






本文來自格隆匯專欄:半導體行業觀察 ;作者:編輯部
近日,一年一度的Hotchips正式在斯坦福大學拉開帷幕。
據瞭解,Hotchips的全稱是A Symposium on High Performance Chips,於每年八月份在斯坦福大學舉行。不同於其他行業會議以學術研究為主,HotChips是一場產業界的盛會,各大處理器公司會在每年的會上展現他們最新的產品以及在研的產品。
進入大會的第二天,我們不但看到了來自英特爾、AMD、Arm這些傳統處理器巨頭的展示,還看到了存儲雙雄三星和SK海力士的分享。此外,RISC-V服務器芯片新貴Ventana也在本屆大會上分享了公司Veyron V1的細節。
在本文中,我們綜合了這些巨頭的產品,讓大家對當前領先的處理器設計理念有所瞭解。
英特爾公佈下一代處理器細節
作為處理器領域當之無愧的巨頭,英特爾在 Hot Chips 2023上分享了其下一代 Xeon 處理器 Granite Rapids 和 Sierra Forest的細節。根據之前的資料顯示,這兩款處理器將於 2024 年推出。英特爾此前曾在其數據中透露過這款處理器中心路線圖——最近一次更新是在今年 3 月。在Hot Chips上,該公司提供了更多關於芯片及其共享平台的技術細節。
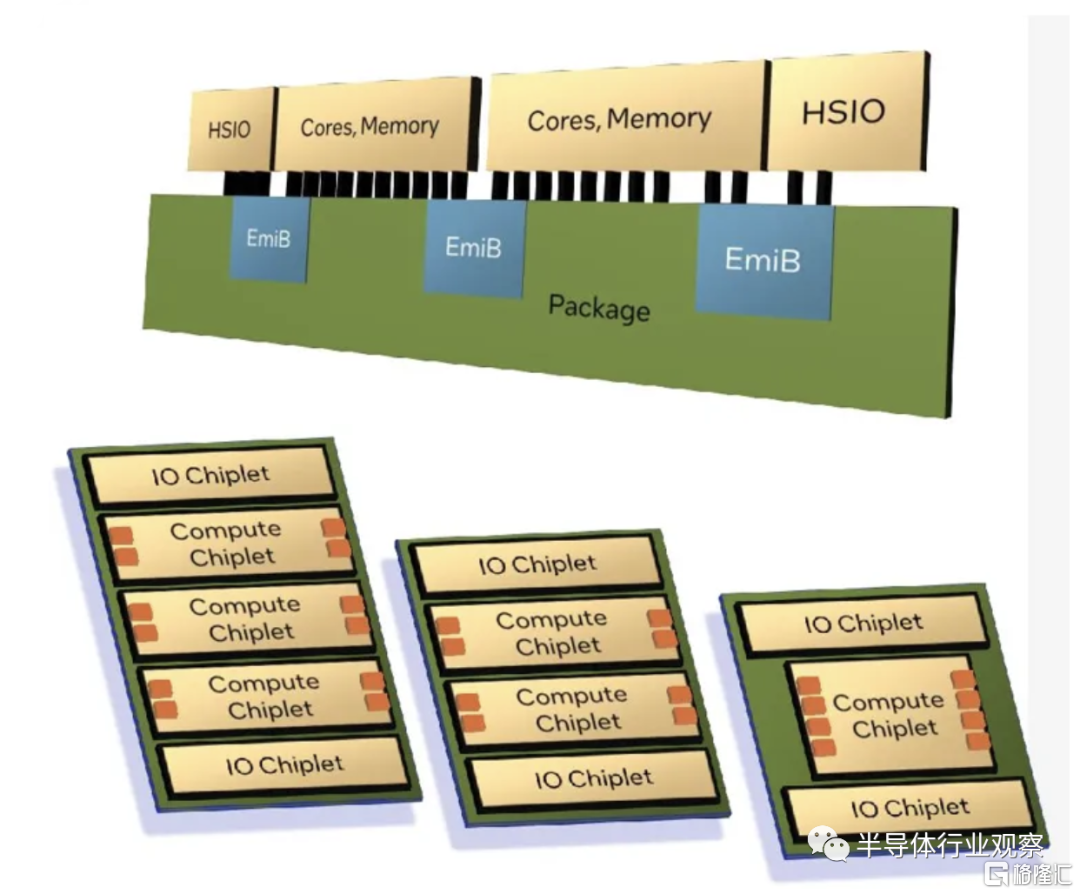
雖然英特爾至強處理器沒有“不重要”一代的説法,但由於引入了面積高效的 E 核,Granite Rapids 和 Sierra Forest 有望成為英特爾至強可擴展硬件生態系統最重要的更新之一。
自第 12代酷睿 (Alder Lake)以來,它已經成為英特爾消費處理器的中流砥柱,而即將推出的第 6代至強可擴展平台最終將把 E 核引入英特爾的服務器平台。儘管與兩種核心類型混合在單個芯片中的消費類零件不同,英特爾正在採取純粹的同質策略,為我們提供全 P 核 Granite Rapids 和全 E 核 Sierra Forest。
作為英特爾首款供數據中心使用的E核至強可擴展芯片,Sierra Forest可以説是這兩款芯片中最重要的一款。恰如其分的是,它是英特爾基於 EUV 的intel 3 工藝節點的主導產品,也是首款推出的至強處理器。據該公司稱,它仍有望在 2024 年上半年發佈。與此同時,Granite Rapids 將“很快”落後於這一點,採用相同的 Intel 3 工藝節點。

由於英特爾計劃在一代中提供兩個截然不同的 Xeon,因此第六代 Xeon 可擴展平台的一個重要因素是兩個處理器將共享相同的平台。這意味着相同的插槽、相同的內存、相同的基於小芯片的設計理念、相同的固件等。雖然仍然存在差異,特別是在 AVX-512 支持方面,但英特爾正在嘗試製造這些芯片儘可能互換。
正如英特爾宣佈的那樣,Granite 和 Sierra 都是基於小芯片的設計,依賴於計算和 I/O 小芯片的混合,這些小芯片使用英特爾的有源 EMIB 橋接技術縫合在一起。雖然這並不是英特爾在 Xeon 領域首次與小芯片共舞(XCC Sapphire Rapids 獲得了這一榮譽),但這是小芯片設計的一次獨特演變,它使用了不同的計算/IO 小芯片,而不是將其他“完整”的 Xeon 小芯片拼接在一起。除此之外,這意味着 Granite 和 Sierra 可以共享通用的 I/O 小芯片(基於 Intel 7 工藝構建),從製造的角度來看,Xeon 是 Granite 還是 Sierra “僅僅”是哪種類型的問題計算小芯片已放下。

值得注意的是,英特爾首次確認第六代至強可擴展平台正在獲得自啟動功能,使其成為真正的 SoC。由於英特爾將操作所需的所有必要 I/O 功能都放置在 I/O 小芯片中,因此不需要外部芯片組(或 FPGA)來操作這些處理器。這使得英特爾的 Xeon 系列在功能上更接近 AMD 的 EPYC 系列,AMD 的 EPYC 系列已經具有類似的自啟動功能一段時間了。
總而言之,第六代至強可擴展平台將支持多達 12 個內存通道,並可根據現有計算芯片的數量和功能進行擴展。正如英特爾之前透露的那樣,該平台將是第一個支持新的多路複用器組合列 (MCR:Multiplexer Combined Ranks) DIMM 的平台,該平台本質上是將兩組/列內存芯片組合在一起,以使進出 DIMM 的有效帶寬加倍。英特爾表示,憑藉更高的內存總線速度和更多的內存通道,該平台可以提供比當前 Sapphire Rapids Xeon 多 2.8 倍的帶寬。
至於 I/O,最大配置 Xeon 將能夠提供多達 136 個通道的通用 I/O,以及多達 6 個 UPI 鏈路(總共 144 個通道)用於多插槽連接。對於 I/O,該平台支持 PCIe 5.0(為什麼不支持 PCIe 6.0?我們被吿知時機不合適)以及更新的CXL 2.0標準。與英特爾大核 Xeon 的傳統情況一樣,Granite Rapids 芯片將能夠總共擴展到 8 個插槽。另一方面,由於正在使用的 CPU 核心數量以及英特爾對其客户的不同用例的期望,Sierra Forest 將只能擴展到 2 個插槽。
除了共享平台的詳細信息外,英特爾還首次提供了 E 核和 P 核所用架構的高級概述。正如現在多代 Xeon 的情況一樣,英特爾正在利用與其消費部件相同的基本 CPU 架構。因此,Granite 和 Sierra 可以被認為是解構的 Meteor Lake 處理器,Granite 配備 Redwood Cove P 核心,而 Sierra 配備 Crestmont E 核心。

如前所述,這是英特爾首次嘗試為 Xeon 市場提供 E 核心。對於英特爾來説,這意味着要針對數據中心工作負載調整其 E 核心設計,而不是定義上一代 E 核心設計的以消費者為中心的工作負載。
雖然沒有深入探討架構本身,但英特爾透露 Crestmont 正在提供 6 寬指令解碼路徑(instruction decode pathway)以及 8 寬 retirement backend。雖然不如英特爾的 P 核心強大,但 E 核心絕不是輕量級核心,英特爾的設計決策反映了這一點。儘管如此,它的設計在芯片空間和能耗方面都比 Granite 中的 P 核心要高效得多。
Crestmont 的 L1 指令高速緩存(I 高速緩存)將為 64KB,是早期設計中 I-cache大小的兩倍。英特爾很少觸及 I-cache 容量(由於平衡命中率(balancing hit rates)和延遲),因此這是一個顯着的變化,一旦英特爾更多地談論架構,看到其後果將會很有趣。
與此同時,Crestmont E-core 系列的新成員可以將這些核心打包成 2 或 4 核集羣,這與目前僅提供 4 核集羣的 Gracemont 不同。這本質上就是英特爾將如何調整二級緩存與CPU核心的比例;無論配置如何,2 核集羣都具有 4MB 共享 L2,每個核心為每個核心提供的 L2 數量是其他方式的兩倍。這實質上為英特爾提供了另一個調整芯片性能的旋鈕;需要稍高性能的 Sierra 設計(而不僅僅是最大化 CPU 核心數量)的客户可以使用更少的核心,同時獲得更大的二級緩存帶來的更高性能。
最後,對於 Sierra/Crestmont,該芯片將提供與 Granite Rapids 儘可能接近的指令。這意味着 BF16 數據類型支持,以及對各種指令集的支持,例如 AVX-IFMA 和 AVX-DOT-PROD-INT8。除了 AMX 矩陣引擎之外,您在這裏找不到的唯一東西是對 AVX-512 的支持;英特爾的超寬矢量格式不屬於 Crestmont 功能集的一部分。最終,AVX10 將有助於解決這個問題,但目前這已經是英特爾能夠在兩個處理器之間達到同等水平的最接近的了。

同時,對於 Granite Rapids,我們有 Redwood Cove P 核心。Redwood/Granite 是 Xeon 處理器的傳統核心,對於英特爾來説,變化並不像 Sierra Forest 那樣大。但這並不意味着他們袖手旁觀。
在微架構方面,Redwood Cove 獲得了與 Crestmont 相同的 64KB I-cache,容量是其前身的 2 倍。但最值得注意的是,英特爾成功地進一步降低了浮點乘法的延遲,將其從 4/5 個週期減少到僅 3 個週期。像這樣的基本指令延遲改進很少見,因此我們總是歡迎看到它們。
除此之外,Redwood Cove 微架構的其餘亮點是分支預測和預取,這是英特爾的典型優化目標。他們可以採取的任何措施來改進分支預測(並降低罕見失誤的成本),往往會在性能方面帶來相對較大的紅利。
Redwood Cove 的 AMX 矩陣引擎獲得了 FP16 支持,尤其適用於 Xeon 系列。FP16 的使用不如已支持的 BF16 和 INT8 那麼多,但它總體上改進了 AMX 的靈活性。
內存加密支持也正在得到改進。Granite Rapids 的 Redwood Cove 版本將支持 2048 個 256 位內存鍵(memory keys),而 Sapphire Rapids 則支持 128 個鍵。高速緩存分配技術 (CAT) 以及代碼和數據優先級 (CDP) 功能也得到了一些增強,英特爾將它們擴展為能夠控制進入 L2 高速緩存的內容,而不僅僅是之前的 LLC/L3 高速緩存實施。
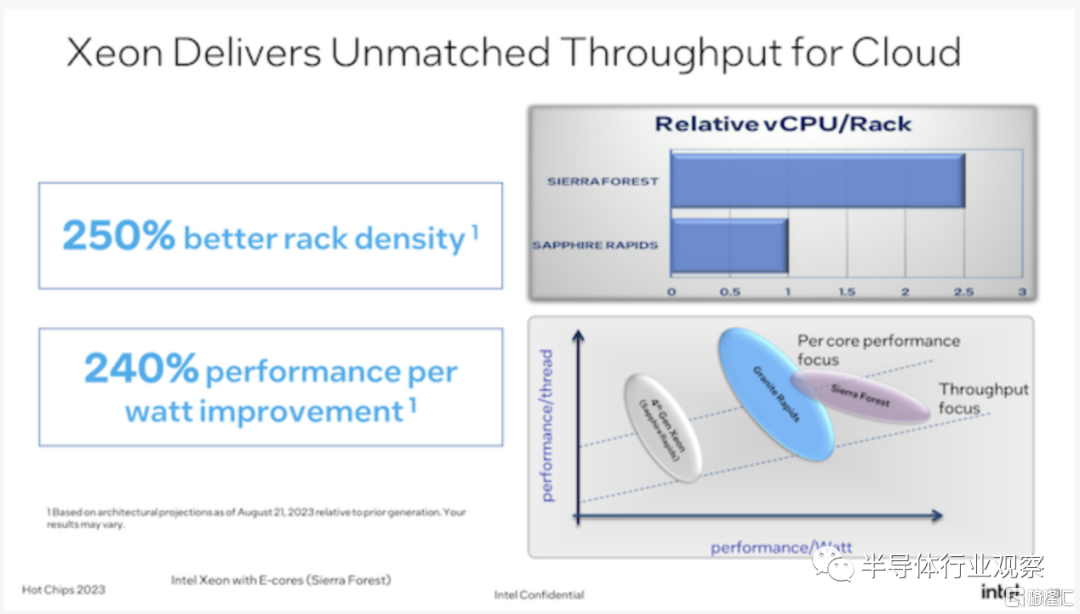
最終,不言而喻的是,英特爾相信他們即將推出的 Xeon 處理器將在 2024 年及以後做好準備。通過提高高端 P 核 Xeon 的性能,同時為只需要大量更輕的 CPU 內核的客户推出 E 核 Xeon,英特爾相信他們可以通過共享一個通用平台的兩種 CPU 內核類型來滿足整個市場的需求。
雖然現在談論 Granite Rapids 和 Sierra Forest 的各個 SKU 還為時過早,但英特爾吿訴我們,核心數量總體正在增加。Granite Rapids 部件將提供比 Sapphire Rapids 更多的 CPU 內核(SPR XCC 為 60 個),當然,Sierra 的 144 個內核將提供更多的 CPU 內核。但值得注意的是,英特爾不會按核心數量來劃分這兩個 CPU 系列——Sierra Forest 也將提供較小核心數量的產品(與 AMD 的 EPYC Zen4c Bergamo 芯片不同)。這反映了 P 和 E 核心的不同性能能力,毫無疑問,英特爾希望充分擁抱使用小芯片帶來的可擴展性。
雖然 Sierra Forest 已經採用 144 個 CPU 核心,但英特爾還在我們的預簡報中發表了一個有趣的評論,即他們的首款 E 核至強可擴展處理器的核心數量本可以更高。但該公司決定更加優先考慮每個核心的性能,從而產生我們明年將看到的芯片和核心數量。

