





本文來自格隆匯專欄:半導體行業觀察 作者:IEEE
編者按
由於Chiplets技術的大火,面向Chiplets互連集成的UCIe標準也已成為目前被大家所關注的熱點。國內很多單位和個人都在研讀、討論甚至翻譯UCIe標準。
但在UCIe標準冰冷的規範背後,其實是有技術體系支撐的。
而近期,Intel公司在IEEE Transactions on Components, Packaging and Manufacturing Technology期刊上發表了一篇名為“Universal Chiplet Interconnect Express (UCIe): An Open Industry Standard for Innovations with Chiplets at Package Level”的論文,在論文中Intel公司披露了一些標準背後的技術原理,例如Die-2-Die的“眼圖”、封裝通道性能等。
因此半導體行業觀察聯合電子科技大學長三角研究院(湖州)集成電路與系統研究中心翻譯此文,為各位讀者朋友提供參考。
引言
戈登·摩爾(Gordon Moore)在他提出了“摩爾定律”[1]的開創性論文中預測了“清算日”的到來——“用分別封裝並相互連接的多個小功能系統構建大型系統可能是更經濟的。”今天,我們已經度過了那個拐點。多個裸芯的封裝集成已廣泛應用於半導體行業,包括主流的中央處理單元(CPU)和通用圖形處理器單元(GP-GPU)[2]。
封裝內小芯片的發展受多方面因素驅動。克服光刻機最大尺寸的限制的,保障性能/功能的前提下生產更大規模的裸芯,是各大公司發展出其特有方案的主要原因。
降低總體組合成本,同時擁有上市時間優勢,這將是發展Chiplet的一個令人信服的驅動因素。例如,Figure 1[3]所示的計算核心可以在採用先進工藝實現,以提供領先的電源效率,而包含內存和輸入/輸出(I/O)控制器功能的結構可以複用已經成熟工藝中的設計。這樣的分割方式也可以使裸芯更小,從而獲得更高的良率。此外,這種方法有助於降低IP移植成本,對於先進工藝[3],IP移植成本顯著增加。
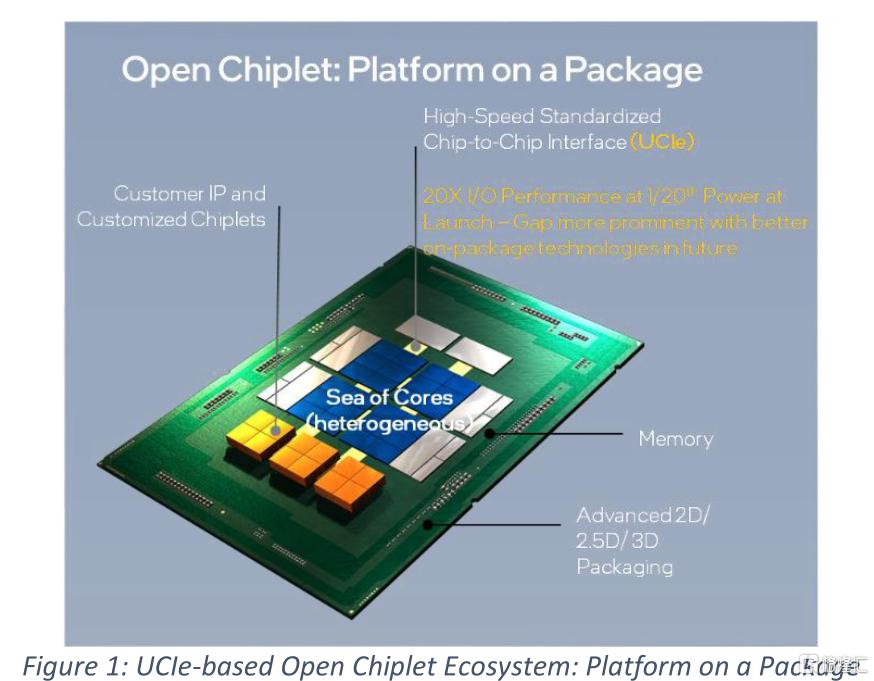
Chiplet的另一個價值是可以提供定製的解決方案。例如,人們可以根據特定產品領域的需求,選擇不同數量的運算、內存和I/O以及加速器芯片。人們不再需要為不同的細分市場做不同的裸芯設計,降低了設計,驗證和產品成本。
UCIe[4]是一種開放的行業標準互連,為異構芯片間提供了高帶寬、低延遲、高電源效率和高性價比的封裝內連接,以滿足整個計算系統的需求。UCIe 1.0規範[4]包含了堆棧的所有層級(圖2a),是我們所知的唯一具有明確規範機制的完整規範,該規範面向使用PCI-Express(PCIe)[5、6]和Compute Express Link (CXL)[7]協議和軟件基礎設施的組件的異構集成,以確保互操作性。這使得設計者能夠使用廣泛的封裝技術對不同來源的芯片進行封裝,包括不同的工廠。UCIe是先前工作的演進,它已經作為專有的多裸芯結構接口(MDFI),在Intel Sapphire Rapids CPU中實現[2]。本文所描述的關鍵指標、特性和仿真方法已在Sapphire Rapids silicon[2]中得到驗證。

