本文來自格隆匯專欄:半導體行業觀察 作者:chipsandcheese
在過去的十年中,ARM CPU廠商多次嘗試打入高性能 CPU 市場,因此我們看到大量關於 ARM 努力的文章、視頻和討論也就不足為奇了,其中許多文章關注的是兩種指令集架構(ISA)的差異。
在本文中,我們將彙集研究、來自非常熟悉 CPU 的人的評論以及我們的一些內部數據,以説明為什麼專注於 ISA 是浪費時間,並讓我們開始在我們的小冒險中,讓我們參考 Anandtech 對 Jim Keller 的採訪,Jim Keller 是一位工程師,他曾參與過多種成功的 CPU 設計,包括 AMD 的 Zen 和 Apple 的 A4/A5。
“關於指令集的爭論是一個非常悲傷的故事。”Jim keller在接受AnandTech採訪時説。
CISC vs RISC:過時的辯論
x86 歷史上被歸類為 CISC(複雜指令集計算)ISA,而 ARM 被歸類為 RISC(精簡指令集計算)。最初,CISC 機器旨在執行更少、更復雜的指令,併為每條指令做更多的工作。RISC 使用更簡單的指令,執行起來更容易、更快。今天,這種區別已不復存在。用Jim keller的話來説:
“RISC 剛問世時,x86 是半微碼(half microcode)。所以如果你看一下die,一半的芯片是 ROM,或者可能是三分之一。從事RISC 人可以説 RISC 芯片上沒有 ROM,因此我們獲得了更高的性能。但是現在ROM太小了,找不到了。其實加法器這麼小,你很難找到嗎?今天限制計算機性能的是可預測性,兩個大的是指令/分支可預測性和數據局部性。”
簡而言之,就性能而言,RISC/ARM 和 CISC/x86 之間沒有有意義的區別。重要的是保持內核的供給,並提供正確的數據,這些數據專注於緩存設計、分支預測、預取以及各種很酷的技巧,比如預測加載是否可以在存儲到未知地址之前執行。
在2013 年,Blem 等研究人員發現了一種方法。研究了 ISA 對各種 x86 和 ARM CPU [1]的影響,發現 RISC/ARM 和 CISC/x86 在很大程度上已經收斂。
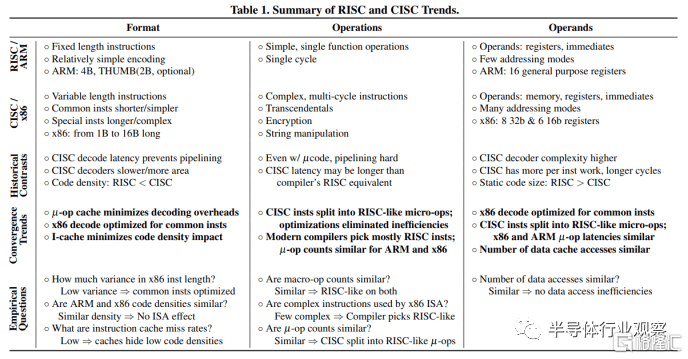
來自威斯康星大學論文的表格,顯示了 RISC/ARM 和 CISC/x86 之間的收斂趨勢
Blem等人得出的結論是,ARM 和 x86 CPU 在功耗和性能方面存在差異,主要是因為它們針對不同的目標進行了優化。指令集在這裏並不重要,重要的是實現指令集的 CPU 的設計:
他們研究的主要發現是:
儘管平均週期計數差距 <= 2.5 倍,但實現之間存在很大的性能差距。
指令計數和混合與一階 ISA 無關。
性能差異是由獨立於 ISA 的微架構差異產生的。
能耗再次與 ISA 無關。
ISA 差異具有實施意義,但現代微架構技術使它們沒有實際意義;一個 ISA 從根本上説並不是更有效。
ARM 和 x86 實現只是針對不同性能級別優化的設計點
以上觀點來自論文《Power Struggles: Revisiting the RISC vs. CISC Debate on Contemporary ARM and x86 Architectures》
