本文來自格隆匯專欄:國泰君安證券研究,作者:李沐華、齊佳宏
在最近與投資者的交流過程中,我們發現部分投資者在與大模型相關的幾個關鍵問題上存在一些分歧,故本文希望針對這些問題談談我們的認識。
問題一:哪些場景會是我們需要重點關注的潛在應用場景?
尋找大模型時代的原生應用。目前市場中尋找大模型落地場景的方式基本上是基於以往場景的線性外推,即“怎麼樣把已經能做的事情做得更好”。但事實上,以往的每次技術革新最終都帶來了一些“原生”的產品形態和落地場景。我們認為,相對於對於原有產品的賦能,大模型更大的價值或許在於幫助我們解決一些之前無法解決的問題(包括此前由於技術或成本方面的原因無法解決的問題)。就像移動互聯網的殺手級應用都是在新的時代“原生”的,而不是從PC互聯網遷移過來的。

在等待大模型商業落地的過程中,我們不必過於悲觀。毫無疑問,任何一項技術的商業落地都不是一蹴而就的,並不像部分投資者想得那樣,這個月研發大模型,下個月就直接產生收入。在這個過程中,大模型落地的“慢於預期”實際上更多來自於我們自身心態的變化。就像我們常常聽到的一句話:“當一項技術誕生的初期,我們往往會高估它的短期影響,而低估它的長期影響。”在最初的過度亢奮之後,我們往往又對技術的落地前景過於悲觀。
在報吿《尋找AI技術潛在應用場景的方法論是什麼?》中,我們已經給出了尋找AI潛在落地場景的方法論,這裏不再贅述。僅就一個有意思的問題做補充探討。
在之前的報吿中,在我們從“商業價值的大小”、“數據獲取難度”兩個維度對場景進行了劃分,並指出對於一般公司而言(相對於BAT等互聯網巨頭與科大訊飛等垂域領域巨頭而言),潛在機會可能更多地來自於長尾場景。
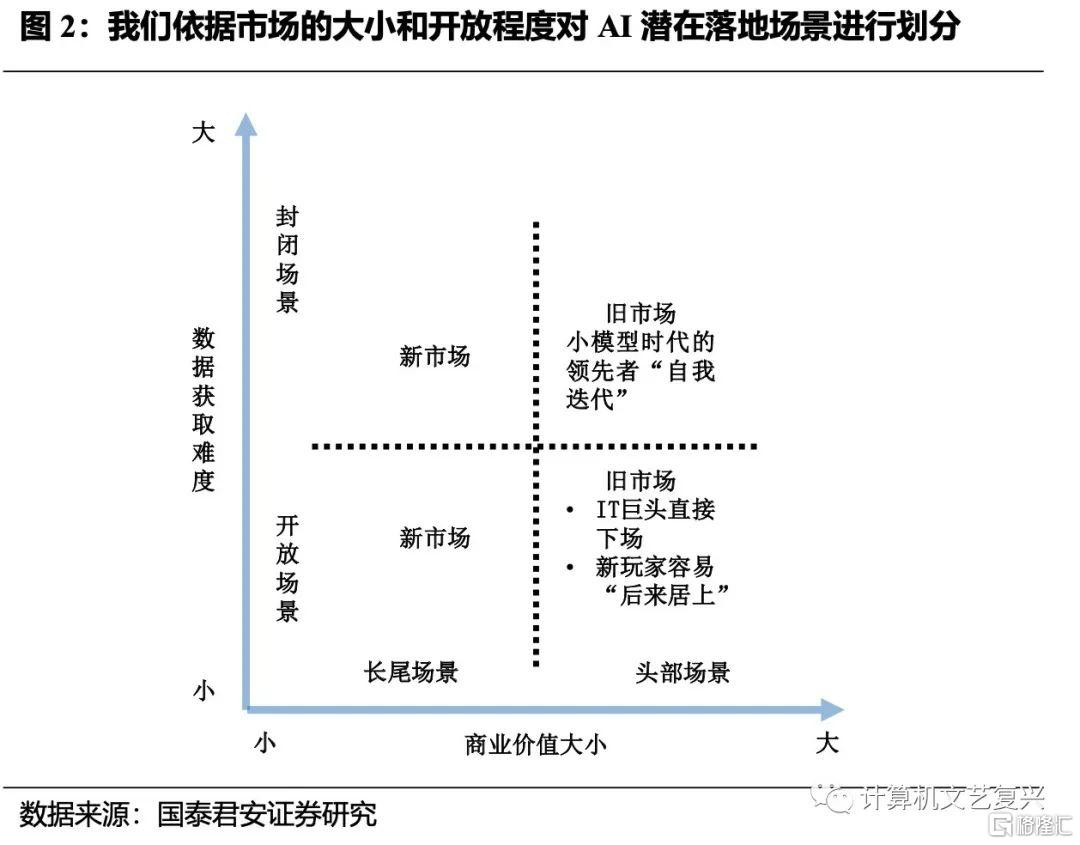