本文在第二節中深入研究了UCIe的要求和使用模式。在第三節中描述了我們提出的方法,該方法在UCIe規範[4]中得到了廣泛採用。我們將在第四節介紹我們的成果,並在第五節得出結論。
UCIe1.0規範針對的使用模式、封裝技術和性能指標
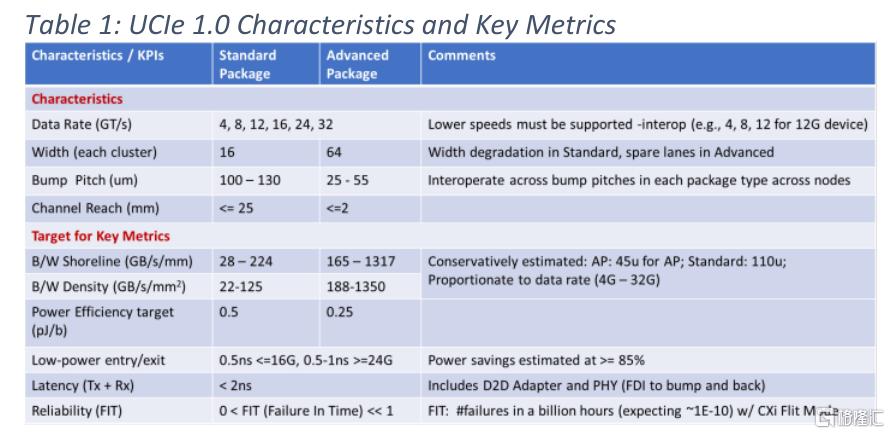
UCIe 1.0支持兩種類型的封裝,如圖2b所示。標準封裝(2D)被稱為UCIe-S,用於實現高性價比。先進的封裝(UCIe-A)用於提高電源效率。有多種商業上可用的選擇,可以部署UCIe-S和UCIe-A,其中一些如圖所示。UCIe 1.0規範包含了這些類別中的所有類型的打包選擇。表1[3]總結了UCIe 1.0規範的業界領先性能指標。
UCIe建議的方法
我們的方法是一個規範的分層標準,包括協議層、適配器和物理層(PHY)。我們將首先簡要説明這些層,然後重點介紹獨特的電路架構和封裝通道設計特性,以實現目標性能、靈活性和互操作性。
A.分層
PHY負責電信號、時鐘、鏈路訓練、邊帶等、電路架構和封裝互連通道。
Die-to-die適配器為Chiplet提供鏈路狀態管理和參數協商。當啟用時,它通過其循環宂餘校驗(CRC)和鏈路級重傳機制保證數據的可靠傳遞。它的底層仲裁機制支持多種協議。256字節(或68字節)流量控制單元(FLIT)支持底層的可靠傳輸機制。
我們將PCIe和CXL協議映射到UCIe中,因為這些協議被廣泛部署在所有計算機系統的板級上。這樣做是為了利用現有的生態系統,確保無縫互操作性,使板級組件可以被打包到一個封裝中。通過PCIe和CXL,當今平台上部署的片上系統(SoC)、鏈路管理和安全解決方案可以無縫遷移到UCIe。
我們為UCIe這樣die-to-die互連的使用模式的解決方案是全面的:使用直接內存訪問的數據傳輸,軟件發現,錯誤處理等,通過PCIe/CXL.io解決;內存使用情況通過CXL.Mem處理;而加速器等應用程序的緩存需求是通過CXL.cache解決的。我們還定義了一個“流協議”,它可以用來映射任何其他協議,如專有的對稱緩存一致性協議(例如,超路徑互連)。我們的方法還使UCIe聯盟能夠創新出新的協議,以覆蓋新的使用模式或改進現有的協議。
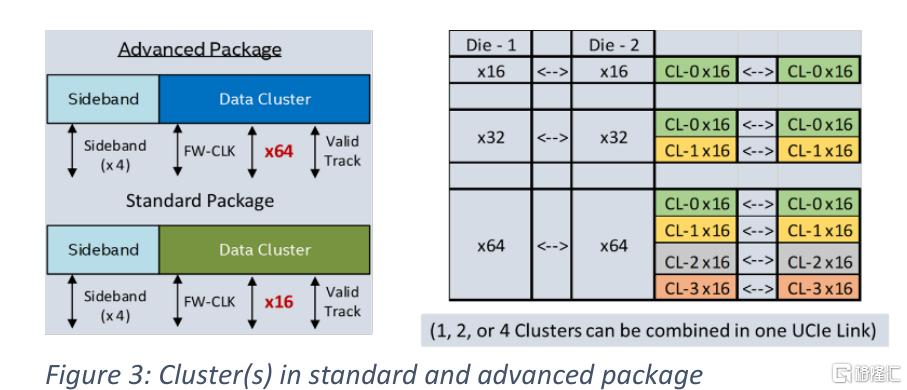
我們支持不同的數據速率、寬度、凸距和通道範圍,以確保最廣泛的互操作性,如表1所示。互連的構建單元是一個集羣(cluster),其中包括N個單端、單向、全雙工數據通道(標準封裝的N = 16,先進封裝的N = 64),一個用於valid的單端的通道,一個用於tracking通道,每個方向有一個差分轉發時鐘,每個方向有兩個用於邊帶的單端通道(一個用於800Mhz時鐘,一個用於數據)。邊帶接口用於狀態交換,方便數據集羣中鏈路的訓練,即使在在鏈路未被訓練的情況下,也有寄存器訪問機制,用於診斷。先進封裝支持使用備用通道來處理故障通道(包括時鐘、valid、邊帶等),而標準封裝支持寬度降級來處理故障。可以聚合多個集羣來為每個鏈接提供更高的性能,如圖3所示。
