






本文來自格隆匯專欄:半導體行業觀察 作者: 杜芹DQ
最近來自數據中心三大廠商英特爾、英偉達和AMD三大半導體廠商的消息頗多,無論是AMD收購賽靈思,還是英特爾最近透露的Falcon Shores,再加上去年英偉達所推出的Grace CPU,CPU廠商開始研究GPU、GPU廠商開始研發CPU,這些動作無不是釋放一個明顯的信號,芯片行業正在向異構架構整合發展。而部分國內廠商也嗅到了這個先機,開始往多架構產品線佈局。異構計算,要全面爆發了嗎?
三大廠商引領異構計算
異構計算(英語:Heterogeneouscomputing),又稱為異質運算,早在80年代中期就產生了,其主要是指使用不同類型指令集和體系架構的計算單元組成系統的計算方式。常見的計算單元類別包括CPU、GPU、DSP、ASIC、FPGA等。目前“CPU+GPU”以及“CPU+FPGA”都是受業界關注的異構計算平台。
現在隨着5G、AI、雲計算等新興領域對計算量的需求,已經超過了通用CPU的發展速度,僅通過提升CPU時鐘頻率和內核數量而提高計算能力的傳統方式遇到了散熱和能耗瓶頸,所以需要GPU、FPGA、DSP,現在還多了DPU,這些計算單元去配合CPU進行並行計算,大家分工協作,“專人幹專事”,以此來很好的滿足這些計算需求。
而英特爾、AMD、英偉達三大廠商最近的一些列集中的動作更是把異構計算推上了風口浪尖:
英特爾CPU+GPU新架構Falcon Shores
英特爾在最近的投資者會議中提出了一個新架構——Falcon Shores。這是一款將X86和Xe GPU 整合到一個Xeon插槽中的新架構。該架構將利用英特爾埃米時代工藝技術、下一代封裝、英特爾正在開發的新型超帶寬共享內存以及領先的I/O技術。他們預計,相對於當前平台,Falcon Shores將提供超過5倍的每瓦性能、超過5倍的計算密度增加以及超過5倍的內存容量和帶寬提升。據路線圖所示,Falcon Shores計劃於2024年完成。

(圖源:英特爾)
目前英特爾已經有CPU、FPGA、IPU等產品線,現在也投入了運算級GPU的研發,在Intel 投資日上,英特爾談到了兩款GPU產品,分別是面向遊戲玩家的Xe-HPG架構Alchemist GPU以及面向數據中心的Xe-HPC架構GPU芯片Ponte Vecchio,後者是MCM(Multi-chip Module)/chiplet形態的GPU芯片。而且近日,AMD獨立GPU等項目的首席SoC架構師Rohit Verma也從AMD跳槽到英特爾。英特爾這次GPU的動作可以説計劃長遠、且非常大。
英偉達Grace CPU
2021年4月,英偉達公佈了其首款代號為Grace的CPU產品,這是專為人工智能和超算使用需求打造的。該產品採用下一代Arm Neoverse內核,在NVIDIA放出的設計示圖中,Grace CPU是以MCM(Multi-Chip Module,多芯片模組)形式構成,包括CPU、GPU、DPU和帶有ECC的LPDDR5x的新型高帶寬內存子系統,輔以使用 NVLink 通道技術。可以説是專為連接英偉達GPU所設計。據悉,Grace預計在2023年發佈。

英偉達的Grace視圖不是一個芯片,而是多模塊形式(圖源:英偉達)