最重要的是,英特爾正在強調他們的下一代 Xeon 處理器仍有望在 2024 年推出,這一事實或許讓營銷對 Hot Chips 的掌控時間有點太長了。不用説,英特爾剛剛從 Sapphire Rapids 的大規模延誤(以及 Emerald Rapids 的連鎖反應)中恢復過來,因此該公司熱衷於向客户保證 Granite Rapids 和 Sierra Forest 是英特爾的時機重回正軌的地方。在之前的 Xeon 延遲和花了很長時間才將 E 核 Xeon 可擴展芯片推向市場之間,英特爾並沒有像以前那樣在數據中心市場佔據主導地位,因此 Granite Rapids 和 Sierra Forest 將標誌着一個重要的拐點英特爾數據中心產品的未來發展。
AMD Siena閃亮登場
在 Hot Chips 2023 上,AMD 詳細介紹了 AMD EPYC Genoa、Genoa-X 和 Bergamo CPU。它還在演講中展示了即將推出的 Siena 平台的關鍵規格。
我們知道,AMD Zen 4 是AMD EPYC 7003“Milan”中使用的 Zen 3 的重大升級,具有更高的 IPC、更多的時鐘和更低的功耗。
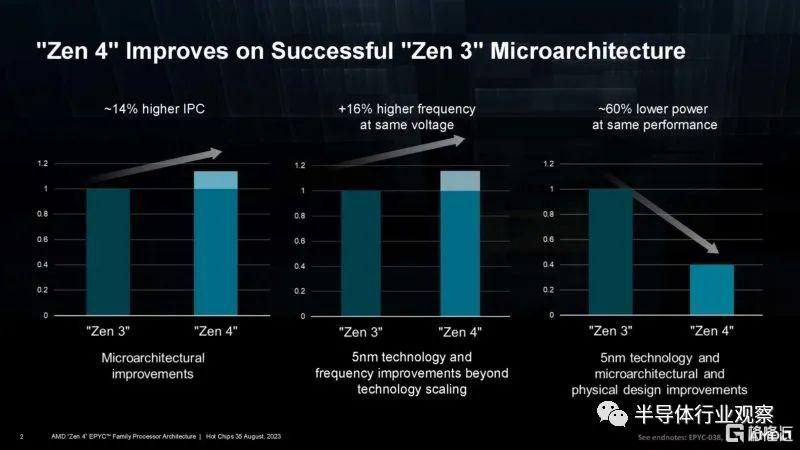
Zen 4c 則為Bergamo帶來了更加緊湊的 Zen 4 核心。即便如此,AMD 仍然專注於製造大型 CPU。在Hot Chips上,他們就展示了一種低端解決方案。
AMD 的 Socket SP5 策略是構建不同的小芯片並將它們與通用 I/O 芯片結合起來。

現在,AMD 展示了第四代 AMD EPYC 產品組合的第四個成員,即面向電信邊緣市場的 Siena。

迄今為止,我們對Genoa的披露最多。我們最多隻有 64 個內核和 6 個 DDR5 DRAM 通道。Siena 的規模將遠低於 Genoa,TDP 為 70W 至 225W,儘管沒有英特爾的某些 Xeon D 部件那麼低。

AMD 需要較低功耗的部件,因為英特爾擁有其單片芯片 Sapphire Rapids 部件,該部件對於 32 核及以下的核心非常有吸引力,這是市場上的主要銷量細分市場。96 或 128 核 350W+ 很棒,但它們不適合需要低於 150W CPU 的應用。
AMD 還展示了一張有趣的 CCD 幻燈片,展示了 I/O 芯片的一些功能。
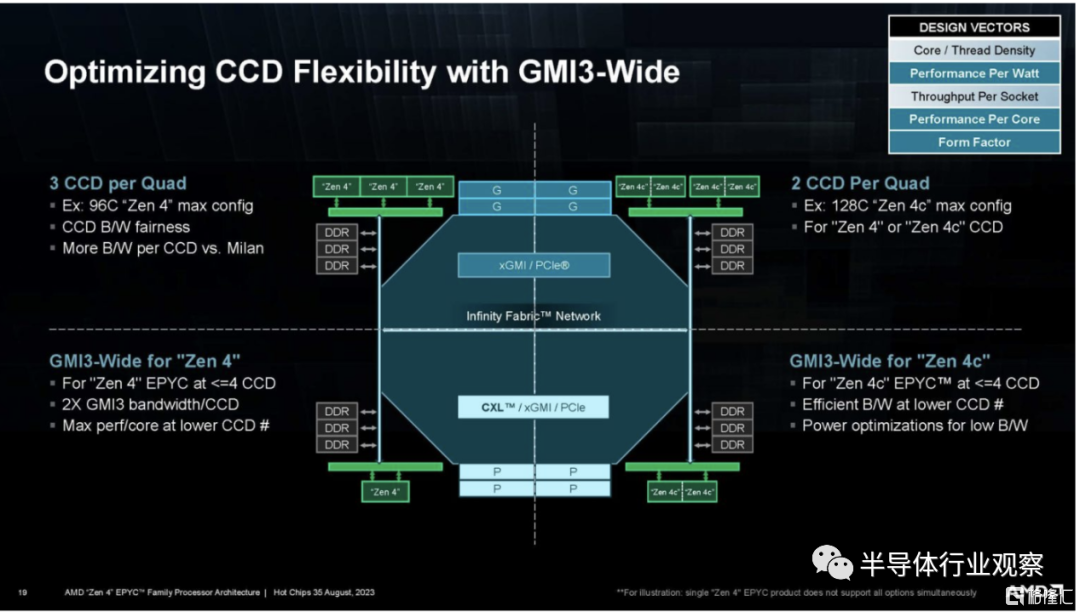
這是一張很棒的幻燈片。AMD 還擁有一項內存技術,包括 CXL。
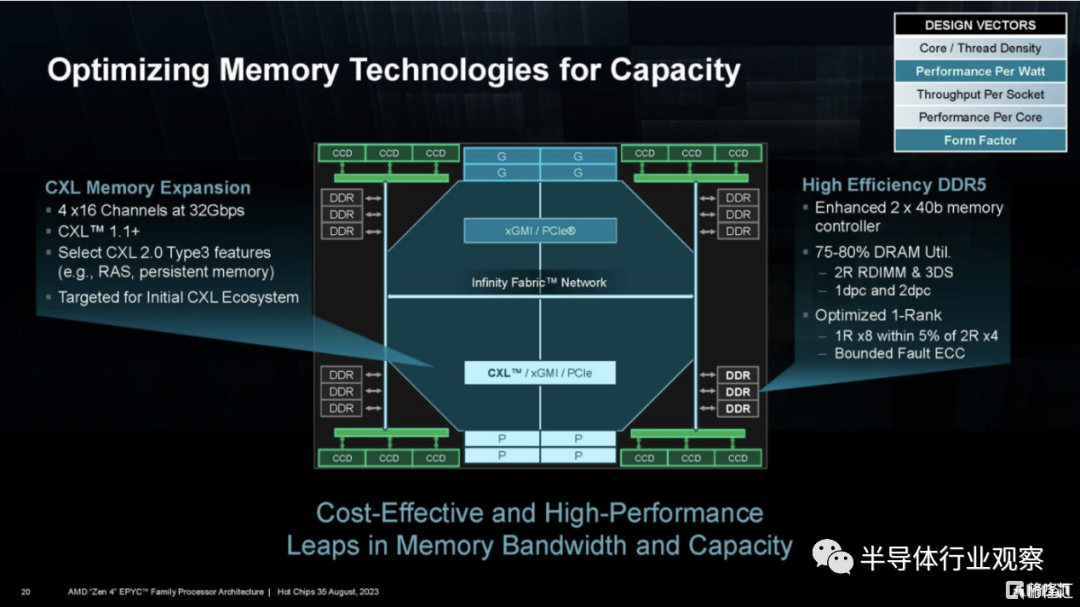
我們對 AMD EPYC Siena 的推出感到非常興奮,因為 AMD 在低功耗領域的服務器產品組合中存在很大的漏洞。我們終於看到 AMD 如何利用一半的 DDR5 通道和更少的核心來實現這一目標。
Arm帶來兩款處理器
在今年的hotchips上,Arm帶來了Arm Neoverse V2和Neoverse N2的更多分享。
Arm Neoverse V2 是當前一代 Neoverse 解決方案的一部分。Arm 致力於為數據中心和基礎設施市場提供參考核心。Neoverse V2更多的是高性能數據中心CPU核心,而N2更多的是基礎設施。

我們之前介紹過 Neoverse V2,其目標是提高 AWS 等公司在 Graviton 系列中使用的 Neoverse V1 設計的性能。

Arm Neoverse V2 是 Armv9 架構。這是一張顯示核心部分亮點的圖表。
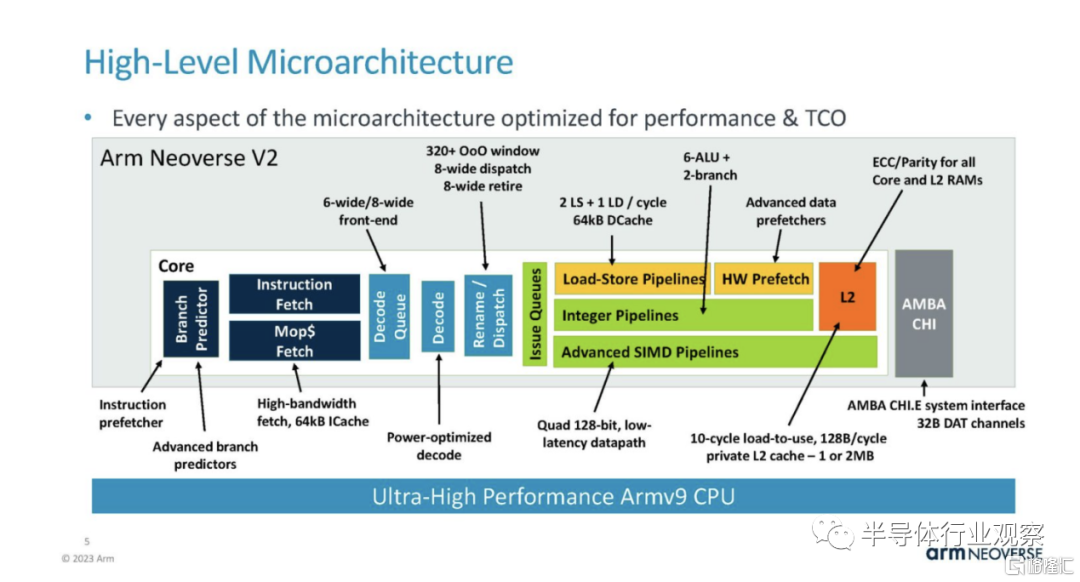
在分支上,預測/獲取/ICache 與 Neoverse V1 部分共享,但有一些重大改進。Arm 在每個部分都展示了這些變化對性能的影響,這非常酷。
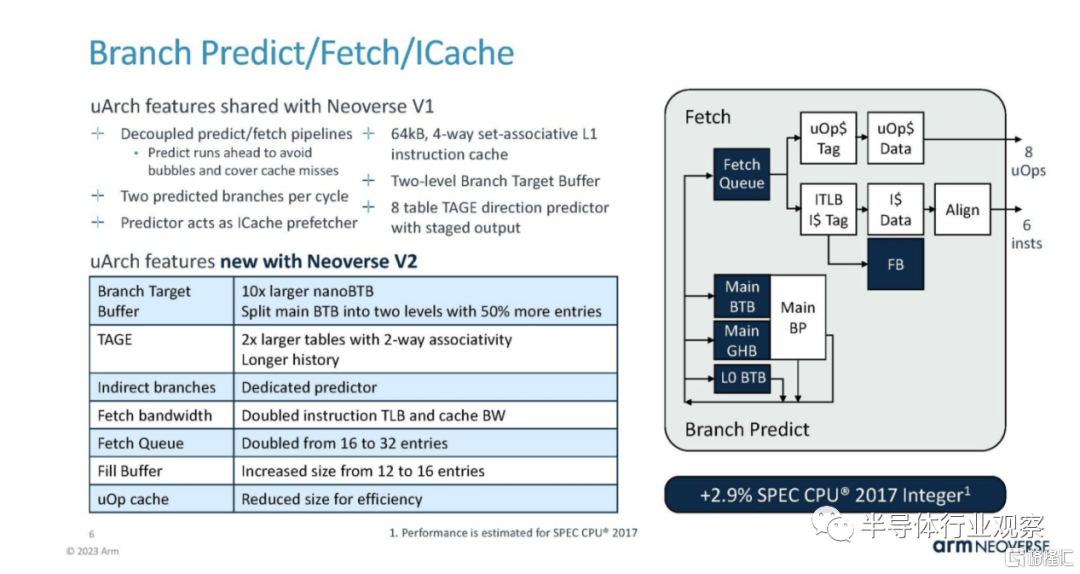
這是V2的主題。它主要基於V1不斷升級並提供更多資源。