B.物理層架構
我們在構建UCIe PHY層時已經將集成設備製造商(IDM)和外包半導體組裝和測試(OSAT)可移植性考慮在內。大多數電路組件可以用數字類型的電路構建,如推輓發射機(TX)、數字延遲鎖定環(DLL)和相位插補器(PI)、基於變頻器的前端接收器(RX)、用於採樣的動態鎖存比較器和基於變頻器的時鐘分佈。一些組件可以與更高性能的標準模擬模塊互換,如用於RX模擬前端(AFE)的連續時間放大器、片上終端、電感器、片上穩壓器等,它們可移植到任何現代IDM節點。
我們為UCIe-A和UCIe-S提出了相同的時鐘和信號方案。這些方案包括源時鐘同步和匹配的時鐘/數據延遲路徑,以實現在噪聲較大的供電環境中仍有穩定的性能,同時將不歸零(NRZ)編碼信號作為下一節將討論的通道規格的最佳能耗/性能。TX輸出擺幅被規定為400 mV-850 mV的寬工作範圍,以允許實現複雜性與通道能耗/性能優化。RX必須滿足輸入在16GT/S時眼圖大小(高*寬)40mV*47ps以及在32GT/s是眼圖大小為40 mV*20ps的標準。在早期訓練階段的參數協商將把擺幅等級傳達給接收的裸芯,此外RX觸發點以及其他參數校準也可以在這個時候完成。
經過訓練後,鏈路的時鐘和數據路徑間將有大約0.5單位間隔(UI)。這個0.5UI的目標使鏈路有效地成為一個“匹配的架構”,對最大限度地減少確定性抖動(DJ)對鏈路定時性能的影響至關重要。在降低供電電壓,時鐘和數據路徑之間的0.5 UI延遲增量為電源下降的幅度乘以電路路徑的α係數(即延遲變化相對於VCC變化的百分比)。通常在低壓供電時,時鐘和數據路徑之間的延遲增量越大,兩條路徑之間的偏移就越大。這種額外的偏移會直接導致鏈接性能下降。建議的0.5 UI架構允許在16 GT/s的電壓下提供40-50 mV的電源噪聲。相比之下,1.5或2.5的UI目標將需要更嚴格的電源噪聲規格或高帶寬跟蹤機制,這可能會帶來大量的能耗。RX端的匹配架構要求通過數據和時鐘路徑的延遲到採樣觸發器之間的間隔不超過0.1個UI。將由兩個具有控制端的CMOS緩衝器組成的糾偏緩衝器(De-Skew)添加到每個數據路徑通道,用於通道間的糾偏校準。如果考慮到較高的電源噪聲容限,整體功率和噪聲影響可以忽略不計。圖4展示了我們提議的PHY體系結構的概述。

來自RDI接口的線路(圖2a)經過跨時鐘域FIFO,來重新計時協議鎖相環和物理層鎖相環時鐘域之間的信號。FIFO被轉換為串行輸出,並通過一個阻抗補償的TX驅動程序傳輸。時鐘路徑包括一個延遲鎖相環(DLL),用於為精密的偏移調節器(PI)和佔空比校正器(DCC)生成必要的參考值(正交或相同)。在接收機裸芯上,通過在數據RX AFE和採樣觸發器之間添加一些延遲(通常是2個反向器)來匹配發送到採樣器觸發器的數據和時鐘路徑,以匹配時鐘RX AFE+相位生成/時鐘分配帶來的延遲。
