






本文來自格隆匯專欄:半導體行業觀察,作者:杜芹
Chiplet被認為是後摩爾時代繼續提升芯片規模和密度的重要技術。其化整為零的理念對於架構、互聯、封裝都帶來了新的機遇和挑戰。在近日召開的第十八屆中國計算機大會(CNCC2021)上,Chiplet關鍵技術論壇上來自工業界和學術界的學者、專家圍繞“如何構建片上超算”這一設想,一起探討了Chiplet能為芯片設計帶來哪些變革性技術。
“Chiplet互聯標準有沒有意義?如何推進互聯標準?是否有能支持數十上百Chiplet集成方案?如何看待有源硅基板?Chiplet為體系架構帶來什麼變化?”等一系列問題在論壇上得到了激烈的討論和回答。
Chiplet是下一代芯片的重要設計與製造方法
中科院計算所副研究員王鬱傑首先作了開場白,他指出,當下,Chiplet已是下一代芯片的重要設計與製造方法。業界大企業如英特爾、AMD和台積電等都在採用Chiplet的設計方法。Chiplet突破了SoC的四大設計極限:它突破了光罩面積的規模極限,通過異質集成的方式突破了功能極限,使其不再受多工藝的約束,通過算力可擴展的方式提升了芯片的性能,並通過敏捷開發的方式大大縮短了工期極限。
中科院計算所目前正在就多Chiplet處理器進行研究,他們主要圍繞着三大問題展開,一是怎麼算?多芯片並行體系的機構應該怎麼設計,包括系統級設計的片間如何劃分,片間的任務如何映射到Chiplet上。第二個問題是怎麼連?多Chiplet高效互聯將採用哪種方法,接口與協議怎麼選擇等。三是怎麼合?怎麼把多個Chiplet封裝起來,在合的過程中還要解決散熱問題。
Chiplet熱管理技術如何解決?
中科院微電子所王啟東研究員介紹了《異質集成及其熱管理技術》的發展狀況和應用情況。他指出,當下摩爾定律發展撞牆,More than Moore是中國集成電路的新機遇,掌握先進的系統級封裝技術是實現技術超越的良機。在這其中Chiplet是一個非常有潛力的技術。Chiplet其實就是多個芯粒通過先進的封裝技術形成的SiP。