那麼對於“第二象限”,即“封閉場景——長尾場景”象限和第三象限即“開放場景——長尾場景”象限來説,哪類場景是更好的潛在方向呢?我們認為是第二象限。原因在於:
第二象限的“封閉”特性意味着相對於模型能力而言,數據獲取能力更重要,渠道和行業語料的擁有者會有更強的話語權。而對於一個開放性的場景來説,大模型廠商話語權更重。在這類場景中,“被賦能企業”只有不斷產生新的應用創意才能持續保持競爭力,否則就有被大模型廠商吃掉的風險,或面臨市場上同類產品的同質化競爭。而持續產生新的創意顯然並不容易。

問題二:大模型的主要意義是否在於提升解決問題的準確度?
相對而言,提升解決單點問題的準確度或許是大模型帶來的“不那麼重要”的提升。因為無論是大模型還是場景化模型,依然是基於統計學框架,暫時無法徹底解決AI能力的不可解釋性問題,這就意味着它在一些對於corner case敏感的場景下落地仍舊會非常受限。因為本質上來説,這是一個技術和倫理的問題,在這類場景中98%的準確度和95%的準確度並沒有本質差別。
那麼,除了提升準確度之外,大模型的潛力還在於哪些方面呢?
第一,大模型可以幫助我們解決一些此前無法解決的單點問題。這在上文中已有討論,這裏不再贅述。
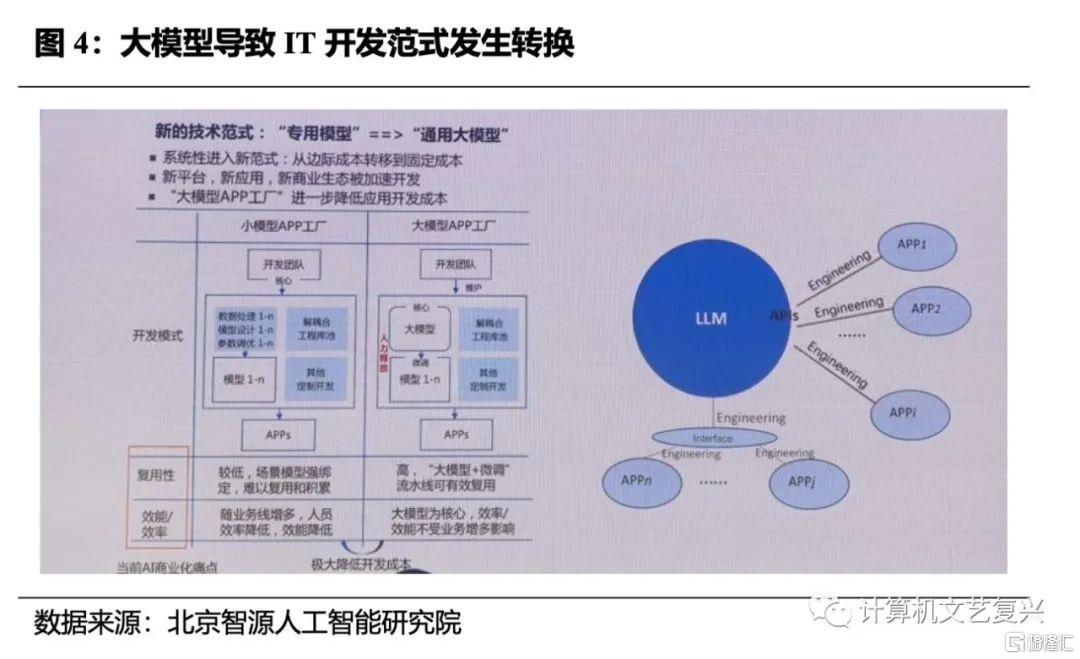
第二,大模型有望徹底改變IT開發範式,提升垂域產品的標準化程度。在很多垂域的場景中,客户的需求雖然大體類似,但仍然存在着一定的差異,比如客户自身的業務流程不同,或是IT建設的側重點不同等等。這就導致在為這些客户進行IT能力建設的時候,會產生大量的定製化工作,使得IT廠商的規模效應大打折扣。隨着大模型的落地,後續客户的數據或將可以通過插件的模式接入大模型,前端的整體交互可以直接通過自然語言的方式來實現,這就意味着一些垂域軟件的標準化程度有望大幅提升。