對於英偉達來説,Grace CPU的研發將對其意義深遠,使其不必完全受制於AMD和英特爾在CPU上的的合作關係,可以説是自立自強的一個表現。因為即使GPU的並行能力不斷提高,但GPU終究在加速運算中扮演資料運算,仍需搭配CPU執行基本的系統,以及由CPU 發號運算的命令,所以GPU和CPU之間的溝通很重要。而x86架構的CPU又受限PCIe頻寬的影響,GPU與CPU之間溝通效率很低,無法滿足巨量數據傳輸處理效率需求,此前英偉達為了解決這個問題,研發了高速通道技術NVLink,但合作伙伴只有較冷門的IBM Power,而市場佔有率較大的英特爾和AMD都有自身的加速器,自然也不會加入英偉達的支援陣列。
所以英偉達只能另起爐灶,踏上自研CPU之路,藉由Arm架構的特性,Grace可讓GPU直接存取系統存儲資源,讓CPU更好的處理其他工作。未來或許能看見更多Arm架構CPU搭配NVIDIA GPU的組合應用。此舉也昭示了將Arm架構應用在AI運算及超算領域確實有其發展機會,同時或將吸引更多伺服器業者開始進行Arm佈局,擴大Arm架構在手機、嵌入式以外的應用。
AMD收購賽靈思,補齊FPGA產品線
近日AMD完成了對賽靈思的收購,AMD的CPU和賽靈思的FPGA,未來也將走向CPU+FPGA的異構整合中。因為,這條路英特爾已經趟過,收購了Altera之後,FPGA產品線在英特爾中發揮的不錯,2018 年,英特爾宣佈將“Skylake”至強SP處理器 Arria 10 FPGA 混合在一個封裝中的產品。FPGA在現成CPU 上運行的編程語言和用於實現某些功能或軟件堆棧的定製ASIC之間的邊界仍然具有吸引力。
總之,收購賽靈思之後,AMD 設計的每個計算設備,無論是單芯片還是封裝中的Chiplet集合,都可以在 AMD 認為合適的時候添加一些可編程邏輯。
英特爾向GPU擴展的動作很大,英偉達研究CPU自立自強的決心也很大,氣勢正旺的AMD有了FPGA也如虎添翼。隨着三大廠商逐漸補齊產品線,異構計算或將進入全面爆發。未來,異構計算會越來越多的取代原來通用計算不擅長的部分。
國內芯片廠商跟進
不同於國際大廠在各方面實力雄厚,國內廠商難以在短時間內形成如此全的產品線,但是國產芯片廠商現在已經漸漸開始選擇通過投資和合作的方式埋下異構的種子。
2021年11月,GPU芯片企業壁仞科技,與IDG資本、字節跳動等共同參與了國產DPU初創企業雲脈芯聯數億元的天使輪投資。據壁仞科技創始人、董事長、CEO張文透露,除了DPU之外,從佈局整體計算產業出發,壁仞科技正在密切關注國產CPU的最新發展,未來形成CPU+GPU+DPU的全國產系統級解決方案。
日前,DPU芯片廠商雲豹智能與AI芯片廠商燧原科技達成了戰略合作,共同研發和提供大規模高性能AI算力平台解決方案。基於雲豹智能雲霄DPU和燧原科技雲燧T20率先推出了DataDirectPathStorage解決方案,為AI訓練儲存訪問提供更高效的解決方案。在傳統解決方案中,雲燧T20訪問存儲時,需要將數據先搬移到系統內存,再由系統內存搬移到目標設備。而基於DataDirectPath Storage技術,雲燧T20可通過DPU直接獲得數據,從而繞過系統內存和CPU,讓數據訪問速度更快,訪問延遲更短,系統開銷更小。
此外,國內還有異構處理器IP提供商華夏芯,通過自主設計的Unity統一指令集架構和基於此架構的CPU、DSP、GPU、AI專用處理器系列IP與SoC,在提升性能價格比的同時,顯著降低計算芯片研發成本和研發複雜度,同時縮短研發週期,減少開發人員工作量和降低開發門檻。據悉,華夏芯的Unity和英特爾的OneAPI都是為了簡化編程環境,但不同的是,OneAPI是面向不同體系架構的統一編程環境,Unity是面向不同微架構的統一體系架構和統一編程環境。