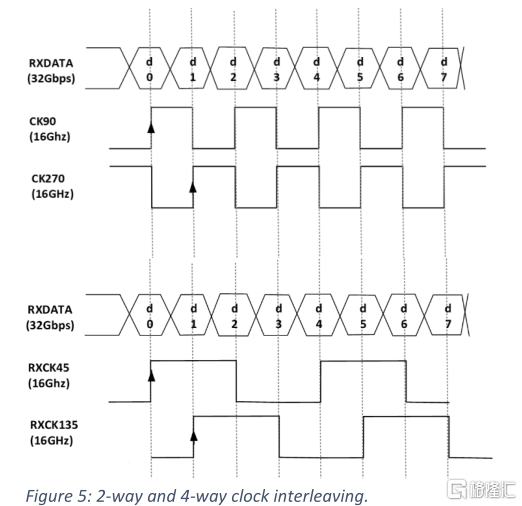
時鐘的兩個相位被分為偶數時鐘和奇數時鐘。對於4 GT/s, 8 GT/s, 12 GT/s和16 GT/s,兩個時鐘以90°和270°的相位,以一半數據速率(例如,2 GHz為4 GT/s, 4 GHz為8 GT/s)發出。這是基於傳輸端以0°相位傳輸數據而言的,因此到採樣器的時鐘和數據路徑之間所需的0.5 UI相位差。差分轉發時鐘的兩個邊緣都用來在RX處採樣,稱為2路交錯。對於24 GT/s和32 GT/s的操作,支持額外的可選4路交錯,配置為45/135度,以優化功率。圖5總結了用於實現靈活性和功率優化的2路或4路時鐘交錯選項。在較高的數據速率下,實現4路交錯通常比2路交錯更節能。在考慮到入口/出口延遲和相應的高di/dt和更高的電源噪聲時,建議使用全局時鐘方案獲取最佳的性能優化。這在較低的數據速率下尤其重要,這也將與未來的3D die-to-die標準十分相關。
此外,PHY架構還有一些附加細節,包括一個Valid通道,用於在流量空閒時啟用時鐘門控(<1 ns)。我們估計,在這種空閒狀態下,通過選通包括從鎖相環輸分佈到每個PHY模塊的主幹在內的大部分時鐘,可以節省≥85%的總功率。這種方法在利用率低於100%情況下運行的工作負載特別有效。我們還分配了一個Track通道,它可以在後台由於温度漂移而調整時鐘到數據的偏移。
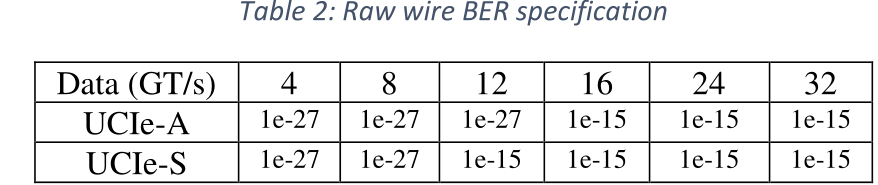
保持0.5 UI的時鐘到數據偏移的源同步時鐘,使得鏈路在電源噪聲環境中保持穩定的性能。這使得可以採用較低的VCC,以實現最佳功率/延遲性能的最佳平衡,同時避免嚴格的電源調節,以簡化SoC集成。表2總結了在表1所示數據速率下,達到<<1.0的及時故障(FIT)率所需的原線誤碼率(BER)。在較低的操作數據速率下,PHY原線誤碼率為1e-27。在較高的數據速率下,原線誤碼率為1e-15;使用16位CRC可以實現目標FIT。
C.標準封裝通道設計
我們根據最先進的Flip-Chip封裝技術定義UCIe標準模塊,以實現表1中的性能目標。我們的建議方案提供了很大的靈活性,包含了封裝行業中各種技術產品。我們建議採用一個固定大小的模塊,以促進各芯片之間的互操作性。
圖6所示的Flip-Chip封裝,是當今主流的封裝解決方案[8]。在過去的30年裏,封裝技術獲得了極大的發展。目前,最大的層數大於20(例如,2個核心層,正反面均有9個堆砌層),最大的外形尺寸超過3000毫米²。為了與摩爾定律的擴展保持同步,受控塌陷連接(C4)凸點的最小間距減小到約100 μ m,佈線的最小間距減小到約20 μ m。這些使得每個佈線層在芯片邊緣大約有20個IO/mm的密度。為了保持可負擔性,這些間距和密度預計將會緩慢增大。因此,更高的IO帶寬密度需要更多地依賴於更快的數據速率和更多的層數。