Chiplet有六大好處,一個是企業可以通過常規IC工藝實現先進的性能,二是Chiplet實現了前道工藝和後道工藝的有效融合,三是減少了IP的問題,再就是產品面市的速度大大加快,還具有系統級的功能,設計更靈活且成本低。
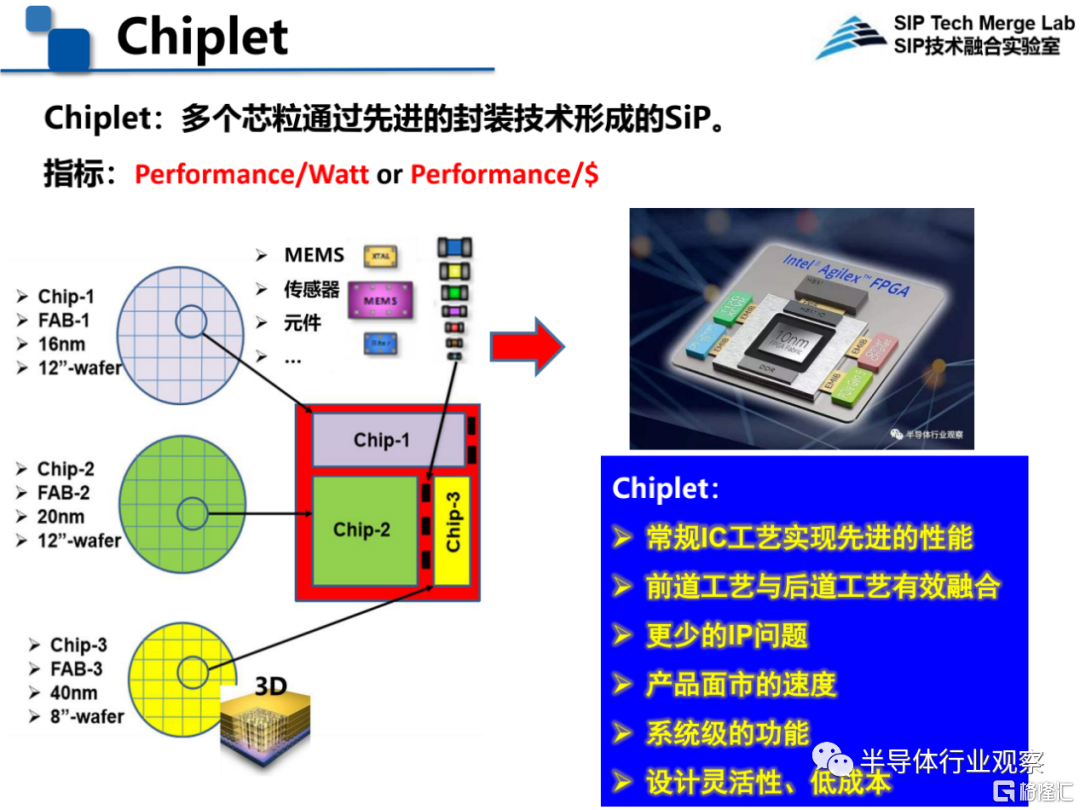
圖源:中科院微電子所王啟東在CNCC 2021上的演講
通過芯粒集成技術,Chiplet能實現“系統集成,增加功能密度,降低成本”。再加之傳遞電路與器件的創新技術,可進一步提高電子產品價值,促進產業效益與規模提升。目前芯粒的技術支撐領域也非常廣闊,包括新一代移動通信、高性能計算、自動駕駛以及物聯網等。
説到集成技術,現在如高性能計算、大數據和AI以及數據中心等社會需求驅動高性能處理芯片迅速發展,異質集成將是重要的解決方案。不過,在需求的推動與異質集成技術背景下,高性能處理芯片在散熱與熱管理方面將面臨諸多挑戰:一是封裝體內總熱功耗將顯著提升;二是芯片採用2.5D/3D堆疊,增加了垂直路徑熱阻;三是更加複雜的SiP,跨尺度與多物理場情況下熱管理設計複雜。
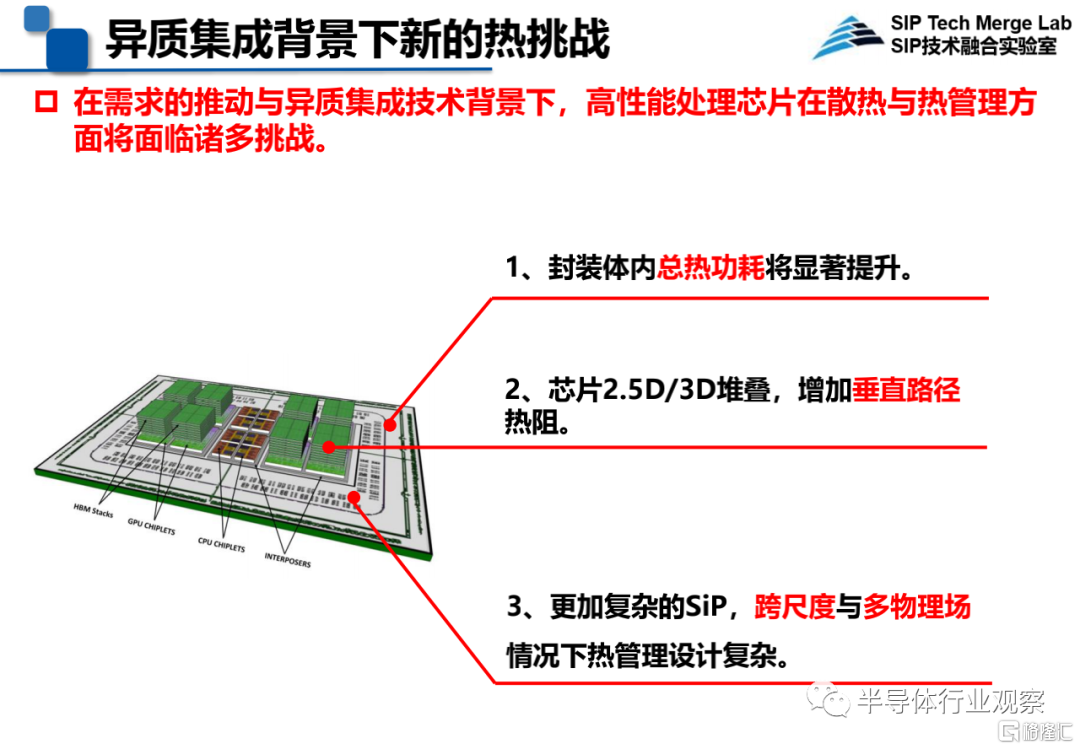
圖源:中科院微電子所王啟東在CNCC 2021上的演講
針對第一個挑戰,王啟東表示,考慮到高性能處理器芯片的封裝結構以及熱的傳遞路徑,降低向上傳遞路徑熱阻在近期是最有效方案。路徑一是增加熱界面材料性能,降低熱阻,路徑二是增加熱對流係數,降低熱沉到環境的熱阻,路徑三是縮短傳熱路徑,主要通過結構的調整去掉熱界面材料TIM。針對第一個挑戰,業界也作了不少研究,IBM採取芯片內嵌徑向微流道相變液冷的方式,增加擾流柱進一步強化冷卻;再者,通過增加3D歧管設計,可以進一步降低壓降、減小熱陽、降低温差。斯坦福則採用銅反轉蛋白石工藝製作多孔材料,使用3D歧管來進行液冷。台積電作為一個晶圓代工廠,採用fusion bonding工藝,使用氧化硅作為TIM,實現高功率冷卻。