問題三:“千模大戰”是否意味着每個公司都能做大模型?
最近和投資者的交流中,我們發現了一個非常有意思的觀點:隨着大模型相關的發佈會越來越多,部分投資者直觀上認為每家公司都可以做大模型。
而在我們看來,情況並非如大家所想。構建一個好的大模型仍然有諸多壁壘,包括但不限於:
資本開支:這是最顯而易見的一個壁壘。眾所周知,訓練一個百億參數的大模型,需要幾百張GPU卡,每張卡7萬,那就意味着構建集羣的成本就是千萬到數億元的投入。如果訓練的是千億參數的模型,則需要千卡集羣。很顯然,這方面的投入並不是每個廠商都有實力去做的。而且,在訓練過程中對於雲資源的調用也會消耗大量成本。
工程化能力:目前外界對於GPT系列模型的研究基礎主要基於Open AI關於Instruct GPT的一篇論文。在GPT-3、Instruce GPT及以前的版本中,Open AI對於GPT的技術是完全開源的,而且公開發表的論文中表述非常詳細,包括做GPT模型的思路、所用的數據集是什麼等等。但從達芬奇模型開始(code-davinci-002,2022年Q1左右),GPT系列走向了閉源。單純從技術上來講,Open AI此前已經公開了它的主要思路,那麼為什麼其他廠商暫時還沒有實現完全意義上的復刻?其中一個重要的原因就在於,Open AI不公開它的數據工程方面的信息,比如如何獲取數據,數據訓練是怎麼做的,怎樣投餵到模型中等等。所以,雖然模型本身並沒有那麼強的壁壘,但是如何訓練和處理數據,是包含了非常多的工藝技巧的,也就是我們經常提到的工程化能力。
問題四:大模型所帶來的“技術平民化”趨勢是否會讓場景化模型時代領先的玩家被快速顛覆?