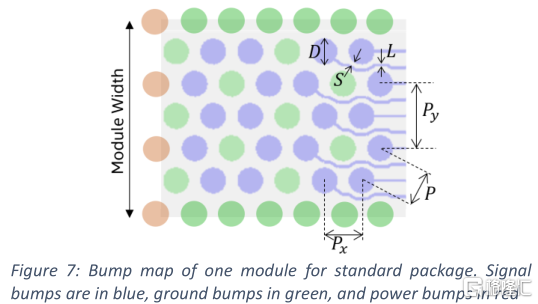
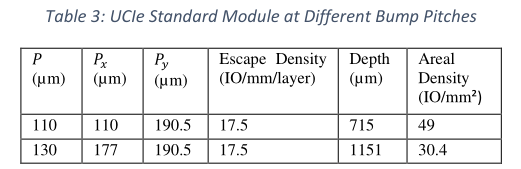
基本的UCIe-S模塊,無論是用於發射機(TX)還是接收機(RX),都由20個單向單端模式的信號組成。推薦的凸點排布如圖7所示。靠近裸芯邊緣的前10個信號在一個佈線層中避開凸點區域,而後面的其他10個信號在下一個佈線層中使用相同的佈線設計策略迴避凸點區域。模塊寬度選擇為571.5μm,因此沿裸芯邊緣的間距Py為190.5μm。根據所選的技術選項,其他尺寸的選擇是靈活的。表3列出了基於110 μ m和130 μ m最小凸距的兩種設計案例。對角線方向的間距P,深度方向的間距Px都有相應的調整。其他尺寸需要滿足以下兩個條件:
P=D+L+2S (1)
P_y=D+3L+4S (2)
其中,D是通孔焊盤直徑,L是導線寬度,S是導線周圍的間距。在571.5μm的模塊,引腳密度為17.5 IO/mm,兩個佈線層總密度為35IO/mm。
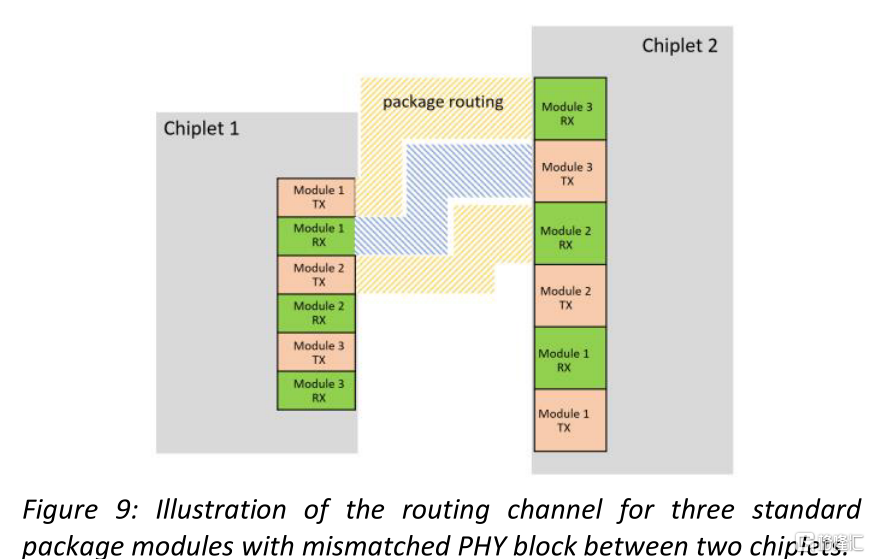
我們提出的UCIe-S模塊包括一個TX塊和一個RX塊。因此,全模組寬度為1143 μ m。引出走線的排序在TX和RX之間是對稱的,因此一個PHY設計可以用來互連所有的Chiplet。標準模塊還支持堆疊,通過4個佈線層層進一步增加引出的IO密度至70 IO/mm。這些模塊以棋盤格的形式排列(圖8)。裸芯邊緣的模塊使用兩個頂層的走線層連接,而靠後的模塊使用兩個較深的路由層連接。我們建議堅持相同的模塊寬度。如果兩個芯片之間的模塊寬度顯著不同(如圖9所示),則需要為扇入和扇出走線提供空間。這增加了通道長度,並需要較大的裸芯間距離,此時,兩個面對面的chiplet的PHY模塊過一個微小的芯片間隙互聯的方案是不可行的。

面積密度與凸點間距相關。如表3所示,較寬的間距會造成較大的凸點區域深度和較小的區域密度。封裝技術的進步一直在推動凸距變小,以增加面積密度。減少接地凸起也增加了區域密度。圖7中的凸點排布具有良好的接地隔離性,以確保通過深層封裝層的通道能夠滿足32GT/s的要求。然而,如果目標數據速率較低,或如果不進行模塊堆疊,且通空堆疊高度較低的話,則可以減少接地凸點以節省硅面積。這樣就可以靈活地適應帶寬密度、硅面積和包層數量之間的不同權衡。
D.先進裝通道設計
在過去的十年中,出現了新的先進的封裝架構,實現了封裝特徵尺寸[8]的大幅減小。為了充分利用這些先進技術的能力,我們定義了一個單獨的UCIe-A模塊來支持表1中的性能目標。與標準模塊類似,先進模塊支持多種封裝技術。該模塊的建議邊緣寬度對於獨立開發的芯片之間的互操作性至關重要。我們有內置的修復宂餘,這對實現良好的封裝良率至關重要。
工業上先進的封裝技術使凸點間距小於55 μ m,並將佈線間距改善到幾微米。其中許多技術都利用了硅製造能力。小通孔尺寸和良好的通孔排列使通孔能被走線所包圍。這為信號層間傳遞和交換佈線順序創造了高度靈活性。這與標準封裝的解決方案有很大的不同。
