





本文来自格隆汇专栏:中金研究,作者:于钟海 魏鹳霏 等
OpenAI在北京时间2023年3月15日发布了多模态预训练大模型GPT-4,性能更加出色并支持多模态输入,OpenAI也随之发布技术报吿并开源AI模型性能评估框架OpenAI Evals,继续推动模型进步。目前,GPT-4已可在ChatGPT Plus和API调用中使用。
摘要
GPT-4开启多模态时代,接受包含文本和图片的输入,理解能力强大。GPT-4可以根据文本和图片的混合输入生成文本输出(包括自然语言和代码)。在含有文本和照片的文档、图表或屏幕截图等领域中,GPT-4的表现都非常出色,能够理解“梗图”、做计算题以及总结论文。它也可以通过测试时技术(Test-Time Techniques)如few-shot和chain-of-thought prompting进一步扩展能力,图片功能目前仍处研究阶段,暂不对外开放。
高难度阈值与GPT-3.5的对比及基于传统的机器学习基准,GPT-4均效果更佳。相比前代GPT-3.5,GPT-4在处理复杂任务时表现更为出色,在各大面向人类的考试中,GPT-4展示出了更高的准确性、可靠性、创造力和理解能力,比如在Uniform Bar Exam中,ChatGPT的成绩排名在后10%,而GPT-4的百分位在前10%。在传统机器学习的基准测试上,GPT-4比包括SOTA在内的其他大型语言模型表现更优异,MMLU的基准上高出11.2%。在测试的26种语言的24种中,GPT-4优于其他大语言模型的英语性能。GPT-4也已被应用在了在OpenAI内部,例如内容生成、销售和编程,并在模型训练的第二阶段负责输出评估、对齐工作。此外,OpenAI开源了用于评价大语言模型的开源框架OpenAI Evals。这个框架可以帮助研究人员和开发者评估他们的模型,并提供更好的指导。
GPT-4进一步重视安全性,生成回复的正确性得到了重点优化。OpenAI强调对模型进行评估和监控的重要性,以避免潜在的安全隐患。在OpenAI内部的对抗性真实性评估中,GPT-4的得分比GPT-3.5模型高出40%、对不允许内容的请求响应倾向降低了82%、对敏感请求(如医疗建议和自我伤害)的响应相符合政策的程度提高了29%。不足之处在于,GPT-4仍缺乏对其数据截止日期(2021年9月)之后事件的了解,也难以从经验中学习,经过后训练的GPT-4的校准率低于基础预训练模型。
综合来看,GPT-4是大模型进军多模态的重要突破,有望打开应用天花板。我们认为,本次GPT-4发布是“文-图-视频”多模态趋势的向前一步,短期有望催化AI发展生态,长期关注应用端更多可能性。
风险
技术进展不及预期,行业竞争加剧,商业化落地节奏不及预期。
开启多模态时代,理解能力显著增强
相较于GPT-3.5,GPT-4增加多模态能力,更有创造性与协作性。此次发布的GPT-4增加了多模态能力,可以在创意和技术写作任务中与用户一同生成、编辑和迭代,例如创作歌曲、编写剧本或者学习用户的写作风格。除此之外,GPT-4生成的回答准确性更高、理解能力更强、安全性更加可靠、生成内容更加丰富。
图表1:ChatGPT回答GPT-4较GPT-3.5在准确性、推理能力、知识库覆盖等方面显著提升

资料来源:ChatGPT,B站测评,中金公司研究部
相较于只能输入纯文本的GPT-3.5,GPT-4支持通过输入文本和图片组合输出文本,包括带有文本和图像的文档、图表以及截图。GPT-4能够通过为语言模型开发的测试时间技术得到增强,例如少样本和思维链,理解能力更加强大。在OpenAI提供的例子中,GPT-4能够理解“梗图”的幽默、计算物理题、总结论文甚至报税。
图表2:GPT-4按步骤计算一对夫妻的应纳税额

资料来源:OpenAI Live Demo,中金公司研究部
图表3:GPT-4理解“梗图”:VGA线给智能手机充电

资料来源:OpenAI《GPT-4 Technical Report》(March 14, 2023),中金公司研究部
图表4:GPT-4使用思维链提示解决物理题

资料来源:OpenAI《GPT-4 Technical Report》(March 14, 2023),中金公司研究部
GPT-4性能优化提升,准确性再上一层楼
GPT-4在处理复杂、细微任务中表现更加出色,准确性进一步提高。在传统机器学习的基准测试上,GPT-4比包括SOTA在内的其他大型语言模型表现更优异,MMLU的基准上高出11.2%。此外,GPT-4在大多数学术和专业考试中的表现与与人类水平相当,在Uniform Bar Exam中,GPT-4以应试者前10%的分数通过,而GPT-3.5 的得分在倒数10%。同时,GPT-4大幅优化对于跨语种支持的性能,例如GPT-4中文的准确性可以达到80.1%,而GPT-3.5英文的准确性仅为70.1%,对于绝大多数测试语言,GPT-4优于现有语言模型的英语表现。
图表5:GPT-4在传统机器学习标准表现出色