對於挑戰二來説,針對3D堆疊,IBM採用雙面微流道液冷方案,頂面採用歧管微流道液冷板,底部採用內嵌微流道TSV轉接板的方式。DARPA也發佈了ICECOOL計劃,並提出在片間或片內嵌入微流道的方案解決3D堆疊的冷卻。此外,佐治亞理工採用片內嵌入微擾流柱,片間使用焊環的連接工藝實現3D片內液冷。3D片內液冷主要需要解決片間連接、片內流道密封的問題。
針對挑戰三,主要是在異質集成下,模型尺寸從晶體管級到板級存在數個數量級的跨越,存在建模與網格劃分等諸多困難。同時,更多功能的融合,設計過程中需要考慮的物理場及其相互之間的耦合作用對產品開發將非常重要。當下商業仿真軟件,針對三個及以上的物理場的耦合仿真存在很大困難。所以就需要進行跨尺度與多物理的建模與仿真的研究。
王啟東總結道,對於未來散熱和熱管理技術,需要從材料、結構、工藝和應用多個領域來逐個擊破。總之,現在誰能把大功率高熱點問題解決,誰能用低成本或者更簡單的方案實現,誰就能在業界佔據有利地位。

圖源:中科院微電子所王啟東在CNCC 2021上的演講
從產業規模來看,不計入快速出現的新技術,僅從目前技術來看,先進封裝市場會有年8%的複合增長,Yole諮詢預計,到2024年將達到450億美元的規模。目前王啟東團隊所在的系統封裝與集成研發中心是中國科學院微電子研究所的骨千科研部門之一,主要從事先進電子封裝與集成技術的研究與開發,該封裝中心團隊也是國內最早、最全面進行系統級封裝技術聯合研究的團隊。目前其產業化項目也在無錫落地,成立了華進半導體,他們也不斷在先進封裝領域進行探索。
面向芯片級光模塊的硅基集成芯片
中科院半導體研究所的祁楠發表了主題為《面向芯片級光模塊的硅基集成芯片》的演講,他首先講到,當下光互連正在往更短距離、更高密度的方向上發展,逐漸在板上芯片間和芯片上進行互連。其需要解決的問題無外乎也是帶寬密度和能耗效率,集成化將是一大有效解決方案。從光通信本身來看,其也在經歷從分立器件向集成化發展的趨勢,以交換機為例,它正從以前的插拔式過渡到光電合封(CPO)的模式,英特爾和博通等公司也展示了相關的原型產品。其基本思路是把之前需要進行背板傳輸的長距離的電線或者銅線改成光纖互聯。無數研究都證明了基於光的互聯成為可能。
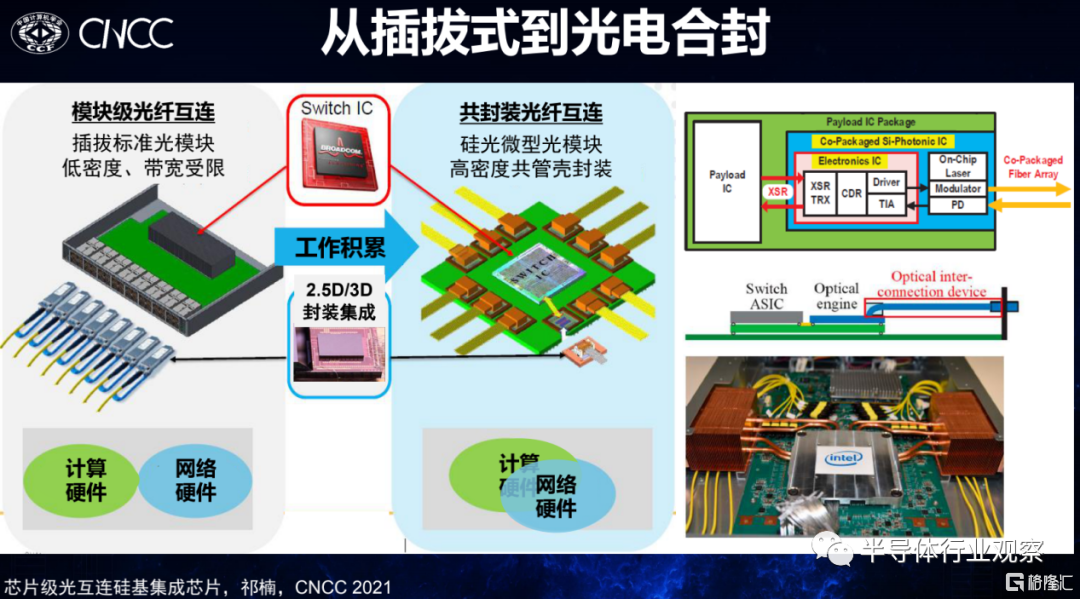