我們認為,並不會。
從技術角度,“模型微調”其實包括兩層內涵。
第一層是用SFT的數據做fine-tune,其中SFT數據就是那些問答對。在這個過程中,模型習得的其實並不是某個行業的深入知識,而是一種更符合人類期望的回答模式。在這個過程中,我們需要的問答對的數量往往不會很大。根據我們產業調研的結果,訓練一種全新的能力,基本上只需要千條級別的問答對。
第二層是在預訓練的過程中,投餵大量的某行業的語料對模型進行進一步地訓練。在這個過程中,為了使得模型掌握該領域的行業知識,我們需要投餵對應領域大量的語料進行訓練,同時還需要保證所投餵語料的質量,否則同樣會影響模型蒸餾的效果。
“模型蒸餾”仍需要一定體量的行業數據。根據我們產業調研的結果,需要同時使用上述兩種方式,才能在把大模型“蒸餾”成行業模型的過程中獲得比較好的效果。這就意味着“模型蒸餾”的過程依然會對行業數據有大量的需求。
而很顯然,並不是每個行業的行業語料都是容易獲得的。在我們此前的報吿中,把這一問題歸結為了“場景開放性”的問題(詳見報吿《AI大航海時代的數字羅盤》),這裏我們僅作簡要陳述。
在開放場景中,“模型蒸餾”所需要的數據可以通過公開手段獲得。包括傳統或者新興的消費電子單品所衍生出來的各種應用,比如手機上的生態軟件、智能音箱上的軟件等等。這些是都是典型的“開放場景”。使用者使用某個產品後數據直接沉澱在了產品終端或後台。
在封閉場景中,數據和特定類型的機構深度綁定,“模型蒸餾”所需要的數據不容易獲得,數據和渠道比模型能力本身更重要。2B或者2G的垂直領域中的很多細分賽道是“封閉場景”,比如醫療、教育、政法、工業等等。在這類場景中,數據是和特定類型的機構深度綁定的,以至於對於新進入者來説數據獲取難度很大,而且難以在短時間內構建起和客户之間的信任關係,“數據獲取能力和渠道優勢”佔據主導,小模型時代的領先者利用大模型實現“自我迭代”的概率更高。
問題五:同時擁有大模型和垂域場景數據的公司有何優勢?
在我們討論大模型對行業賦能的時候,天然就把公司分為了大模型廠商和被賦能廠商兩類。但我們認為,同時擁有大模型和眾多垂域場景數據的公司或更有稀缺性,其競爭優勢至少來自於以下幾個方面:
第一,配合度優勢。
我們認為,雖然目前大模型仍處於“千模大戰”的階段,但隨着時間的推移,必將有絕大多數廠商退出競爭,大模型最終仍將是巨頭的遊戲。這就意味着,最終可以選擇的大模型並不多。
在這個階段,大模型廠商已經建立起了生態、技術、成本等諸多壁壘,話語權隨之上升。在這種情況下,對於某個特定的垂域客户來説,寄希望於大模型廠商針對其進行模型的“蒸餾”和訓練是不切實際的。
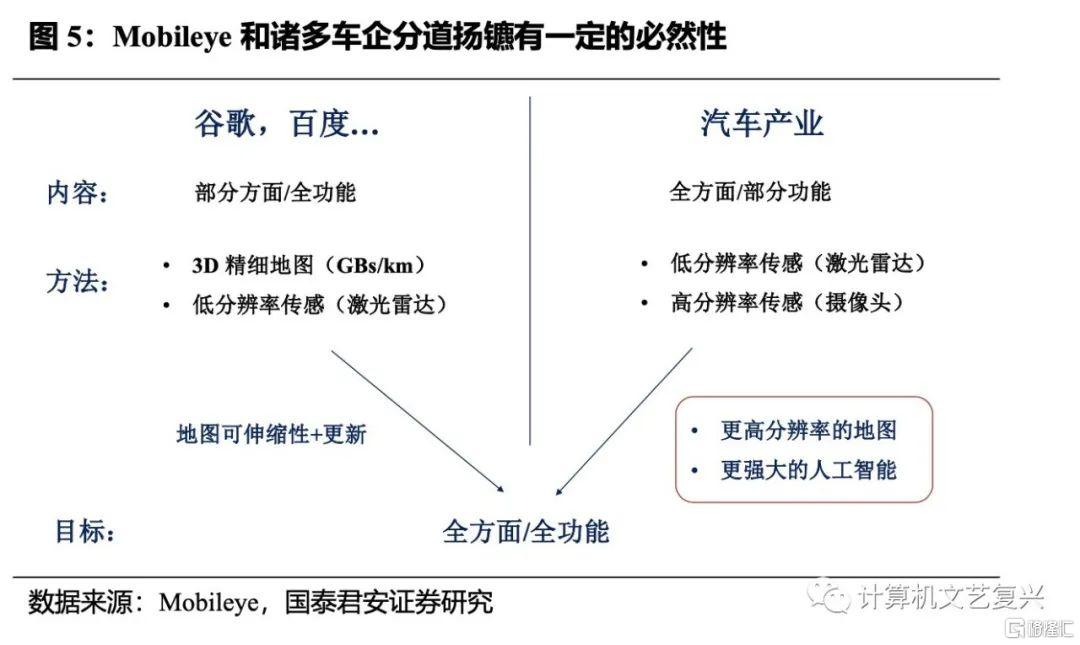