問題/執行方面是 V2 中的一個重大變化。

Load/Store 和 DCache 發生了變化,例如 TLB 增加了 20%。
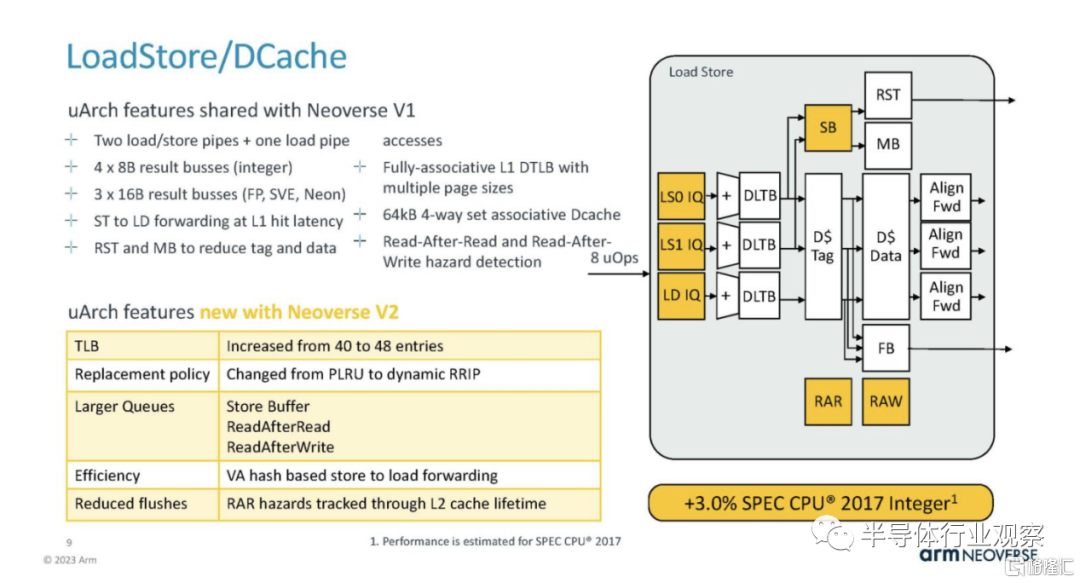
這也意味着 Arm 需要改進內核的硬件預取,以保持執行單元和緩存的運行。
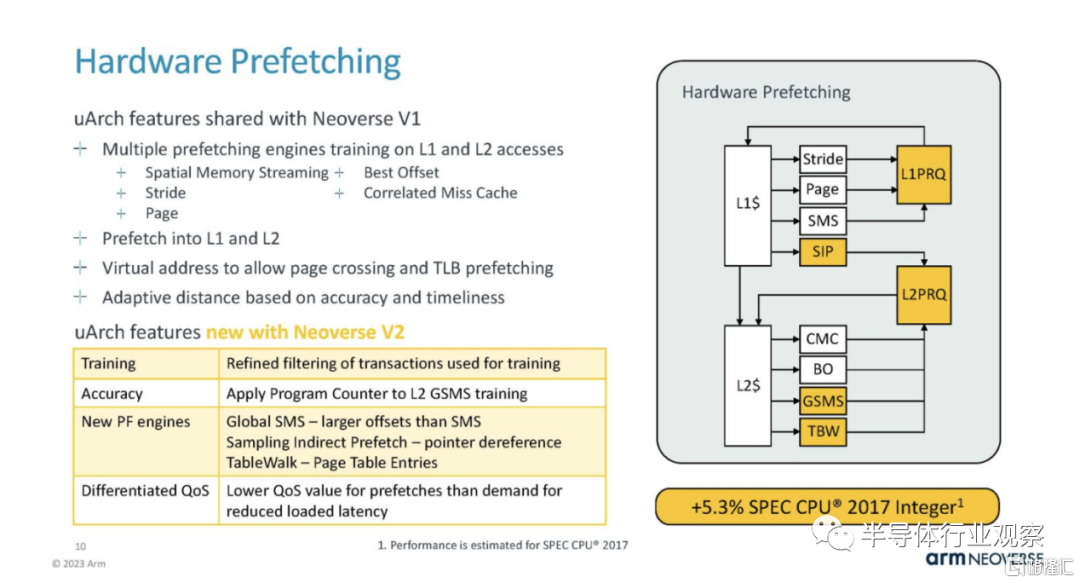
L2 緩存是每個核心私有的,是數據中心的重要特性。這是一個較小的 SPEC Int 增益區域。
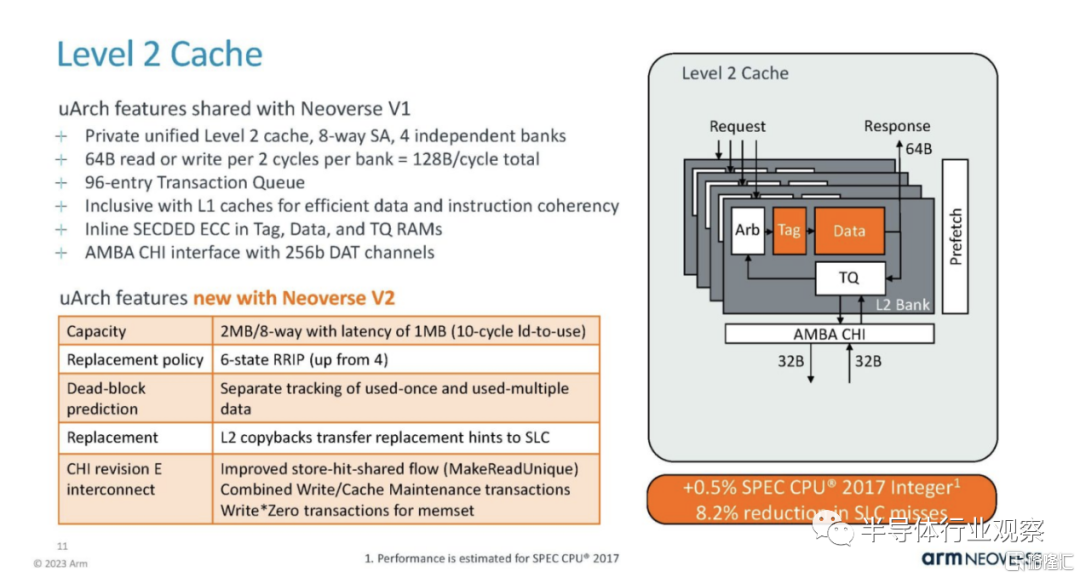
Arm 表示,與 V1 相比,這些 V2 變化綜合起來使每個內核的性能提高了約 13%。如果添加的話,每個部分的數字並不等於 13% 的增長。這是因為某些變化會影響其他變化,因此總數小於每個單獨改進領域的總和。
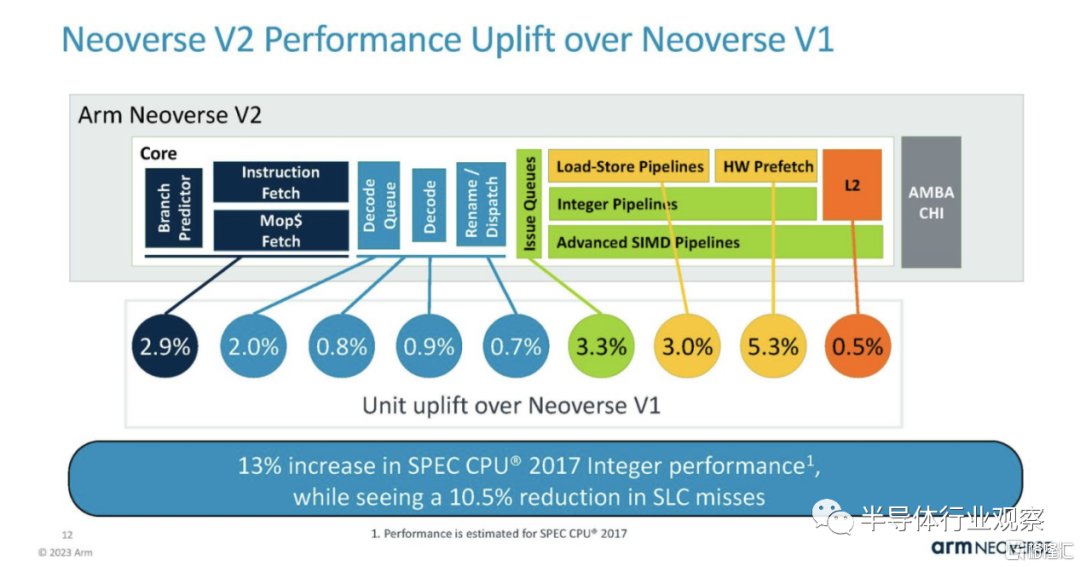
Arm 表示,新內核從台積電 7 納米縮小到 5 納米,儘管 L2 緩存增加了一倍,但功耗僅增加了約 17%,面積也大致相同。有趣的是,上面幻燈片中的 Arm 表示 V2 快了 13%,但下面的幻燈片使用了 16.666% 的功率。
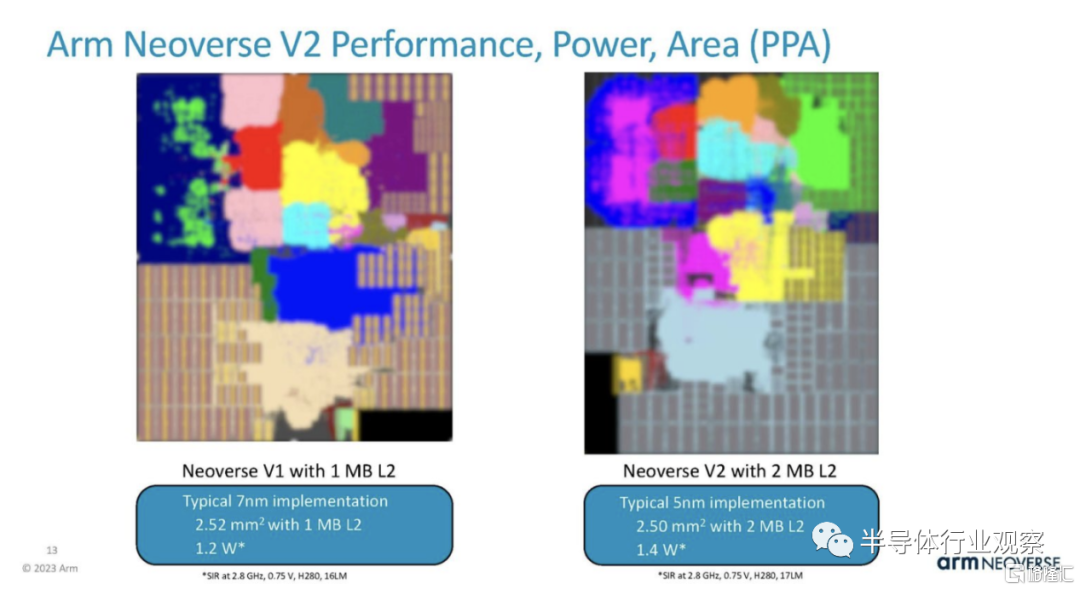
除了 V2 內核本身之外,該平台還具有 CMN-700 互連等功能,可提供更多緩存並增加內核數量。對於 Arm Neoverse 內核,這是內核,而不是整個芯片,因此需要採購 PCIe Gen5 IP 等項目。

以下是性能結果的假設:

Arm 正在展示其整數性能。在預簡報電話會議上,分析師詢問了兩個估計結果之間的差異,因為右側圖表標記為“SPECrate”,但都沒有標記為基礎或峯值。Arm 無法證實這一點。我們最好的猜測是,左圖是基礎圖,右圖是峯值圖,但這只是猜測,因為 Arm 無法確認他們所顯示的內容。
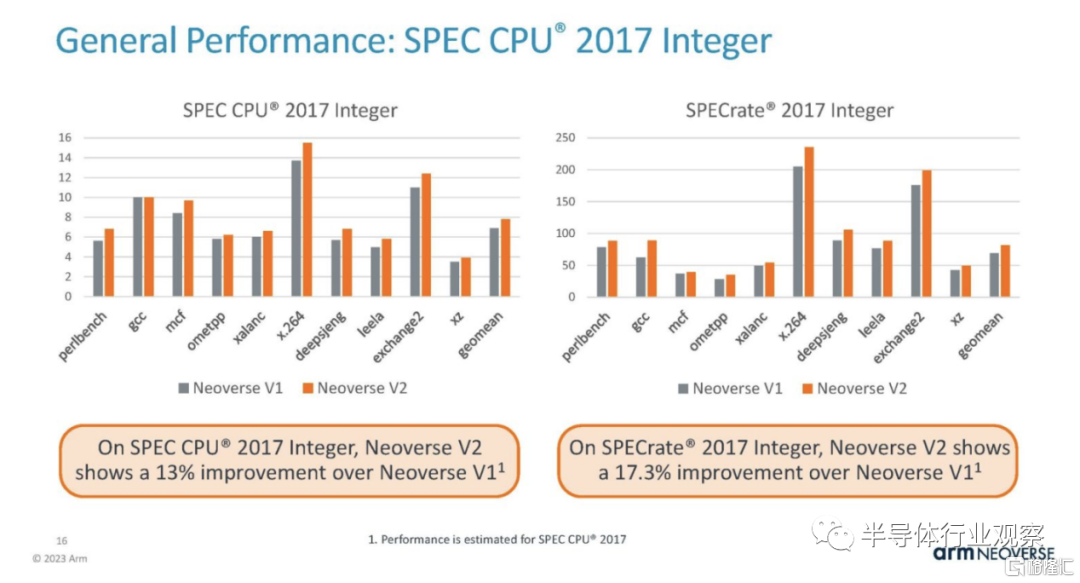
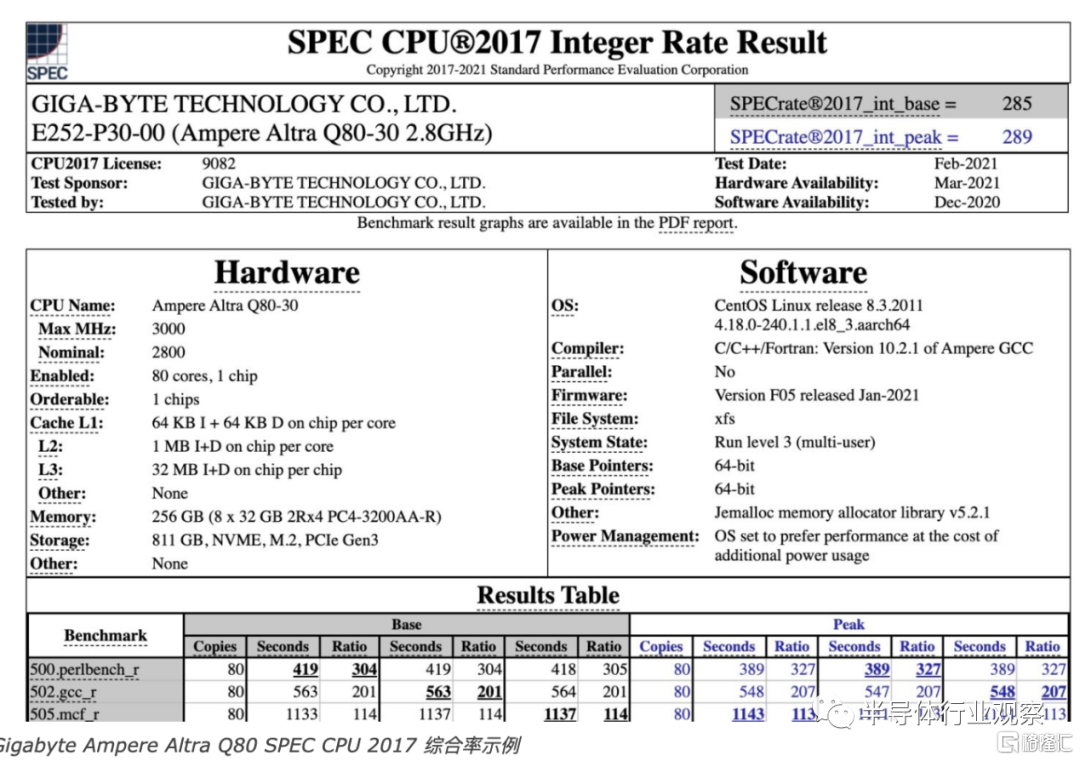
這些結果只是估計值,但以下是實際提交的結果,其中結果標有基線和峯值。令人驚奇的是,CPU 公司竟然無法回答這個問題。
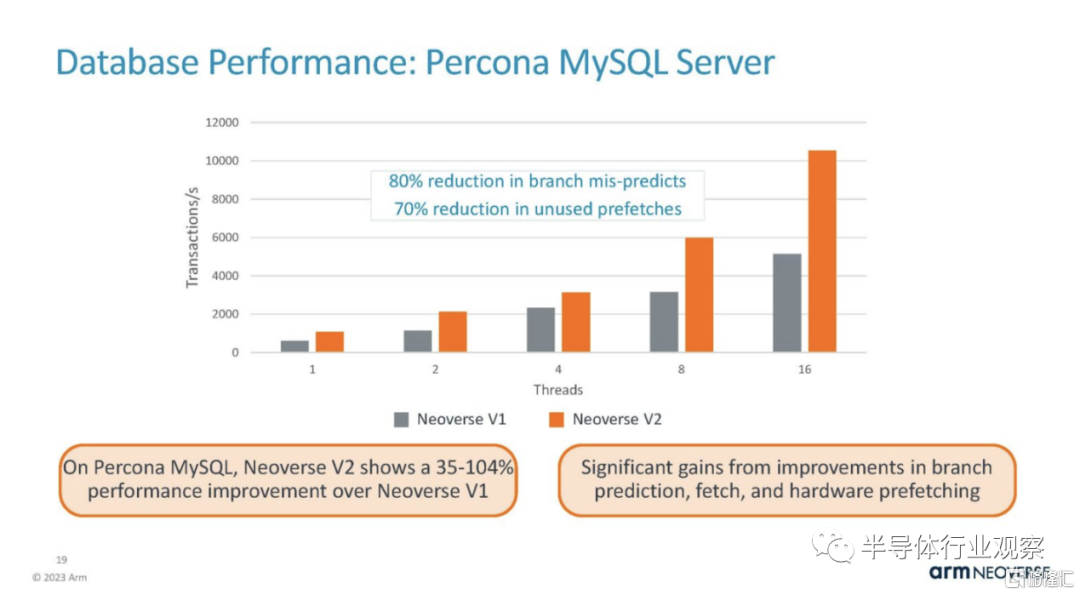
這裏是 Memcached,它通常較少受 CPU 限制,但較多內存/緩存限制。它是另一個整數,而不是浮點工作負載。因此,它通常在 Arm CPU 上表現良好。

Nginx 是一種流行的 Web 服務器。這是另一個以整數為主的模型,因此一直是顯示 Arm 服務器性能的支柱。
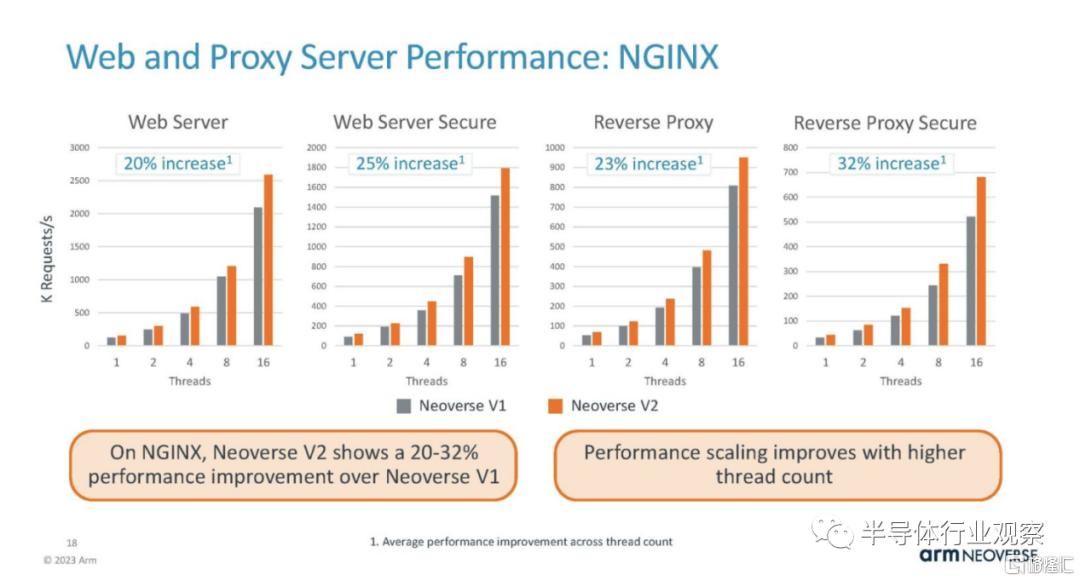
這是整數工作負載基準測試的另一個趨勢。這一個得到了更大的推動。
這是 XGBoost 性能。
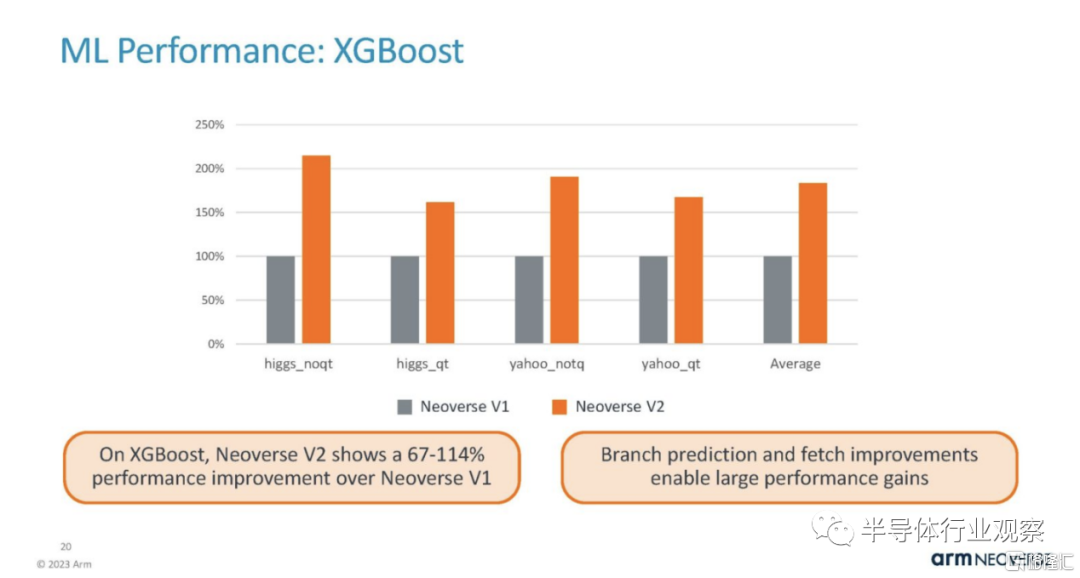
NVIDIA Grace Superchip 和 Grace Hopper 均使用該技術。這些主要是內存帶寬敏感的工作負載。Grace Superchip 的正確比較應該是 Intel Xeon Max 和Genoa-X。

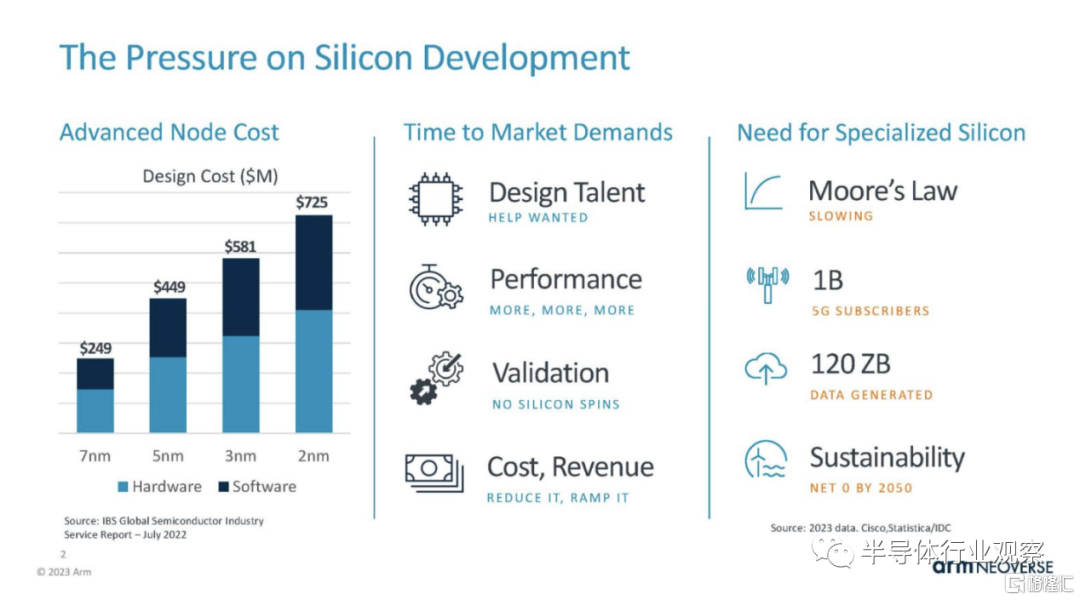
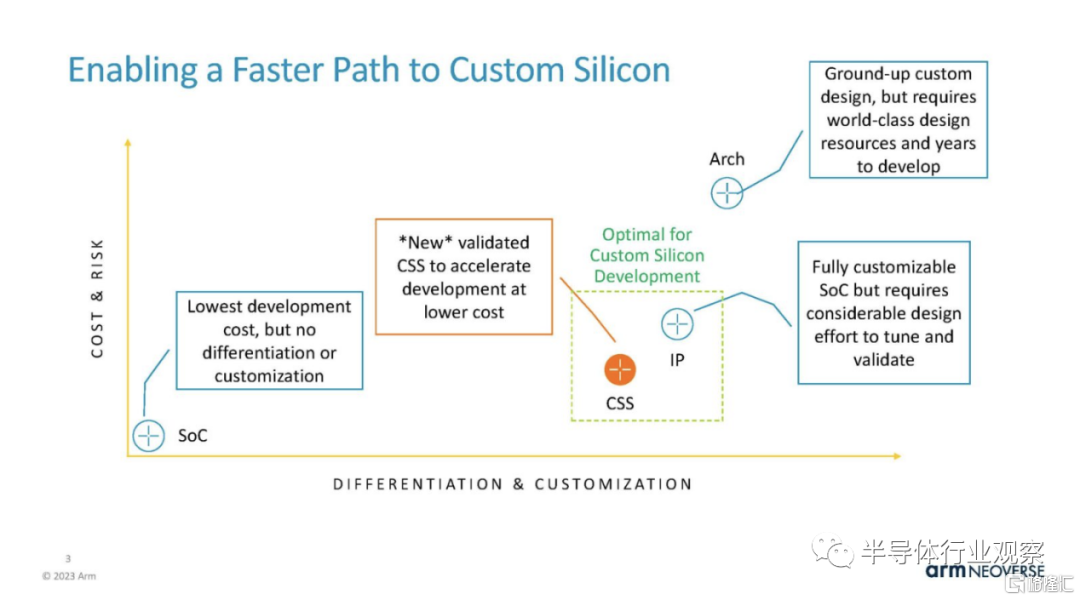
在 Hot Chips 2023 上,Arm 展示了一種實現Neoverse N2 內核的新方法。Arm Neoverse 計算子系統或 Neoverse CSS ,該系統不僅僅授權 N2 核心 IP,還允許客户購買更大的 IP 模塊以投入設計。