圖源:中科院半導體研究所祁楠在CNCC 2021上的演講
那麼,光電集成化的優勢什麼呢?一個是電光轉換靠近Switch,節省了re-timer,降低約75%功耗,而且Switch總帶寬方便,整倍數放縮;第二採用芯片級器件集成,它利用快速更迭的CMOS工藝,預計能降低80%的封裝成本。而光電互相轉換的終極目標是單片集成,目前業界也在為之進行探索和努力。
當實現了一個小型的光電引擎之後,它能夠用在哪些領域呢?祁楠介紹到,主要是用在通過以太網的互聯、智能網卡、以及高性能的計算領域。例如,微軟對光互連進行了預算,惠普的服務器也在規劃用光互連的交互來提高運行效率。
要實現芯片級的光互連,在發射端針對不同的傳輸距離則需要不同的驅動方案。當芯片與芯片板間或板上的傳輸距離小於100m的話,通常低成本的方案是採用激光器直驅DML方案。但當傳輸距離較遠,超過100米甚至幾公里的話,則要採用調製器間接驅動的方案。兩種傳輸要求的接收端大體是一致的。而如果想實現小尺寸、高密度的集成,則可能需要做Chiplet的光電互聯引擎。
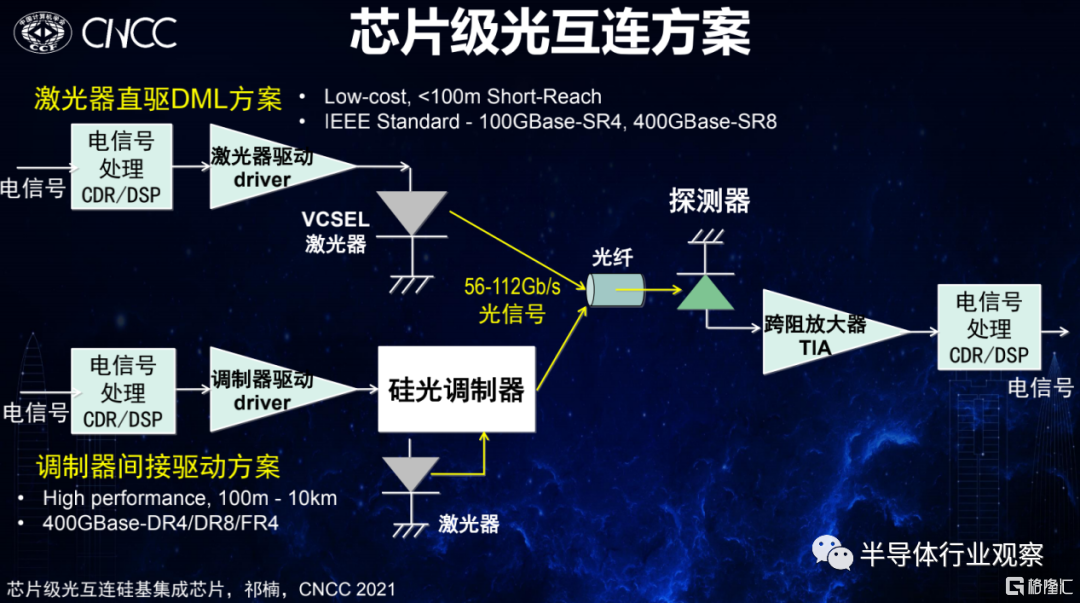
圖源:中科院半導體研究所祁楠在CNCC 2021上的演講
祁楠闡述道,新型的光電合封(CPO)需要高速率、低功耗和高集成度的光芯片和電芯片。在這其中,CMOS親善的方案就變得很重要,表現為需要的電壓擺幅要足夠低,來適應深亞微米的需求,功耗和尺寸都不能太大。因此進行新型的硅光器件時,就需要協同設計的CMOS驅動、CMOS TIA,甚至是基於這些CMOS與Serdes進行片上集成的功能完整的芯片。祁楠的課題組從2015年就開始圍繞着這些方向進行努力,從最初的25G單路一直髮展到目前的112G單路,未來希望向單路200G推進,同時希望在超算領域能夠不注重單速率,而是注重於並行速率和能耗效率,實現一個更高總帶寬的、更低能耗的光電收發引擎。
國內在Chiplet IP的發展情況