換句話説,ARM ISA 與低功耗沒有任何關係。同樣,x86 ISA 與高性能無關。我們今天熟悉的基於 ARM 的 CPU 恰好是低功耗的,因為 ARM CPU 的製造商將他們的設計定位於手機和平板電腦。英特爾和 AMD 的 x86 CPU 以更高的性能為目標,具有更高的功率。
為了給 ISA 發揮重要作用的想法潑冷水,英特爾以基於 x86 的 Atom 內核為目標。Federal University of Rio Grande do Sul [6] 進行的一項研究得出結論:“對於所有測試用例,基於 Atom 的集羣被證明是在低功耗處理器上使用多級並行性的最佳選擇。”
正在測試的兩種內核設計是 ARM 的 Cortex-A9 和英特爾的 Bonnell 內核。有趣的是,Bonnell 是一種有序設計,而 Cortex-A9 是一種無序設計,應該為 Cortex-A9 帶來性能和能源效率的勝利,但在研究中使用的測試中,Bonnell 出現了在這兩個類別中都領先。
解碼器差異:杯水車薪
另一個經常重複的真理是 x86 有一個顯著的“ecode tax”障礙。ARM 使用固定長度的指令,而 x86 的指令長度不同。因為您必須在知道下一條指令從哪裏開始之前確定一條指令的長度,所以並行解碼 x86 指令更加困難。這對於 x86 來説是一個缺點,但對於高性能 CPU 來説,這並不重要,用 Jim Keller 的話來説:
“有一段時間我們認為可變長度指令真的很難解碼。但我們一直在想辦法做到這一點。.所以當你在建造小型電腦時,固定長度的指令看起來真的很好,但如果你正在建造一台非常大的電腦,預測或找出所有指令的位置,它並沒有支配die。所以沒那麼重要。”
我們深入並親自對此進行了檢查。
通過未記錄的 MSR 禁用 op 緩存後,我們發現 Zen 2 的 fetch 和 decode 路徑比 op cache 路徑消耗大約 4-10% 的核心功率,或 0.5-6% 的封裝功率。在實踐中,解碼器將消耗更少的核心或封裝功率。Zen 2 並非設計為在禁用微操作緩存的情況下運行,並且我們使用的基準 (CPU-Z) 適合 L1 緩存,這意味着它不會對內存層次結構的其他部分造成壓力。對於其他工作負載,來自 L2 和 L3 高速緩存以及內存控制器的功耗將使解碼器的功耗變得不那麼重要。
事實上,在禁用 op 緩存的情況下,一些工作負載的功耗降低了。解碼器的功耗被其他核心組件的功耗所淹沒,特別是如果操作緩存讓它們得到更好的饋送。這與Jim Keller的評論一致。
研究人員也同意這個觀點。
2016 年,Helsinki Institute of Physics[2]支持的一項研究着眼於英特爾的 Haswell 微架構。在那裏,Hiriki 等人估計,Haswell 的解碼器消耗了 3-10% 的封裝功率。該研究得出的結論是,“x86-64 指令集並不是生產節能處理器架構的主要障礙。”

Hiriki 等人使用綜合基準開發模型來估計單個 CPU 組件的功耗,並得出結論認為解碼器功耗很小
在另一項研究中,Oboril 等人 [5] 在 Intel Ivy Bridge CPU 上測量獲取和解碼能力。雖然那篇論文專注於為核心組件開發一個準確的功率模型,並沒有直接得出關於 x86 的結論,但它的數據再次表明解碼器的功率是滄海一粟。
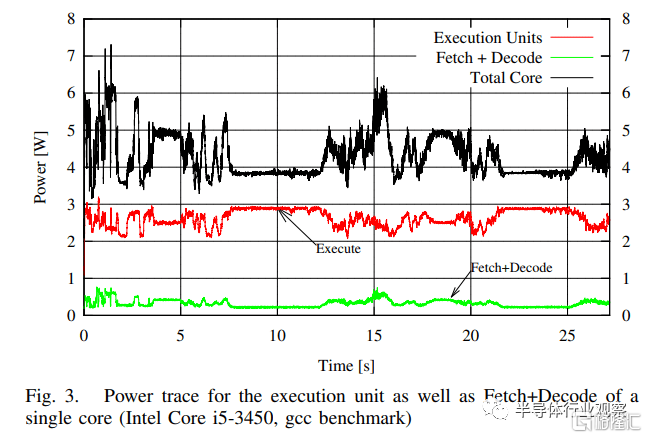