Arm 的目標是 Neoverse CSS,讓 Chiplet 社區能夠更輕鬆地集成 Noeverse N2 內核。
藉助新的經過驗證的 CSS 解決方案,實現 Arm 內核所需的工作量更少,從而加快了開發速度,但 Arm 還有其他選擇。
Neoverse CSS 已完全驗證 RTL 調整並準備好實施到設計中。
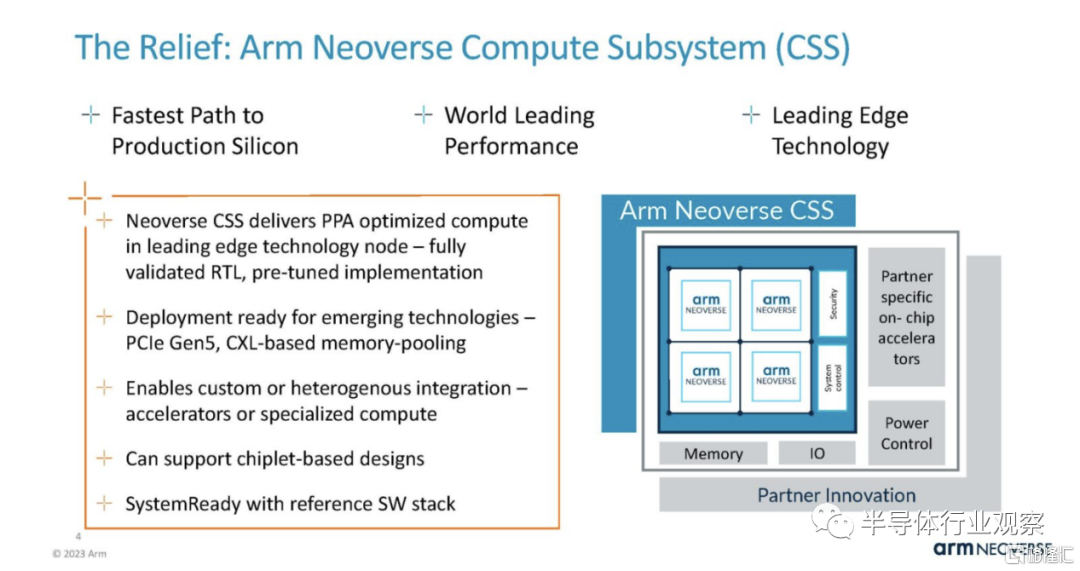
第一個 Neoverse CSS 產品是 Neoverse CSS N2。它使用 Arm 的橫向擴展 Neoverse N2 內核,並允許公司選擇內核集羣並在設計中實現它們。
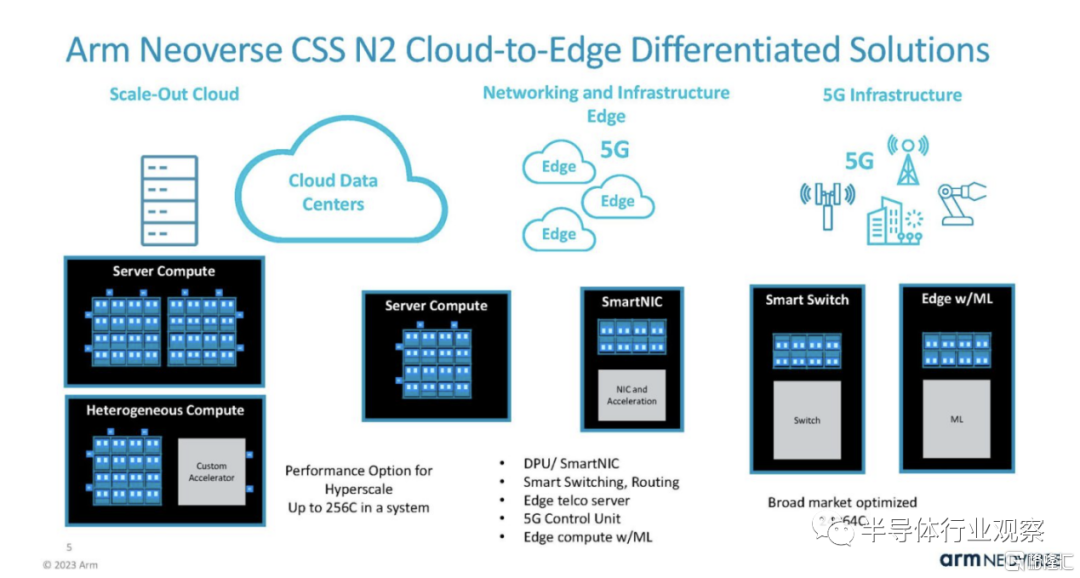
N2 可從每芯片 24、32 和 64 個核心設計進行擴展。它具有連接 DDR5、LPDDR5、PCIe/CXL 和其他類型 IP 的接口。

這是框圖。Arm 在這裏使用 CMN-700 將不同的組件連接在一起。CSS 開箱即用,符合 Arm 標準,這是有道理的。
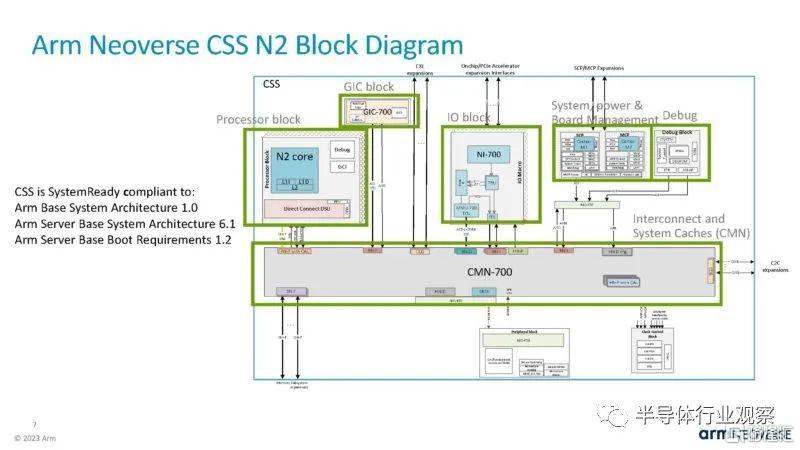
處理器 IP 模塊基於 Neoverse N2 內核。

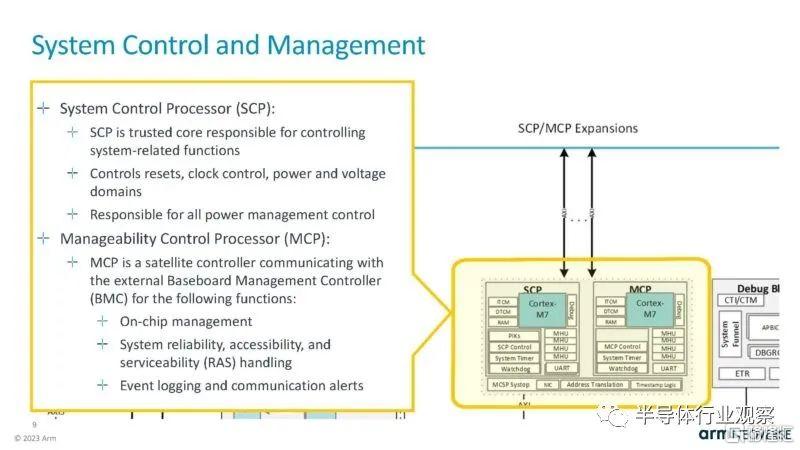
還有一個用於系統控制和管理的IP塊。
還有一個系統MMU和中斷控制器。
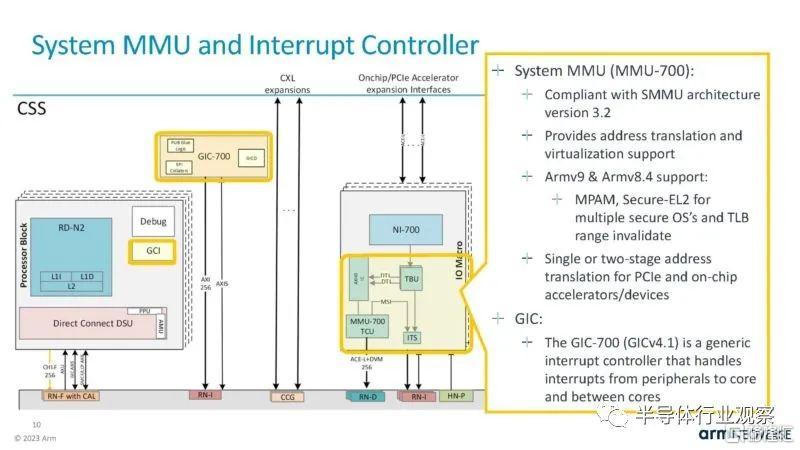
同樣,Neoverse CMN-700 包含系統級緩存和基於網格的一致互連。
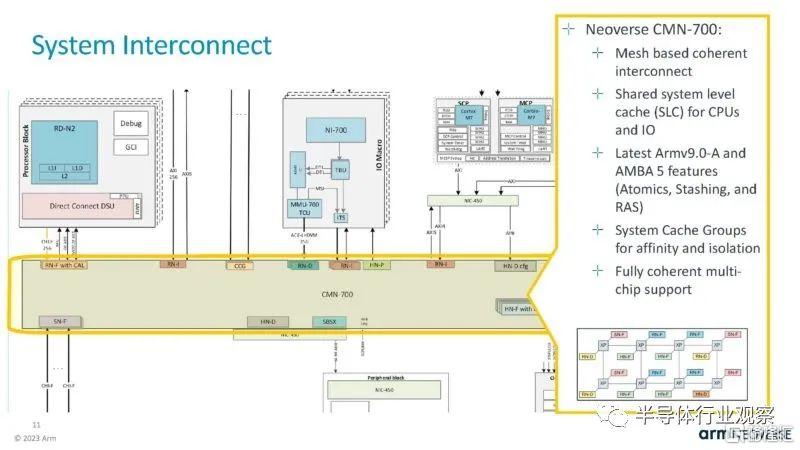
Arm 的目標客户是想要附加加速器的供應商,因此它擁有用於連接這些加速器的 IP。

通過將兩個 64 核 Neoverse N2 小芯片連接在一起,Arm 可以達到每個插槽 128 個核心。這吿訴我們,Arm 的目標並不是成為這一代具有競爭力的高密度服務器 CPU 基礎。根據我們迄今為止所看到的Marvell Octeon 10等部件和Ampere Altra Max M128-30等 Neoverse N1 128 核心部件, 28 個 Arm Neoverse N2 核心將無法與 AMD 發貨的 Bergamo 性能相匹配。這確實適合那些需要 CPU 內核作為加速器的人。