芯動科技技術總監高專介紹了公司為各種高性能計算場景而生的Innolink Chiplet IP技術。在介紹Chiplet IP之前,高專先闡述了下Chiplet的優勢和必要性。從半導體產業角度來看,Chiplet是延續犘爾定理的必然選擇。而對CPU/GPU等芯片廠商來説,Chiplet可以提高良率、降低成本、縮短開發週期和難度、突破die size上限。對於芯片系統集成商來説,不同芯片自由組合帶來的開放繁榮。對於芯片製造商foundry來説,Chiplet可以實現不同工藝組合,吸引更多高端工藝的客户,還可發展die集成業務。
但是Chiplet也有些難點,很明顯的一個問題是接口標準問題。在這方面,國外巨頭實力雄厚,大都採用私有接口標準,要想制定私有標準則需要足夠的銷量,core die和lO die必須都能自主設計。在CPU/GPU/高性能計算的細分領域,Chiplet的國產化標準是一個很有潛力的方向,國內CPU/GPU需要聯合作戰,構建自主的Chiplet技術。統一CPU Chiplet標準,其帶來的好處將是,不影響各CPU廠商的架構,不限制CPU性能,不影響CPU生態。中國急需自己的Chiplet技術。
高專接着分析了Chiplet接口的特點,他表示,與傳統接口技術相比,傳統芯片的管腳有限,而且每個管腳佔用的die面積很大,所以提高每個管腳的速度非常重要,而Chiplet接口,IO面積小、密度高,更看重的是單位面積的帶寬。
芯動科技一直在接口IP領域深耕,是連續11年市場領先的中國接口IP和芯片定製企業,具有豐富的FinFET量產經驗。在Chiplet接口IP領域,芯動科技提供多版本的INNOLINK Chiplet接口IP可以為多種場景的Chiplet提供接口解決方案,包括INNOLINK A/B/C,並提供兩種購買方式,一種是客户只買PHY,另一種是PHY+Controller。除此之外,芯動科技還提供定製IO芯片架構,能靈活搭配不同的CPU die,快速實現完整的core+IO的解決方案。目前芯動科技已有百萬片晶圓授權,涵蓋全球主流代工廠(台積電/三星/格芯/中芯國際/聯華電子/英特爾等),能提供從55nm到5nm工藝全套高速IP核和ASIC定製解決方案全覆蓋的Chiplet接口。