晶圓廠和封裝廠在異構集成上的佈局
異構計算的強大隻有完備的通用計算芯片產品線還不夠,還必須要有先進的異構集成封裝技術將其巧妙的封裝在一起,才能達到最終提升算力的目的。因此,這幾年異構集成也重新定義了封裝在芯片產業鏈中的地位,現在封裝起到一個重新架構的作用。

異構集成將是延長摩爾定律的第4波浪潮
(圖源:ERI summit 2020)
過去,考慮到功耗、性能、成本等因素的影響,芯片的集成首先在單片上進行,例如SoC。但現在摩爾定律逐漸來到極限,在單片上繼續微縮,成本效益越發不受控制。而得益於近十年來先進封裝與芯片堆疊技術的發展,例如3D堆疊、SiP等,也使得異構集成成為了大幅存在可能。下圖顯示了先進芯片封裝技術的趨勢。

先進多芯片(let)封裝技術的演進
(圖源:Cadence)
異構集成主要是將多個不同工藝節點的芯片封裝到一個封裝內部,這些芯片可以是不同種類、不同製造商、甚至是不同材料(Si/SiC/GaN)、不同工藝節點(如7nm和28nm等搭配),以此來達到增強功能和提高性能。新的封裝技術能夠將來自不同製造工藝流程的小芯片集成到具有多種功能的單個封裝中。
為此,無論是台積電、三星和英特爾這樣的晶圓大廠,還是封裝廠,都在積極佈局異構集成,在半導體後道技術上做好集成的工作。先進封裝逐漸成為集成電路芯片成品製造產業的關鍵工藝技術之一。
三大晶圓廠發力3D先進封裝
目前英特爾、三星電子與台積電已具備成熟的2.5D封裝經驗,如較為人熟知的台積電的CoWos,三星的I-Cube。接下來重點看下3D封裝,因為3D封裝可以説將異構集成發揮的淋漓盡致。
在3D封裝部分,英特爾已量產Foveros技術,其是使用異構堆疊邏輯處理運算,可以把各個邏輯芯片堆疊一起。以往堆疊僅用於存儲,現在首度把芯片堆疊從傳統的被動硅中介層與堆疊記憶體,擴展到高效能邏輯產品,如CPU、GPU與AI 處理器等。此外,英特爾還研發了三項助於Foveros的技術,分別為Co-EMIB、ODI和MDIO,其中,Co-EMIB 能連接更高的運算性能和能力,並能夠讓兩個或多個Foveros元件互連,設計人員還能夠以非常高的頻寬和非常低的功耗連接模擬器、存儲器和其他模組。ODI技術則為封裝中小芯片之間的全方位互連通訊提供了更大的靈活性。頂部芯片可以像EMIB 技術一樣與其他小芯片進行通訊,同時還可以像Foveros 技術一樣,通過硅通孔(TSV)與下面的底部裸片進行垂直通訊。
近日,英特爾為Aurora 超級計算機提供動力的處理器 Ponte Vecchio,就是一個結合了多個計算、緩存、網絡和內存硅片或“小芯片”的封裝。封裝中的每塊tile都是使用不同的工藝技術製成的,這可以説是異構集成的一個鮮明例子。該處理器就使用了Foveros的3D堆疊封裝技術和Co-EMIB連接技術。
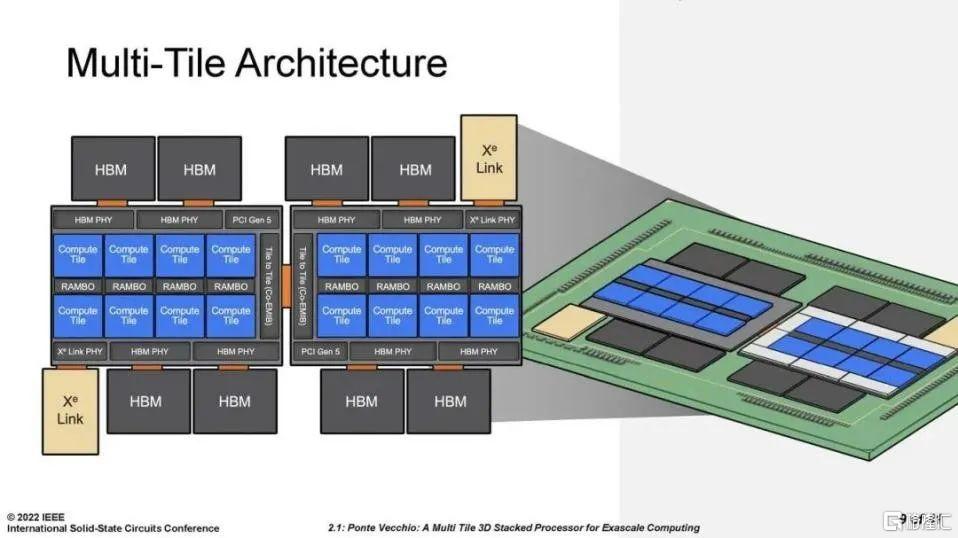
Ponte Vecchio由使用3D和 2D技術連接的多個計算、緩存、I/O 和內存塊組成。資料來源:英特爾公司。
三星的3D封裝技術是X-Cube,其與英特爾的Foveros 3D堆疊技術路線大致相同。目前三星已經完成了3D堆疊SRAM的驗證,此外,三星也提供了一項差異化技術,ISC(集成堆疊電容),這一電容應用了已經在三星DRAM產品中獲得驗證的硅電容結構、材料和工藝,具有1100nF/mm2的電容密度,可以有效提高電源完整性。三星的ISC還提供了多種不同的配置,比如分立型、硅中介層型和多晶圓堆疊型,以滿足客户不同的結構需求,ISC預計將在2022年進入量產階段。