资料来源:OpenAI《GPT-4 Technical Report》(March 14, 2023),中金公司研究部
图表6:GPT-4在人类考试中远超GPT-3.5

资料来源:OpenAI《GPT-4 Technical Report》(March 14, 2023),中金公司研究部
图表7:在测试的26种语言的24种中,GPT-4优于其他大语言模型的英语语言性能
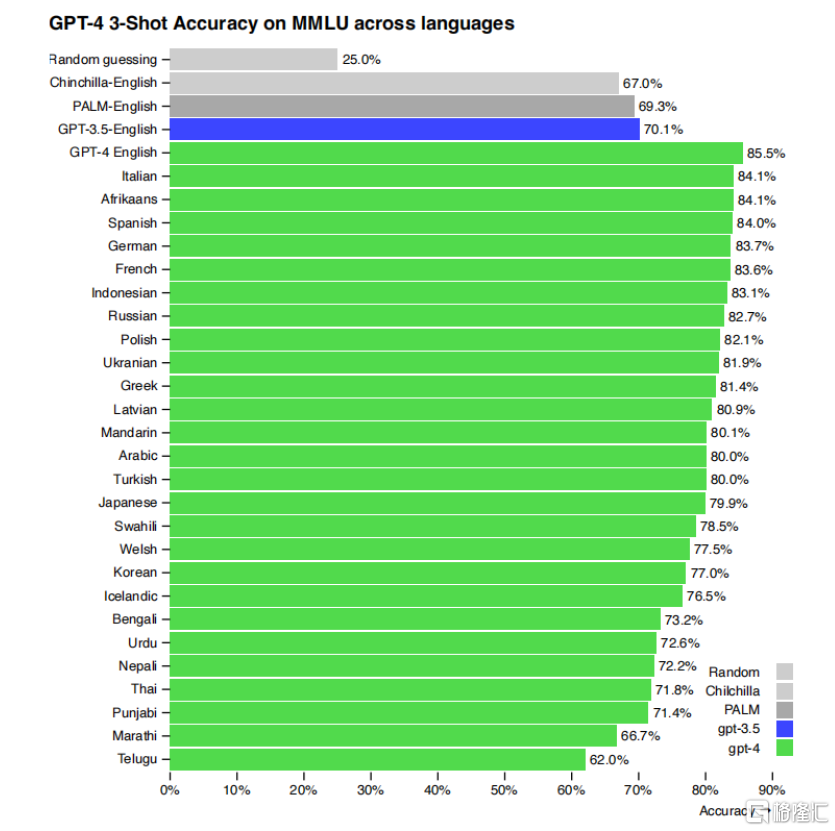
资料来源:OpenAI《GPT-4 Technical Report》(March 14, 2023),中金公司研究部
安全性成为GPT-4优化的重点,风险更加可控
GPT-4的安全性、一致性得到加强,回答更符合人类主流价值观。GPT-4与其他语言模型类似,都会生成有害的建议、有错误的代码或不准确的信息,OpenAI在训练过程中强调对模型进行评估和监控的重要性,以避免潜在的安全隐患。在OpenAI内部的对抗性真实性评估中,GPT-4的得分比GPT-3.5模型高出40%、对不允许内容的请求响应倾向降低了82%、对敏感请求(如医疗建议和自我伤害)的响应相符合政策的程度提高了29%。
图表8:GPT-4对不允许和敏感内容的错误行为率更低

资料来源:OpenAI《GPT-4 Technical Report》(March 14, 2023),中金公司研究部
GPT-4有望打开应用端天花板
GPT-4已经开始在应用端展开合作,涵盖语言、视觉等多领域。OpenAI正在使用GPT-4与一些组织合作开发创新产品,例如Duolingo使用GPT-4进行AI角色扮演与解释答案,Be My Eyes借助GPT-4的视觉输入功能开发虚拟志愿者以生成和人类志愿者相同水平的理解能力,Stripe利用GPT-4精简用户体验并打击欺诈,Morgan Stanley利用GPT-4组织其庞大的知识库。我们认为,GPT-4是大模型进军多模态的重要突破,有望打开多领域应用天花板。
图表9:Duolingo的AI角色扮演

资料来源:OpenAI官网,中金公司研究部
图表10:GPT-4驱动的Stripe文档

资料来源:OpenAI官网,中金公司研究部
本文摘自中金公司2023年3月15日已经发布的《GPT-4到来:性能优化,多模态大幕拉开》,报吿分析师:
于钟海 分析员 SAC 执证编号:S0080518070011 SFC CE Ref:BOP246
魏鹳霏 联系人 SAC 执证编号:S0080121070252 SFC CE Ref:BSX734
王之昊 分析员 SAC 执证编号:S0080522050001 SFC CE Ref:BSS168



实体店
地址:
港铁落马洲站3楼入闸区大堂307号铺
营业时间:
星期一至六: 9:00 am - 9:00 pm
星期日及公众假期:10:00 am - 6:00 pm