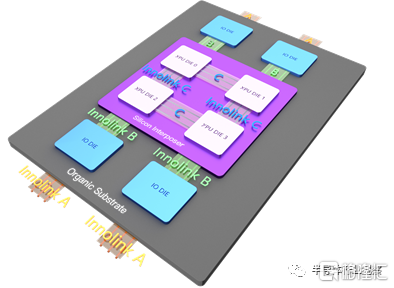
圖源:芯動科技
多芯粒集成的存算一體電路與系統
復旦大學陳遲曉發表了《多芯粒集成的存算一體電路與系統》的主題報吿。他首先提出疑問,當下為什麼很多AI計算體系結構中不可避免的出現了Chiplet架構?大的背景就是,人工智能的算法發展速度太快,AI芯片每3.4個月算力就提升一倍,這遠遠超過了摩爾定律的算力。功耗牆和存儲牆的問題接踵而來,存算一體技術成為業界發力的一大方向,而Chiplet也成為必須要走的一條新的道路。
為什麼單片的SoC不再適用?陳遲曉解釋道,這主要是單芯片的製造面積趨於上限,而且先進節點設計面臨低良率和高成本問題。傳統的SoC設計也不支持異質集成,PCB版級互聯有通信帶寬瓶頸,難以支持超過10Gbps的通信帶寬。於是基於存算一體的算法、電路、架構協同設計的新架構開始出現。
而現在不管國內外都在往Chiplet高性能計算方式和架構發展。2021年,較具代表性的有關Chiplet技術的企業動作有,英特爾的Ponte Veccho架構,AMD在今年提出了3D V-Cache Stacking架構,英偉達的Ampere GPU 架構,以及特斯拉Dojo晶圓級超算,寒武紀思元290。
站在研究學者的角度來説,可能做不了如上述這些企業這麼大的算力,但是在存算一體的發展趨勢下,復旦大學陳遲曉的團隊開始探索多芯粒的存算一體的研究。他介紹了團隊是如何從軟件的角度做高效率的映射。他們做出了一個很有意思的推導,是不是芯片越多,就能實現更高的能效,答案是否定的。雖然芯片的能效值確實是跟芯片的數量是有關的,但是當他們累加到18個芯片之前,並沒有把效率真的提高,實際上,根據不同的任務場景需要映射不同的芯片數量,來達到性能的可擴展化。針對這些工作,陳遲曉團隊做了更完整的芯片,論文研究將發佈在2022年的ISSCC上。

圖源:復旦大學陳遲曉在CNCC 2021上的演講
Chiplet更廣闊的探索
Chiplet互聯標準有沒有意義?難點是什麼?如何推進互聯標準?