圖7中標準模塊的凸點排布並不適用於先進封裝技術。它強制採用16位集羣設計,並需要堆疊至少10個模塊,才能充分利用先進封裝的佈線密度。相應片上數據進出這些模塊的路徑非常複雜,阻礙了PHY的模塊化設計。它也不包含先進封裝所要求的用於修復的宂餘位。此外,圖8中的棋盤格模塊排列導致部分通道明顯變長,這將限制帶寬和電源效率。
因此,先進模塊被設計成不同的尺寸和外形。圖10顯示了一個基於45 μ m間距的凸點排布[4]。與標準模塊類似,它由一個TX模塊和一個RX模塊組成。TX模塊靠近裸芯邊緣,而RX模塊在後面。兩者共74個信號,其中數據通道64個,overhead信號10個。其中一個特殊的overhead信號是用於修復的宂餘信號。先進的封裝解決方案通常涉及成千上萬個小間距的微凸點互連。先進模塊為每32個數據信號分配兩個宂餘凸點,以修復潛在的裝配故障。這是保證製造良率的必要條件。

模組寬度固定在388.8 μ m。當使用先進封裝時,兩個芯片通常放在一起,以減少信道長度,這對電源效率和收發器設計的非常關鍵。然而,如果兩個Chiplet之間的模塊寬度相差較大,扇入和扇出的連接空間就很小。這與圖9中標準封裝模塊的問題類似。由於先進封裝信道具有很強的RC特性,對信道長度非常敏感,模塊寬度不匹配會大大降低信道帶寬和功率效率。因此,固定的模塊寬度是芯片互操作的基礎。
45μm間距凸點共10列,模塊寬度388.8 μ m,如圖10所示。沿裸芯邊緣的凸距為77.76 μ m,在深度方向和對角線方向的凸距均約為45 μ m。這遵循六邊形模式,最大化了凸點密度。對於更緊密的凸點密度,可以調整列和行的數量,以實現最大的凸點密度。例如,如果封裝工藝支持25 μ m的最小凸距,則可以將列數增加到18個,沿裸芯邊緣的凸距減小到43.2 μ m,使模塊寬度保持在388.8 μ m。沿深度和對角線方向的間距約為25 μ m。這也遵循一個六邊形的模式。
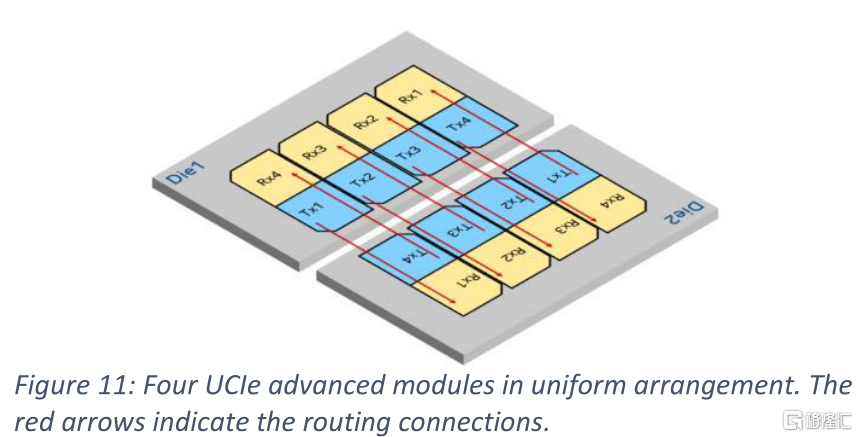
對於先進模塊,裸芯邊緣的引出IO密度約為400 IO/mm。面積密度隨凸距的增大而增大。在45 μ m間距時,凸點深度約為1 mm,因此面積密度約為400 IO/mm²。面積密度與凸距的平方呈反比關係,可以隨凸距減小而進一步增大。先進的封裝裝有通孔和導線的精細設計規則,因此凸點引出的限制比有機封裝少得多。TX和RX模塊可以沿裸芯邊緣均勻排列,而不是棋盤格圖案。如圖11所示,所有的TX模塊都可以放在模具邊緣,而所有的RX模塊都在它們的後面。這樣做有兩個優點:首先,它只需要單一的TX和RX塊設計,因此簡化了電路設計。第二,雙向的導線長度相同。換句話説,它減少了最壞情況下的走線長度。這大大提高了這些有損耗通道的帶寬。
圖示所示的高級模塊的凸點排布不適用於凸間距為110 μ m的標準封裝。標準封裝模塊至少2.5毫米深,而接地屏蔽遠遠不足以滿足標準封裝中的長通孔。它將需要至少8個佈線層來分解所有的信號。
封裝通道性能結果