芯片和小芯片有不同的接口選項。
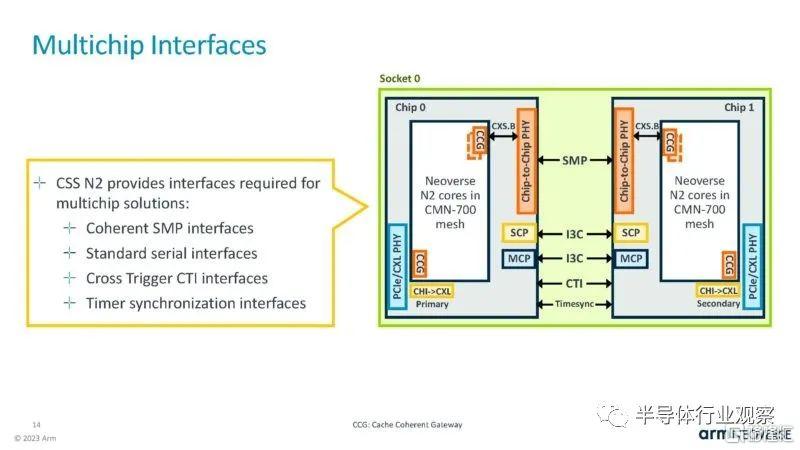
這是 CMN 網關,但同樣,這似乎並不是為高端多插槽 CPU 系統設計的。
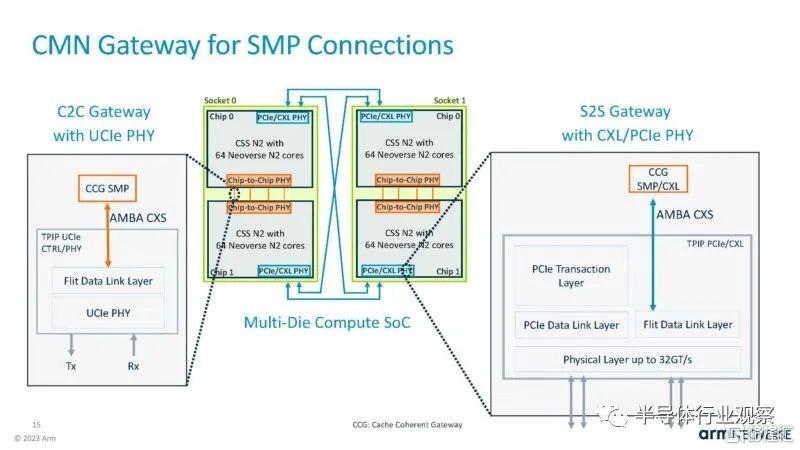
這是添加的有關 CXL 和 PCIe IP 的幻燈片。
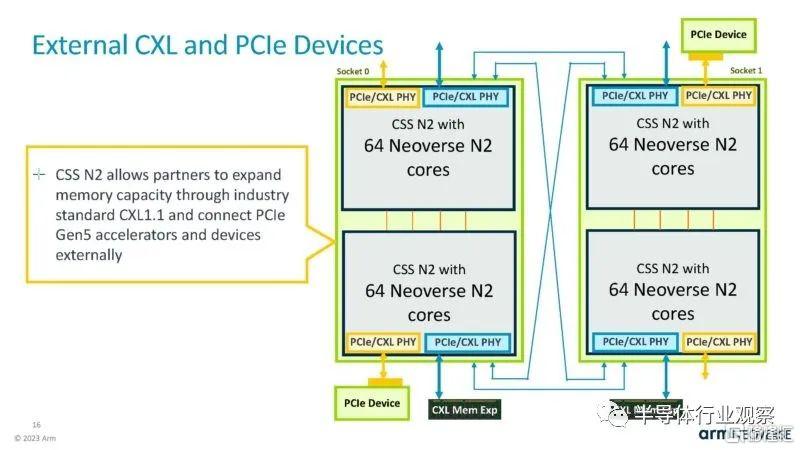
Arm 表示,通過正確添加的 IP,它可以支持CXL Type-3 內存擴展設備。

以下是以 32 核設計的 Arm Neoverse CSS N2 佈局為例。
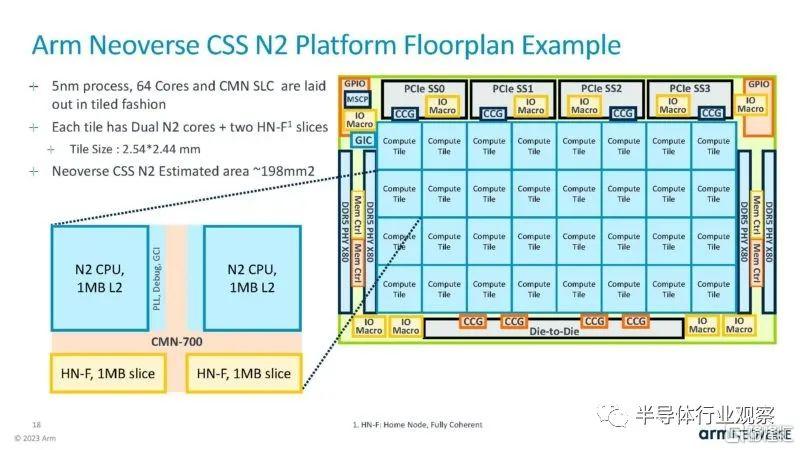
在這裏,我們可以有兩個 N2 塊,並通過 CMN-700 連接所有內容。
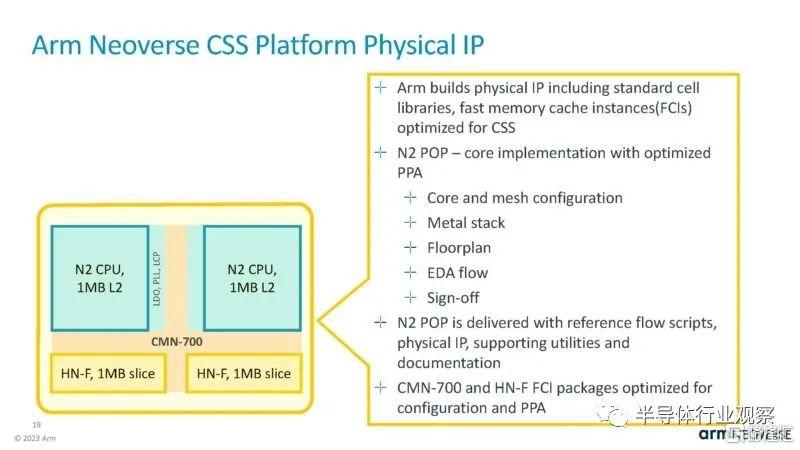
除了佈局規劃外,Neoverse CSS 還擁有 RTL 和其他軟件和設計平台工具,以幫助加快開發速度。

Arm 表示,利用這一點,它可能能夠將設計速度加快幾個季度。

英特爾和 AMD 需要解決這個問題。隨着時間的推移,Arm 的嵌入式 Neoverse CSS 可能會擴展到其他核心類型。未來,下一個問題是這與小芯片 CPU 的相關性如何。例如,如果英特爾允許代工客户購買並集成 E-core 小芯片,那麼下一步就是讓希望構建封裝的公司變得更容易。儘管如此,Arm 今天已經推出了 CSS,理論上,它允許公司輕鬆地將 N2 內核與加速器集成到非基於小芯片的 SoC 中。
這是一個很酷的解決方案,我們希望能夠擴展。另一方面,人們也可能會爭辯説,Arm 可以在未來為生態系統銷售預製的、可隨時與 UCIe 集成的 Neoverse 芯片。
Ventana 的RISC-V芯片Veyron V1
在 Hot Chips 2023 上,RISC-V CPU 初創公司 Ventana Micro 展示了其新數據中心 Veyron V1。Ventana Veyron V1 着眼於數據中心 RISC-V CPU 的新時代。雖然這是在 V1 產品上,但該公司顯然已經在使用 V2 產品了。

Ventana 為Veyron V1 提供了一個有趣的目標市場,最好的描述是“只要我們能找到需求”。

之所以有這個想法,是因為Ventana Micro 擁有一個 RISC-V CPU 內核,每個小芯片最多有 16 個內核,然後將它們與具有 DDR 內存控制器和 PCIe 等功能的 I/O 集線器結合起來。Ventana 表示,它可以將 Veyron V1 擴展至 192 個核心,但它也可以集成特定領域的加速器。
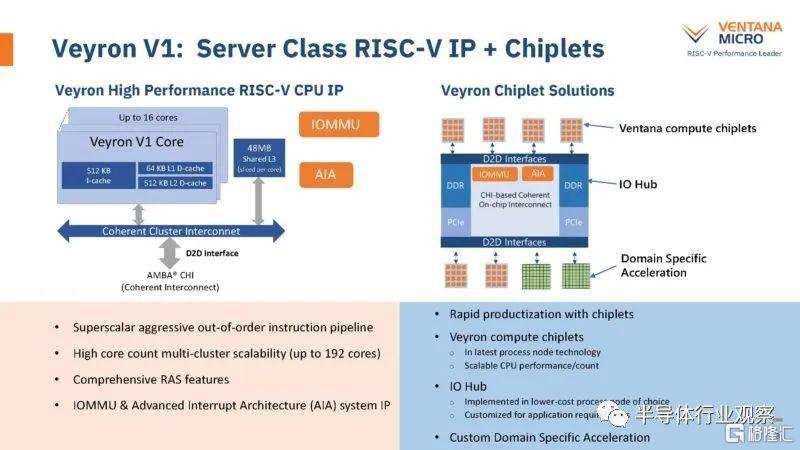
以下是芯片的關鍵規格,包括核心、緩存等。Ventana 表示,Veyron V1 將支持虛擬化等功能,並採取措施使其更能抵禦側信道攻擊。在支持方面,令我們驚訝的是該公司已經在討論嵌套虛擬化。我們看到的 Arm Neoverse N1 芯片甚至不支持嵌套虛擬化。

這裏有更多關於核心微架構的信息。

這裏有更多關於這一點的內容。

這是一個非常難以閲讀的圖表中的管道。
這是預測、獲取和解碼幻燈片:

以下是加載/存儲詳細信息:

從處理器集羣規模來看,每個16核集羣擁有高達48MB的L3緩存。

如果該公司將 UCIe 納入此處只是為了説它是首批UCIe CPU之一併傾向於小芯片,那就真的很有趣了。

在性能方面,Ventana 的目標是達到上一代 128 核 Veyron的性能。AMD EPYC Bergamo等 CPU 的數量比 Milan 高得多(>2 倍)。該公司表示,V2 尚未投入生產,而Bergamo已經普遍上市。

在 RISC-V 市場中,Ventana 目前不必比 AMD 和 Intel 更快。它只需不是 x86,不是 Arm,而是 RISC-V。人們正在將 RISC-V 專門視為未來 CPU 和 xPU 設計中 Arm 的替代品。

Ventana 還具有可用於 TSMC 5nm的參考 Veyron V1 實現。
RISC-V 是 x86 替代領域值得關注的技術。Arm 已經很大了,但隨着它致力於改進其業務,RISC-V 有機會顛覆 Arm 所做的大量工作。2016年,當我們評測Cavium ThunderX時,Arm服務器CPU非常粗糙。從那時起,從單一 x86 架構代碼庫和基礎設施遷移到 x86 和 Arm 的多架構世界已經做了很多工作。RISC-V 正在利用其中的大量工作來提高其市場速度。它的 I/O 芯片設計似乎也借鑑了 AMD 的經驗教訓,這已被證明是成功的。
三星展示PIM內存技術
在 Hot Chips 2023 (35) 上,三星再次談論其內存處理 (PIM),並進行了新的研究和新的轉變。如三星所説,計算中最大的成本之一是將數據從不同的存儲和內存位置移動到實際的計算引擎。