台積電提出了3D多芯片與系統整合芯片(SoIC)的整合方案。SoIC是將不同尺寸、製程技術,以及材料的已知良好裸片直接堆疊在一起。台積電表示,相較於傳統使用微凸塊的3D集成電路解決方案,SoIC的凸塊密度與速度高出數倍,同時大幅減少功耗。此外,台積電也推出了3D Fabric,3DFabric能協助客户將多個邏輯芯片,甚至串聯高頻寬記憶體(HBM)或異構小芯片,例如模擬、I/O,以及射頻模組連結在一起,聯合3D SoIC技術能提供更好的靈活性,透過穩固的芯片互連打造出強大的系統。
從上述三大廠商在3D封裝的研究也可以看出,三家都各自提供了異構設計的方法和工具,來幫助設計者克服多出來的接口IP或者潛在的功耗增加,以及多芯片互聯的問題等等。
封裝廠在先進封裝上的努力
在異構集成的大勢之下,封裝廠的作用自然也是重要的一環。在封裝領域,我國可謂發展較早,實力相對較強。而系統級封裝(System inPackage, SiP)能實現高度集成的微型化系統,整合各種感測器與多樣功能的芯片(例如MCU、存儲器)等在終端產品之微小空間中,是未來穿戴裝置主流封裝技術。因此,各家封裝廠也在SiP封裝上大力佈局。
首先是在SiP封裝佈局已有10年之久的日月光、拿下了蘋果的訂單後,日月光今年將進入收割元年,而且日月光今年將SiP列為營收中的單獨要項。法人表示,日月光SiP目前應用以Wi-Fi整合芯片及指紋辨識芯片為主,產能利用率達滿載。預估2022年SiP營收佔日月光整體營收比重將達20%以上。
安靠(Amkor)基於襯底的SiP技術在其韓國ATK4光州的最大批量製造工廠應用。去年11月底,據報道,Amkor計劃在越南Bac Ninh建立最先進的智能工廠,新工廠的第一階段將專注於系統級封裝 (SiP) 組裝和測試解決方案。據Amkor透露,一期建設預計將於 2022 年開始,根據預計的客户產品週期,預計將於 2023 年下半年開始大批量生產。
大陸的封裝企業,尤其是中國封測三強(長電、通富、華天)近幾年通過自主研發和兼併收購,正在快速積累先進封裝技術。例如長電科技旗下長電韓國積極佈局高階SiP封裝業務,切入手機和穿戴式裝置等終端產品;2016年收購了AMD兩家專門從事封裝及測試業務子公司的通富微電,也在做SiP的產品,而且公司2021年上半年2.5D/3D封裝產品技術已完成立項。
上述這些封裝企業主要是針對年產量在10KK左右的SiP封裝需求,但除此之外,還有一些專注於細分領域(如工業和醫療等)的異質集成SiP封裝廠商,如摩爾精英等,他們主要是解決市場上多樣化、小批量的產品設計生產需求。據瞭解,摩爾精英已經在惠山經濟開發區建立自有SiP工廠,所面向的客户主要為年產量1kk左右的產品,摩爾精英SiP一站式服務提供從電路圖設計到量產的各個環節。
不過綜合來看,IDM與晶圓代工廠商在2.5D、3D等封裝技術的發展相對委外半導體封測(OSAT)業者成熟、完整,也具有多年量產經驗,所以專業封測廠商不僅要與同業競爭,也要與晶圓代工廠一起競爭。
結語
來到2022年,異構計算大戰,一觸即發。芯片廠商不遺餘力的佈局CPU、GPU、FPGA、DPU等計算芯片,放出你爭我趕的時間軸,代工廠和封裝廠也在鉚足勁向異構計算的先進封裝佈局,不止這些廠商,EDA廠商、半導體設備廠商、材料廠商、測試企業等都在為異構計算的來臨做準備,異構計算的發展需要全產業鏈的共同協作,各產業鏈成熟起來,才能真正迎來大爆發。