我們模擬了UCIe-S和UCIe-A模塊的參考通道,以驗證其電氣性能。
A.標準封裝通道性能
標準封裝通道基於如圖8所示的堆疊模塊配置。各模塊採用圖7所示的凹凸圖,凹凸間距為110 μ m。封裝基板被假設為8-2-8,這表示在兩個核心層的正面和背面都有8個堆砌層。堆疊UCIe-S模塊的導線連接需要4層佈線層,從封裝表面開始依次為第2層、第4層、第6層、第8層。最壞的通道在第8金屬層,因為它有最長的垂直通過堆疊高度和最高的串擾。
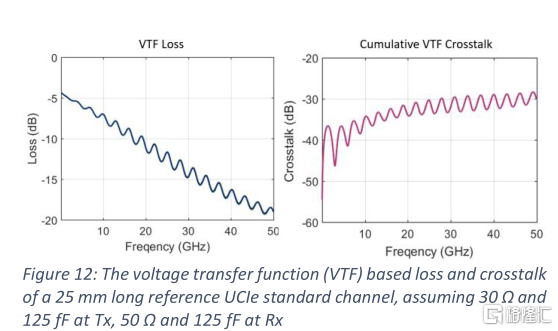
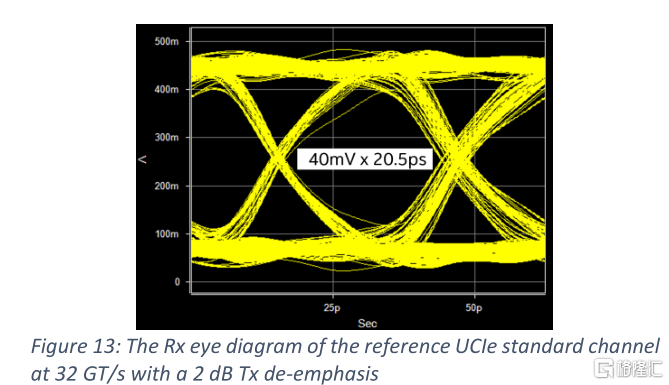
通道長度取決於兩個芯片的位置。信道越長,損耗越大,信號裕度越差。圖12繪製了一個25mm長的通道的特性。損耗和累積串擾是基於電壓傳遞函數(VTF)[4,9]而不是s參數。它將TX、RX的終端和容性負載與通道結合起來進行綜合評價。在16 GHz時,VTF損耗為-8.77 dB,累積VTF串擾為-31.3 dB。它們基於UCIe規範[4]中32gt /s標準封裝通道的TX和RX要求:TX終端30Ω,RX終端50Ω,TX和RX的等效電容均為125fF。低裸芯電容通常需要低壓靜電放電(ESD)保護,片上電感線圈,TX和RX電路負載優化。由於TX和RX的電阻終端和容性負載被納入圖12中的VTF損耗和串擾中,因此在通道特性中存在很小的反射。這些在時域仿真中可以被完全看到。在2 dB的TX去加重的情況下,32GT/s時的RX眼圖如圖13所示。根據峯值失真分析,在40 mV眼高時,最壞情況下眼寬開度大於65% UI。TX去加重有~10%的UI貢獻。除去時鐘和控制信號的開銷,整個芯片邊緣的數據帶寬密度達到了約224 GB/s/mm。
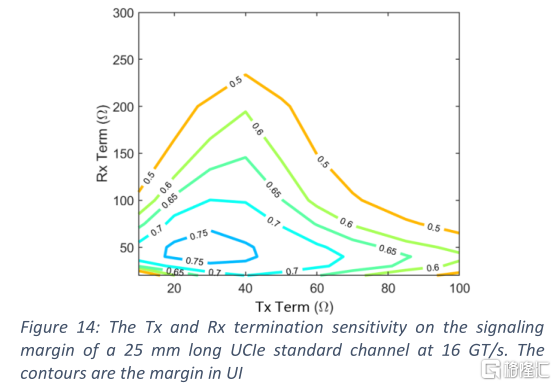
封裝內通道可分為三段:第一個裸芯上的凸點引出區域、第一個裸芯與第二個裸芯之間的導線以及第二個裸芯的凸點接入區域。芯片間的連線通常是一條50 Ω傳輸線,長度可為兩毫米到十幾毫米。凸點引出和接入的片段非常短。整個通道相對簡單。圖14顯示了16 GT/s時的裕量與圖12中參考通道的終端配置之間的關係。最佳的RX配置大約是50 Ω。這表明了50歐姆是減少RX反射的RX與通道阻抗匹配的首選。然而,TX端可以低於通道阻抗。較低的TX終端提高了進入通道的電壓等級,增加了RX電壓擺幅和信號裕度。然而,在TX端較大的不匹配將導致不必要的反射。因此,最佳的TX設置大約是30 Ω。對電阻終端的靈敏度不會受到TX去加重、電容負載或數據速率的明顯影響。對於較低數據速率和較短路徑的應用,可以對終端進行調整,換取更大的信號裕度和更好的能效。
B.先進封裝通道性能
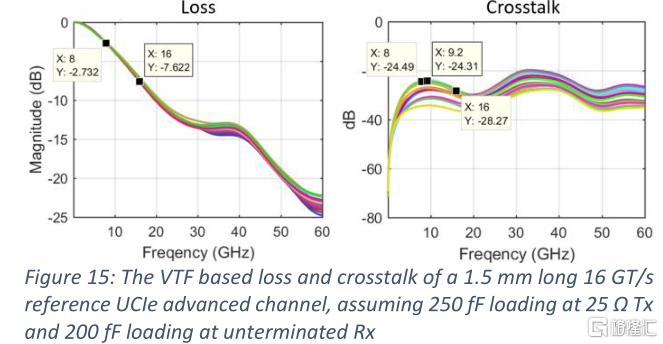
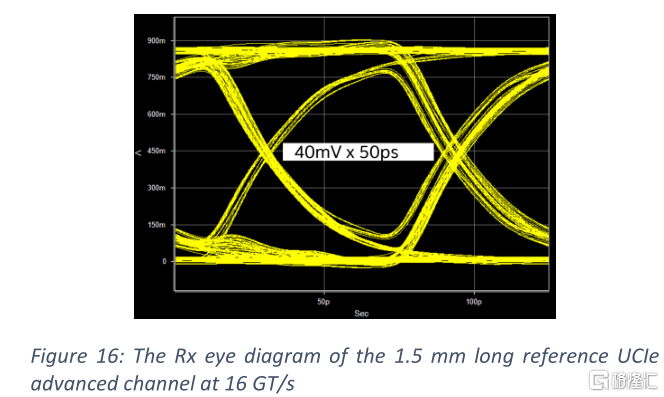
