen2 存儲器與 CoWoS 封裝、12-Hi HBM3/HBM3E 封裝與高級封裝、HBM PHY 的 UCIe 以及無緩衝區 HBM(由三星率先推出的一項技術)兼容。
美光公司今年早些時候表示,"HBMNext "內存將於 2026 年左右面世,每堆棧容量介於 36 GB 和 64 GB 之間,每堆棧峯值帶寬為 2 TB/s 或更高。所有這些都表明,即使採用更寬的內存總線,內存製造商也不會降低 HBM4 的內存接口時鐘頻率。
總結
與三星和 SK海力士不同,美光並不打算把 HBM 和邏輯芯片整合到一個芯片中,在下一代HBM發展上,韓系和美系內存廠商涇渭分明,美光可能會吿訴AMD、英特爾和英偉達,大家可以通過 HBM-GPU 這樣的組合芯片獲得更快的內存訪問速度,但是單獨依賴某一家的芯片就意味着更大風險。
美國的媒體表示,隨着機器學習訓練模型的增大和訓練時間的延長,通過加快內存訪問速度和提高每個 GPU 內存容量來縮短運行時間的壓力也將隨之增加,而為了獲得鎖定的 HBM-GPU 組合芯片設計(儘管具有更好的速度和容量)而放棄標準化 DRAM 的競爭供應優勢,可能不是正確的前進方式。
但韓媒的態度就相當曖昧了,他們認為HBM可能會重塑半導體行業秩序,認為IP(半導體設計資產)和工藝的重大變化不可避免,還引用了業內人士説:"除了定製的'DRAM 代工廠'之外,可能還會出現一個更大的世界,即使是英偉達和 AMD 這樣的巨頭也將不得不在三星和 SK 海力士製造的板材上進行設計。"
當然SK 海力士首席執行官兼總裁 Kwak No-jeong的發言更值得玩味,他説:“HBM、計算快速鏈接(CXL)和內存處理(PIM)的出現將為內存半導體公司帶來新的機遇,這種濱化模糊了邏輯半導體和存儲器之間的界限,內存正在從一種通用商品轉變為一種特殊商品,起點將是 HBM4。”
由此看來,下一代HBM技術路線的選擇,可能會引發業界又一輪重大的洗牌,誰能勝出,我們不妨拭目以待。