芯動科技技術總監高專表示,Chiplet互聯標準有意義,有一個好的互聯標準,多家的芯片進行互連,形成開放互連的局面。難點主要包括幾方面,一是意義和動力,企業不想受制於人,希望內部進行垂直整合;二是場景,Chiplet的互聯標準應該怎樣去定義,如果定義不好,就沒人用,要想定義的好,就需要考慮帶寬、功耗等各個性能指標,需要充分了解各個場景的需求。要推進互聯標準需要產業共同協作。
陳遲曉認為,Chiplet標準要制定很難,但沒有標準,Chiplet就很難推進。如果未來是一個開放的生態,那麼就需要一個Chiplet標準來協同,否則不管是從設計還是驗證端,都沒有辦法克服一個系統中有10家公司的產品時該怎麼辦。
王啟東的看法是,Chiplet很核心的一個應用是採用貨架式的產品,由後面的應用方案對芯片進行搭建,如果沒有相應的互聯標準,應用方將很難推動Chiplet。這方面可以參考RISC-V。難點方面,如果集中到計算的角度來看,其具有壟斷性,大企業很難把計算、存儲、路由等開放出來,但Chiplet的互聯不止這些,未來外涵將越來越大。
是否有能支持數十上百Chiplet集成方案?如何看待有源硅基板?
陳遲曉指出,上百可能沒有,但英特爾的Ponte Veccho已經可以支持數十個芯片,對於無源硅基板來説,在沒有量產之前的難點很多企業都能解決。有源硅基板不在於其能做不出來,核心在於,要做Chiplet,如何在有晶體管的芯片上做TSV是最大的問題。
王啟東表示,目前從有源硅基板上來看,還存在比較大的問題,一方面是成本的問題,要在有源硅基板上做路由實際不需要太高的節點,而相對來説,有源硅基板的尺寸較大,很多硅上的面積會被閒置;另一方面,從尺寸來看,大概是26X33的水平,如果不對版圖進行拼接的話,其尺寸還是相對較小的,單一的有源硅基板將難以支持大量的Chiplet。目前台積電正在做3-4倍 shot的硅基板,但是更多還是無源的互聯線路的拼接。
高專補充道,如果是全互聯的話,互聯的通道會很多,走線複雜,如果不是全互聯而只是附近的互聯,理論上支持數百個是可以實現的。有源硅基板目前使用者少的要原因是成本,因為有源就要有晶體管,有晶體管的話,mask的層數就會多。一般無源硅基板底下的mask層數可以很少。再一個原因是,有源硅基板本身受尺寸的限制,大約是3個26X33的面積,在這樣的面積下,走線的距離不是特別長,還不需要用有源來做中繼和信號的加強。
Chiplet為體系架構帶來什麼變化?例如存儲牆,光互聯拓撲。
王啟東指出,今年下半年AMD和台積電在做3D V-Cache,也就是以前在片上佔據大量面積的SRAM,現在拿出來,在垂直方向上與邏輯單元進行互聯。根據之前的評估,在延遲、帶寬等方面基本是2個數量級的提升。所採用的技術主要是SoIC和SoIC+,這種芯片混合鍵合技術就可以把以前從不到1w(k)/平方毫米的互聯提升到10w-100w/平方毫米的互聯級別。對於連接帶寬有巨量的提升,同時從互聯長度上來講,中間去掉了可能會造成高IC延遲的Bumping,在垂直互聯上可以縮短到亞微米級別。從物理互聯上來看,對存儲牆的帶寬和功耗等會有很大的提升。Chiplet跟工藝是密切相關的,通過一些最新工藝的引入,是可以緩解在系統上遇到的一些問題。
陳遲曉接着補充道,AMD的3D V-Cache從原理上證明當用Chiplet技術時,可以採用舊的節點和Chiplet先進的封裝,可以達到更高節點的性能。ADM有一個Demo,兩顆14nm的芯片實現了7nm的性能,也就是説,如果把SRAM放在下面大的SoC上時,下面的芯片面積會變得非常大,如果從二維變成三維,平面的面積變小,互聯的面積可能從二維的200μm/300μm,變成50μm的距離。3D IC的好處是,多了一個芯片的設計維度。
Chiplet如今已收到廣泛的業界關注,許多數據中心芯片都是小芯片技術的最佳選擇,數據中心供應商也因為Chiplet而獲益。在後摩爾時代下,Chiplet將大放異彩。