一個參考先進封裝通道被放在一起來驗證UCIe-A模塊的性能。凸點引出和佈線是需要優化的物理通道的兩個關鍵組件。凸點-通孔串擾對接地屏蔽的位置高度敏感。因此,屏蔽凸點的最佳位置需要在硅面積和串擾等級之間進行權衡。金屬堆疊對線路性能影響很大。這是互連技術開發的一個關鍵領域,用於優化通道範圍、路由密度和帶寬。參考通道是基於圖10中的45 μ m間距凸點排布。基於1µm的最小寬度和間距設計規則進行路徑設計。相反方向的信號被分成兩個路由層,中間以一個地面參考層隔開。通道長度假設為1.5 mm。圖15中疊加了20個信號的VTF損耗和累積串擾。最壞情況下VTF損耗在8 GHz時為-2.73 dB。最壞情況下累積VTF串擾在8 GHz時為-24.3 dB。VTF指標是基於UCIe規範[4]中16GT/s先進封裝通道的TX和RX要求: 25ΩTX上有250ff電容負載在以及在無端接的RX上有200 fF電容負載。由於難以在間距很小的凸點範圍內安裝片上電感器,因此先進封裝的電容負載更高。在16GT /s時對應的RX眼圖如圖16所示。無端RX增加了電壓波動。由於低損耗和低串擾達到奈奎斯特頻率,眼睛是廣泛打開的。根據峯值失真分析,在不使用任何均衡電路的情況下,在40mv眼高處,最壞情況下眼寬開度大於80% UI。這使得除開銷信號外,以16GT/s速率跨越整個裸芯邊緣的帶寬密度約為658 GB/s/mm。這已經是32 GT/s標準模塊的三倍。在相同的數據傳輸速率下,先進模塊的帶寬密度是標準模塊的6倍。先進的封裝技術正在迅速發展。設計特徵尺寸不斷縮小,層數不斷增加。這些技術的進步將繼續減少信道損耗和串擾,以支持更高的數據速率,如32 GT/s。
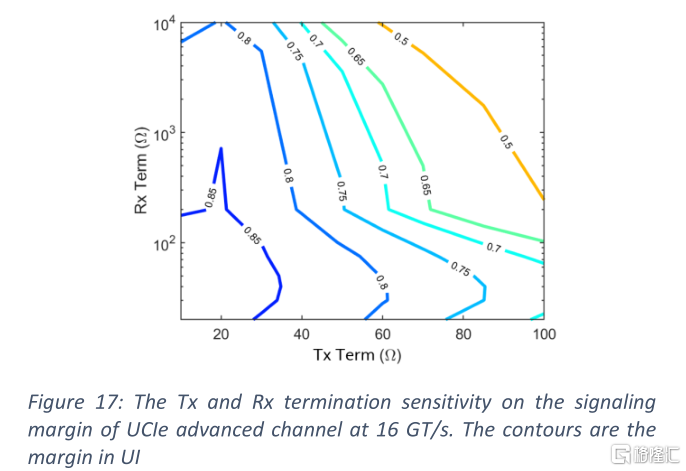
由於先進封裝通道非常短,它對TX和RX終端的靈敏度與標準通道不同。圖17顯示了在16gt /s時的裕度與TX和RX終端配置之間的關係。它傾向於較強的TX,對RX終端未表現出顯著的敏感性。因此,我們設置UCIe-A TX終端電阻為25Ω,RX不端接。這樣可以最大化信道裕度,簡化RX設計,降低功耗。
結論
該行業需要一個開放的芯片生態系統,它將會為計算機領域帶來革新。我們使用UCIe 1.0規範的方法提供了引人注目的電源效率和成本效益,並在前期解決了即插即用和規範性問題。我們預計下一代的創新將發生在Chiplet級別,允許提供不同功能的芯片組合供客户選擇,以最佳地滿足其應用程序需求。
未來,我們將對時鐘結構和相應的功率噪聲對信號裕度的影響進行更多的靈敏度研究。隨着凸點間距的不斷縮小和3D封裝集成成為主流,我們期待有更多創新帶來更節能、更經濟的解決方案。從延遲、帶寬和能效的角度來看,這些可能需要更寬的鏈路以更慢的速度運行,並更接近於片上連接。在未來的幾十年裏,封裝和半導體制造技術的進步將徹底改變計算領域。UCIe做好了充分準備,在生態系統中的不斷創新,以充分利用這些技術進步。



實體店
地址:
港鐵落馬洲站3樓入閘區大堂307號鋪
營業時間:
星期一至六: 9:00 am - 9:00 pm
星期日及公衆假期:10:00 am - 6:00 pm