這裏可以引入一個自動駕駛行業的例子進行類比。在ADAS的時代,Mobileye佔據了全球絕大部分的份額,這就意味着它需要同時服務全球諸多的主機廠,不論是從主觀上還是客觀上都難以針對每個主機廠的需求進行及時有效的配合。可以説,正因為在上一個階段的強勢,導致Mobileye在近幾年逐漸式微。
此時,對於同時擁有大模型和垂直行業場景的公司而言,兩個團隊的配合屬於公司內部的資源調度,資源的調配難度明顯更小。
第二,迭代效率的優勢。在利用大模型進行“蒸餾”得到行業模型的過程中,大模型和行業模型之間是存在一定程度的“耦合”的。也就是説,當基礎大模型進行版本更新後,如果不對行業模型進行重新的迭代,最後產生的效果可能會反過來由於大模型的升級而變差。而對於同時擁有大模型和垂直行業場景的公司而言,在迭代效率方面具有明顯優勢。
第三,差異化競爭的優勢。有一句經常被投資者提起的話:“當所有公司都受益時,就意味着可能沒有公司真正受益。”在最初階段,一個垂域場景中的不同公司由於對於大模型的接受程度和接入速度不同,其產品競爭力的對比可能會發生變化。但從長遠來看,在最終勝出的幾家大模型廠商的技術沒有代差的情況下,大模型對於行業格局的影響或趨於弱化。即最終受益者或許是大模型廠商和終端消費者,但垂域廠商在商業上並不一定會受益。而對於同時擁有大模型和垂直行業場景的公司而言,將不需要面對同質化競爭的問題。
注:本文來自國泰君安發佈的《關於AI大模型的五個關鍵問題 | 國君計算機》,報吿分析師:李沐華、齊佳宏
本訂閲號不是國泰君安證券研究報吿發布平台。本訂閲號所載內容均來自於國泰君安證券研究所已正式發佈的研究報吿,如需瞭解詳細的證券研究信息,請具體參見國泰君安證券研究所發佈的完整報吿。本訂閲號推送的信息僅限完整報吿發布當日有效,發佈日後推送的信息受限於相關因素的更新而不再準確或者失效的,本訂閲號不承擔更新推送信息或另行通知義務,後續更新信息以國泰君安證券研究所正式發佈的研究報吿為準。
本訂閲號所載內容僅面向國泰君安證券研究服務簽約客户。因本資料暫時無法設置訪問限制,根據《證券期貨投資者適當性管理辦法》的要求,若您並非國泰君安證券研究服務簽約客户,為控制投資風險,還請取消關注,請勿訂閲、接收或使用本訂閲號中的任何信息。如有不便,敬請諒解。
市場有風險,投資需謹慎。在任何情況下,本訂閲號中信息或所表述的意見均不構成對任何人的投資建議。在決定投資前,如有需要,投資者務必向專業人士諮詢並謹慎決策。國泰君安證券及本訂閲號運營團隊不對任何人因使用本訂閲號所載任何內容所引致的任何損失負任何責任。
本訂閲號所載內容版權僅為國泰君安證券所有。任何機構和個人未經書面許可不得以任何形式翻版、複製、轉載、刊登、發表、篡改或者引用,如因侵權行為給國泰君安證券研究所造成任何直接或間接的損失,國泰君安證券研究所保留追究一切法律責任的權利。