目前,公司嘗試為不同類型的內存添加更多通道或通道,但這有其侷限性。
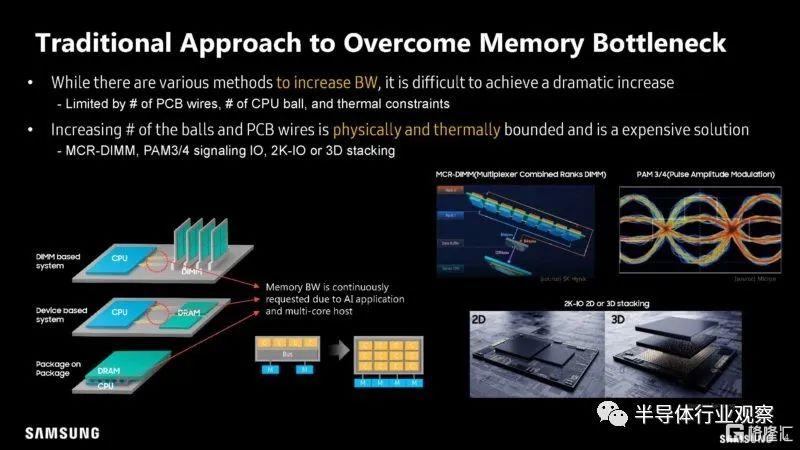
三星正在討論 CXL。CXL 很有幫助,因為它允許重新調整 PCIe 線路的用途,以提供更多內存帶寬。
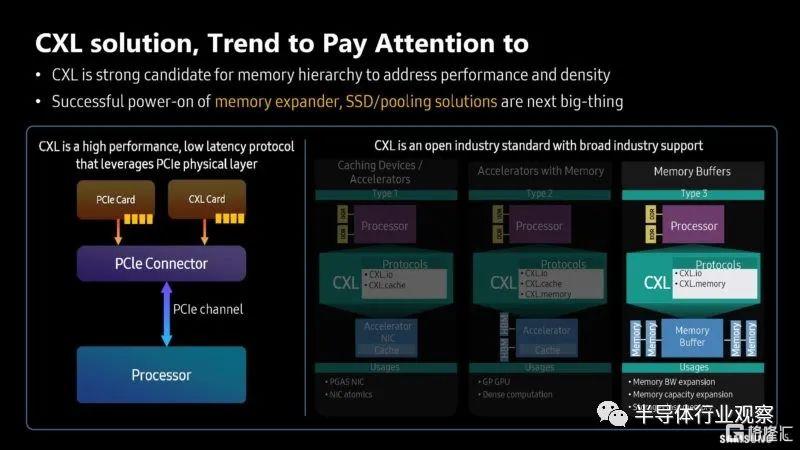
在三星的分享中,他們也談到了ChatGPT的瓶頸。
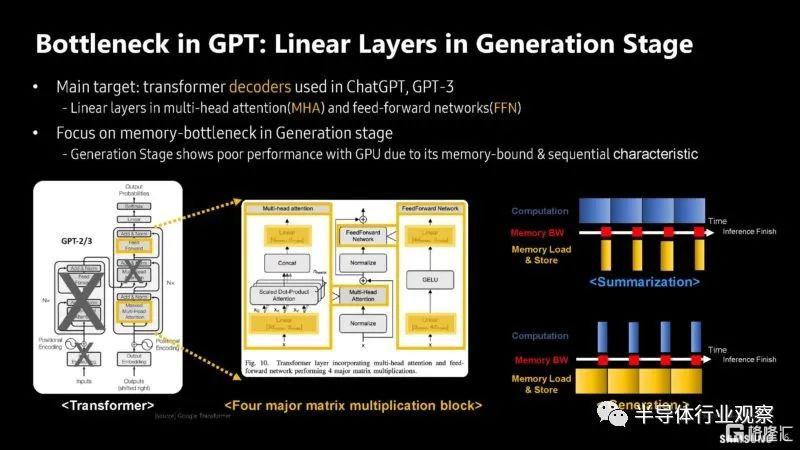
三星同時也對 GPT 的計算溢出和內存限制工作負載進行了分析。
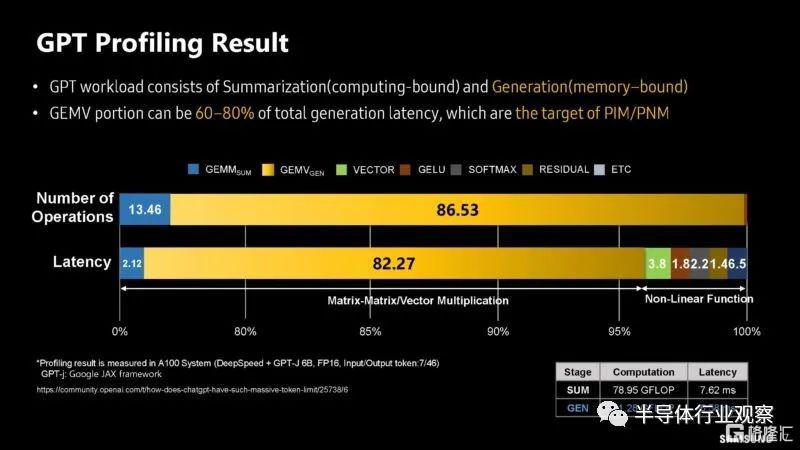
以下是關於利用率和執行時間方面的分析工作的更多信息。
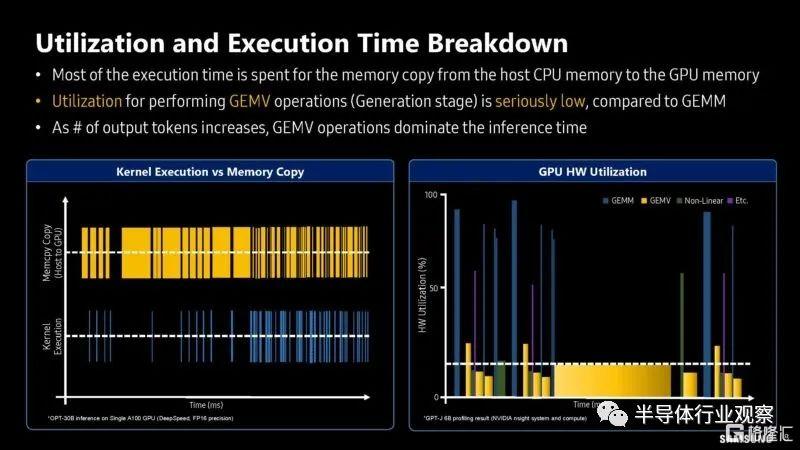
三星展示瞭如何將部分計算管道卸載到內存處理 (PIM) 模塊。
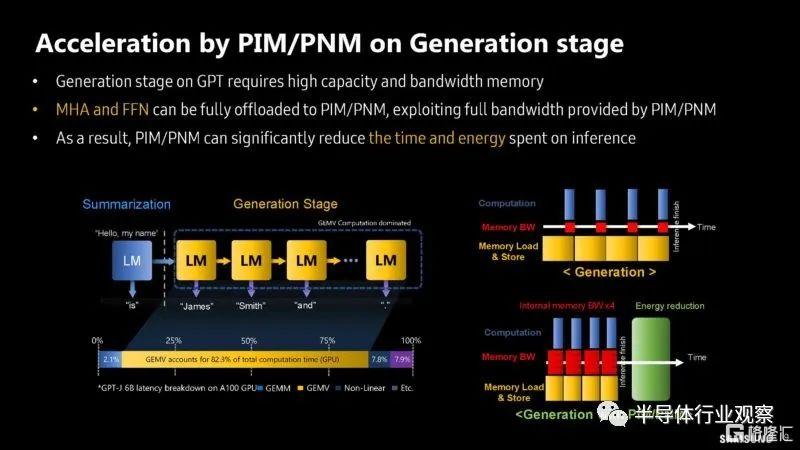
在內存模塊而不是加速器上進行處理可以節省數據移動,從而降低功耗和互連成本。

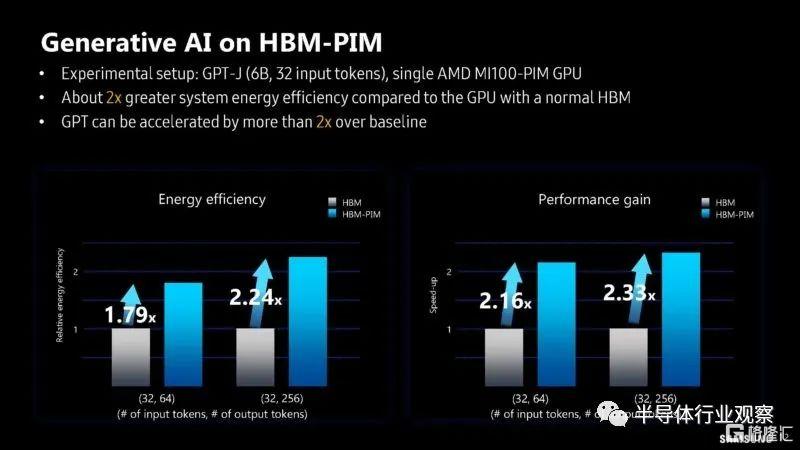
在 SK 海力士談論其解決方案中的 GDDR6 時,三星則展示了其高帶寬內存 HBM-PIM。

顯然,三星和 AMD 的 MI100 帶有 HBM-PIM 而不僅僅是標準 PIM,因此它可以構建一個集羣,這樣它就可以擁有聽起來像 12 節點 8 加速器的集羣來嘗試新內存。

以下是 T5-MoE 模型如何在集羣中使用 HBM-PIM。

以下是性能和能源效率的提升。

其中很大一部分還在於如何讓 PIM 模塊做有用的工作。這需要軟件來編程和利用 PIM 模塊。
三星希望能夠將此內置於標準編程模塊中。

這是用於內存耦合計算的 OneMCC 的未來狀態,但這聽起來像是未來的狀態,而不是當前的狀態。

看來三星不僅展示了 HBM-PIM,還展示了 LPDDR-PIM。與當今的一切一樣,它需要一個生成式人工智能標籤。

這似乎更像是一個概念,而不是集羣中 AMD MI100 上使用的 HBM-PIM。
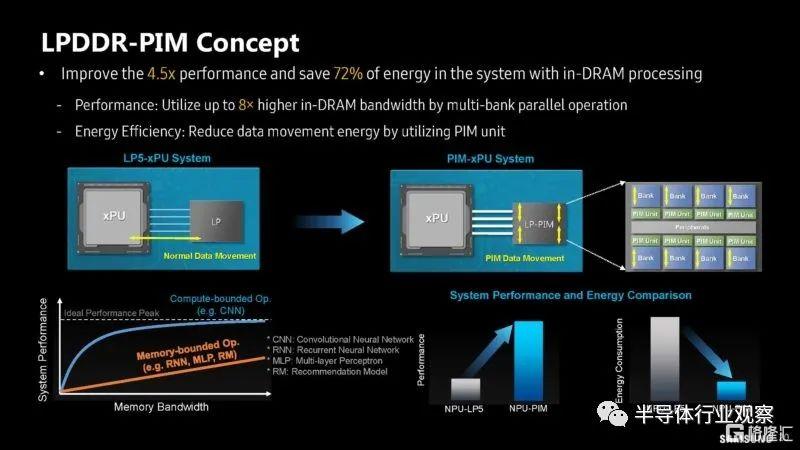
該 LPDDR-PIM 的內部帶寬僅為 102.4GB/s,但其想法是,將計算保持在內存模塊上意味着無需將數據傳輸回 CPU 或 xPU,從而降低功耗。

以下是模塊上包含 PIM 組和 DRAM 組的架構。
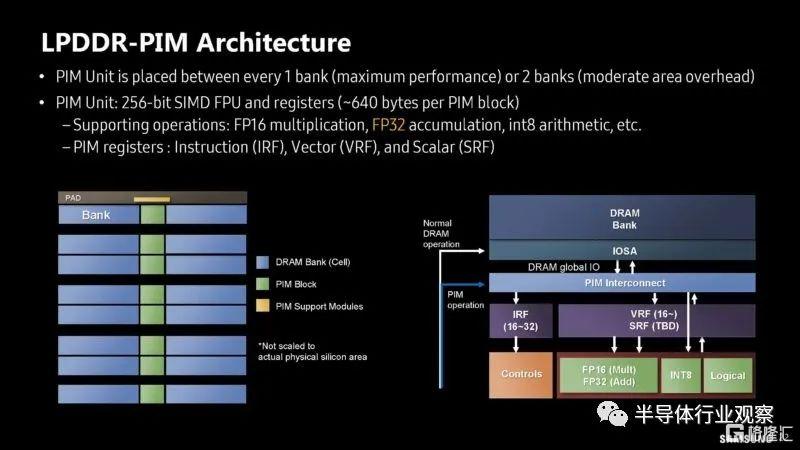
以下是可能的 LP5-PIM 模塊的性能和功耗分析。

如果 HBM-PIM 和 LPDDR-PIM 還不夠,三星正在考慮將計算放到 PNM-CXL 中的 CXL 模塊上。
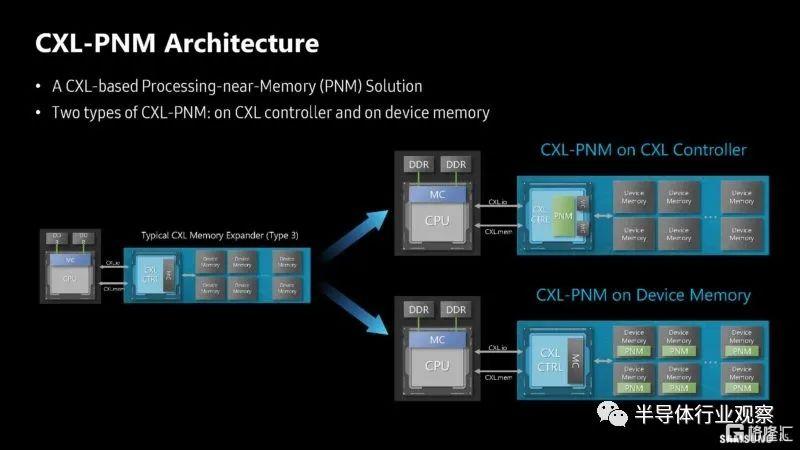
這裏的想法不僅僅是將內存放在 CXL Type-3 模塊上。相反,三星建議將計算放在 CXL 模塊上。這可以通過向 CXL 模塊添加計算元件並使用標準內存或在模塊上使用 PIM 和更標準的 CXL 控制器來完成。

當然,我們已經展示了這如何幫助 GPT 方面的生成人工智能。三星也推出了一款概念 512GB CXL-PNM 卡,帶寬高達 1.1TB/s。

這是三星提出的 CXL-PNM 軟件堆棧。

以下是大規模 LLM 工作負載的預期節能和吞吐量。CXL 通常通過也用於 PCIe 的電線,因此傳輸數據的能源成本非常高。因此,能夠避免數據傳輸會帶來巨大的好處。
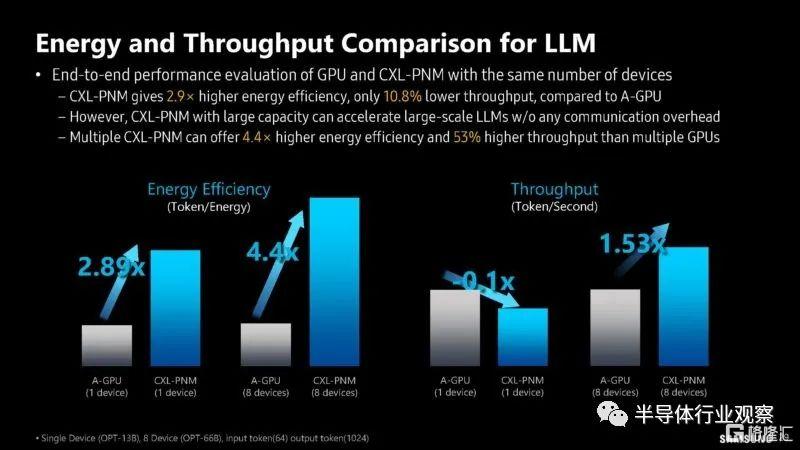
由於上述原因,三星也非常重視減排。

三星多年來一直在推動 PIM,但 PIM/PNM 似乎正在從純粹的研究概念轉變為真正希望將其產品化的公司。希望我們將來能看到更多這樣的事情。CXL-PNM 最終可能成為此類計算的成熟領域。
SK 海力士的 AI 內存亮相
在 Hot Chips 35 (2023) 上,SK 海力士將其在內存方面的專業知識應用於當今的大計算問題——人工智能。在展會上,它展示了其在具有特定域內存的內存中心計算方面的工作。該公司正在尋找方法來緩解當今人工智能計算面臨的最大挑戰之一,即與可用計算資源相關的內存容量和帶寬。
這是SK海力士的問題定義。生成式人工智能推理成本巨大。這不僅僅是人工智能計算。電源、互連和內存也導致了大量成本。
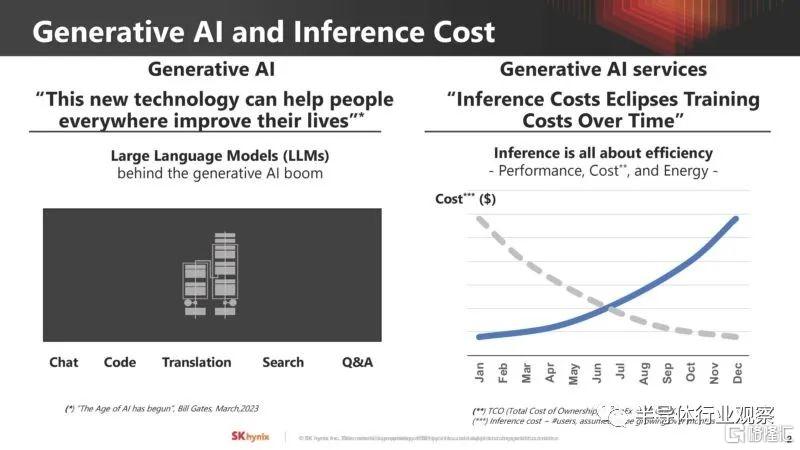
對於大型transformer模型,內存是一個主要挑戰。這些模型需要大量數據,因此通常受到內存容量和帶寬的限制。
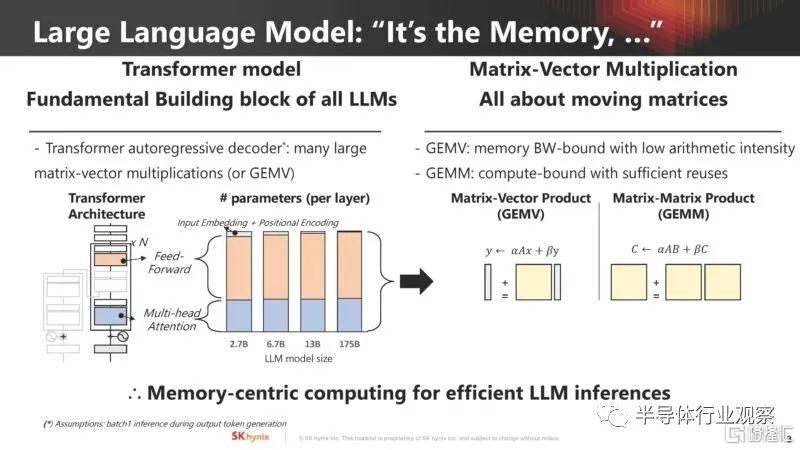
SK 海力士認為,行業需要的不僅僅是內存,還需要不同類型的內存,包括內置計算功能的特定領域內存。三星和 SK 海力士一直致力於成為內存計算提供商,因為這是他們向價值鏈上游移動的方式。
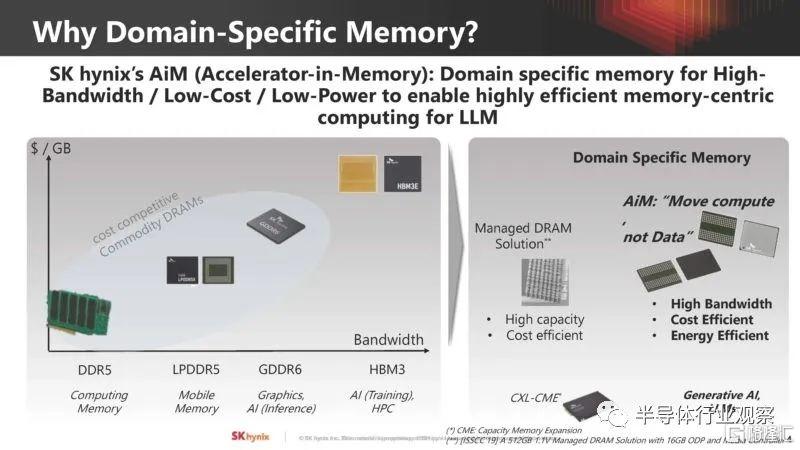
在這一點上,我們將聽到 Accelerator-in-Memory 或 SK hynix AiM。

下面是 GDDR6 內存的外觀,其中有多個內存組,每個內存組都有自己的 1GHz 處理單元,能夠實現 512GB/s 的內部帶寬。

SK hynix 討論了它計劃如何在內存中進行 GEMV 以進行 AI 計算。權重矩陣數據來自bank,而矢量數據來自全局緩衝區。
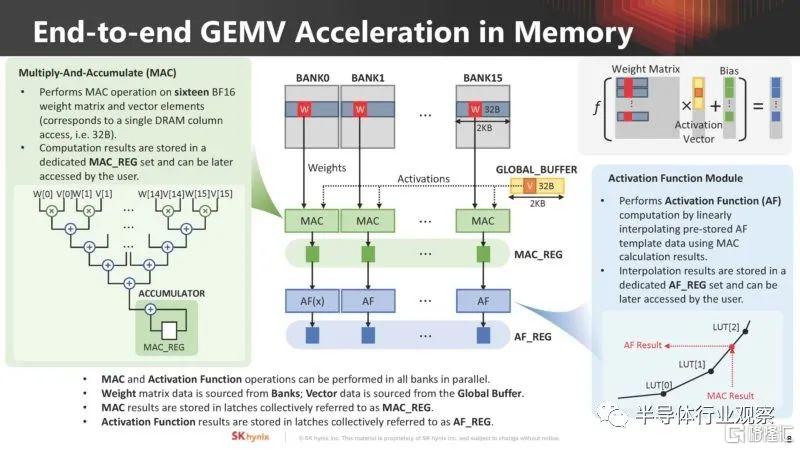
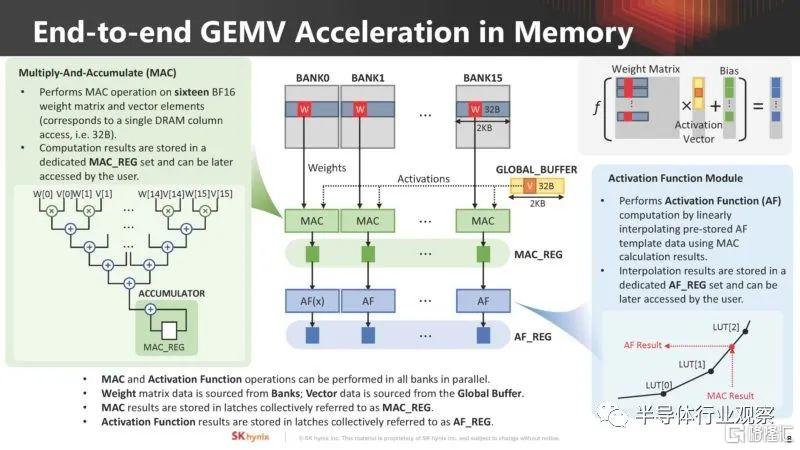
內存計算有特定的 AiM 內存命令。

SK hynix 展示了大型語言模型所需的內存擴展方式以及 AiM 內存計算資源的需求。

以下是大型語言模型 (LLM) 的擴展方式:

使用這種類型的 AiM 面臨的一大挑戰是它需要從軟件端進行映射、為 AiM 構建硬件,然後需要一個接口。這是採用的其他重大障礙之一。

以下是 SK 海力士如何將問題映射到 AiM。

系統架構需要處理縱向擴展和橫向擴展。
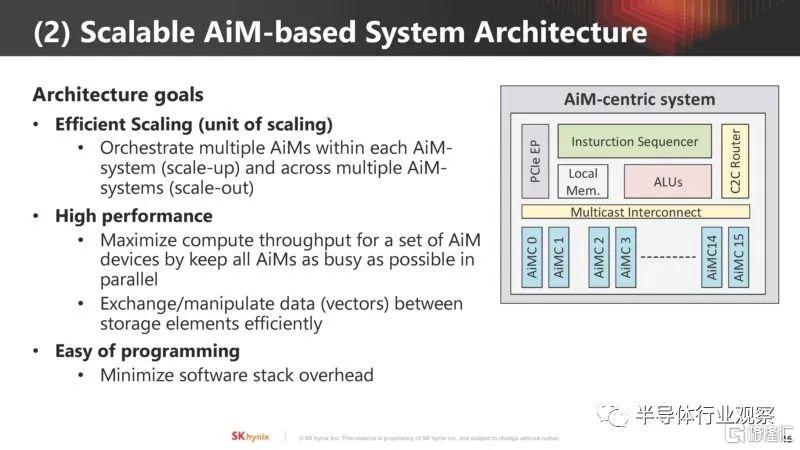
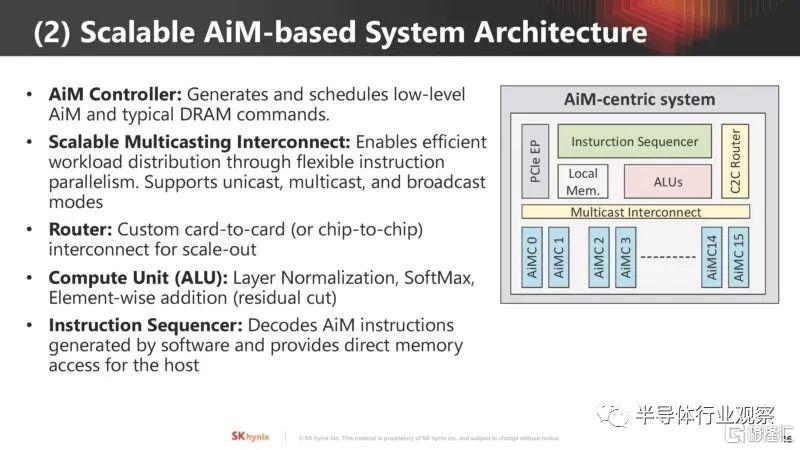
AIM 架構的關鍵組件包括 AiM 控制器、可擴展多播互連、路由器、計算單元 (ALU) 和指令排序器。
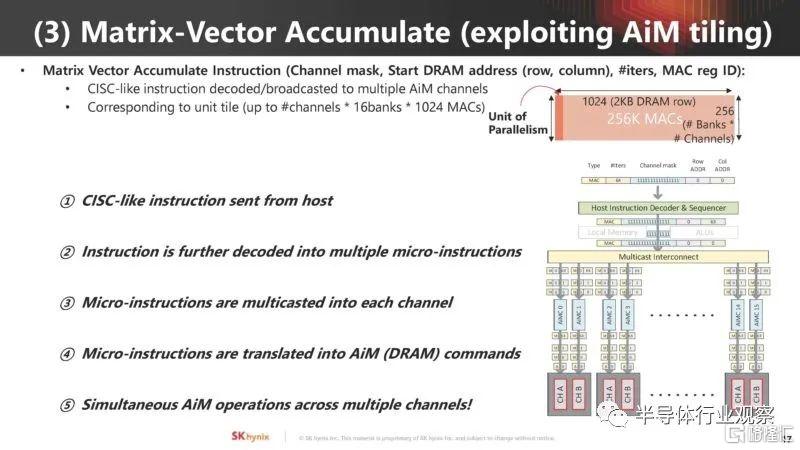
矩陣向量累加函數是 AI 工作負載的關鍵。SK hynix AiM 使用類似 CISC 的指令集來管理此操作。
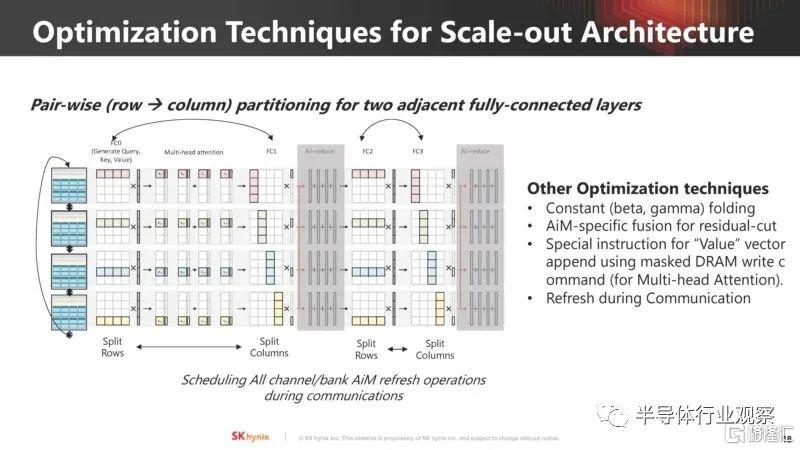
下一步是優化。對於新的架構,通常可以利用一些細微差別來獲得更好的性能。
SK海力士並不只是抽象地談論AiM。相反,它展示了使用兩個 FPGA 的 GDDR6 AiM 解決方案的概念驗證。

它還展示了 AiM 的軟件堆棧。
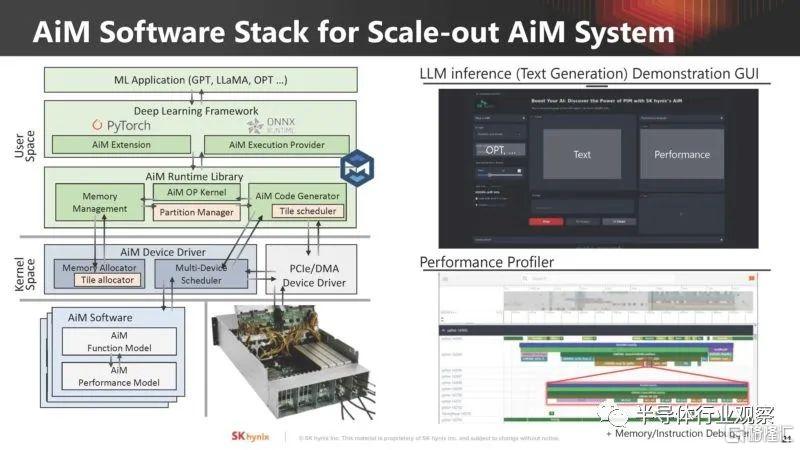
聽起來 SK 海力士並不打算出售這些卡,相反,這些卡似乎是用來證明這個概念的。

SK 海力士仍處於評估階段,對該解決方案與更傳統的解決方案進行不同類型的分析。

SK 海力士和三星多年來一直在談論內存計算。看看未來是否有大客户採用這一點將會很有趣。目前看來,下一代人工智能計算本質上將更加傳統,但這也許是幾年後將會起飛的領域之一。