Oboril 等人對 Ivy Bridge 功耗的估計。與其他核心組件相比,Fetch+Decode 的能力微不足道
但顯然解碼器功率不是零,這意味着它是一個潛在改進的領域。畢竟,當您受到功率限制時,每一瓦特都很重要。即使在台式機上,多線程性能也常常受到功率的限制。我們已經看到 x86 CPU 架構師使用 op 緩存來提供每瓦性能,所以讓我們從 ARM 方面看一下。
ARM 解碼也很貴
Hirki 等人還得出結論:“切換到不同的指令集只會節省少量功率,因為在現代處理器中無法消除指令解碼器。”
ARM Ltd 自己的設計就是證明。高性能 ARM 芯片採用微操作緩存來跳過指令解碼,就像 x86 CPU 一樣。2019 年,Cortex-A77 引入了 1.5k 條目操作緩存[3]。設計運算緩存並非易事——ARM 的團隊在至少六個月的時間裏調試了他們的運算緩存設計。顯然,ARM 解碼的難度足以證明花費大量工程資源儘可能跳過解碼是合理的。Cortex-A78、A710、X1 和 X2 還具有運算緩存,表明該方法在蠻力解碼方面取得了成功。
三星還在其 M5 上引入了運算緩存。在一篇詳細介紹三星 Exynos CPU [4]的論文中,解碼能力被稱為實現操作緩存的動機:
“隨着設計從 M1 中的每個週期提供 4 條指令/微指令變為 M3 中的每個週期 6 條(未來的目標是增長到每個週期 8 條),獲取和解碼能力是一個重要的問題。M5 實現添加了一個微操作緩存作為替代 uop 供應路徑,主要是為了節省可重複內核的獲取和解碼能力。”——《Evolution of the Samsung Exynos CPU Microarchitecture》
就像 x86 CPU 一樣,ARM 內核使用 op 緩存來降低解碼成本。ARM 的“解碼優勢”並不足以讓 ARM 避免操作緩存。並且操作緩存將減少解碼器的使用,使解碼功率變得更不重要。
ARM指令解碼成微操作?
Gary Explains 在標題為“ RISC vs CISC– Is it Still a Thing ? “,他在隨後的視頻中重複了這一説法。
Gary 是不正確的,因為現代 ARM CPU 還將 ARM 指令解碼為多個微操作。事實上,“減少微操作擴展”使 ThunderX3 的性能比 ThunderX2 提高了 6%(Marvell 的 ThunderX 芯片都是基於 ARM 的),這比故障中的任何其他原因都要多。
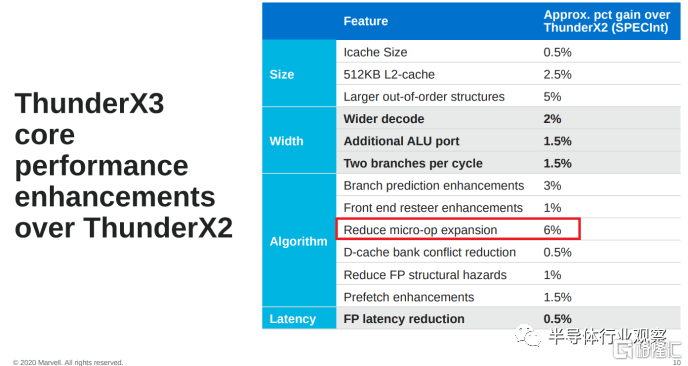
Marvell 在 Hot Chips 2020 上展示的幻燈片。重點(紅色輪廓)由我們添加
我們還快速瀏覽了富士通 A64FX 的架構手冊,這是為日本 Fugaku 超級計算機提供動力的基於 ARM 的 CPU。A64FX 還將 ARM 指令解碼為多個微操作。

A64FX 架構手冊中的部分指令表,位於 ARMv8 基本指令部分。我們在解碼到多個微操作的指令上添加的重點(紅色輪廓)
如果我們深入看,一些 ARM SVE 指令會解碼為數十個微操作。例如,FADDA(“浮點加法嚴格有序歸約,以標量累加”)解碼為 63 個微操作。其中一些微操作單獨具有 9 個週期的延遲。對於在單個週期中執行的 ARM/RISC 指令來説,就這麼多了……
另外需要注意的是,ARM 並不是一個純粹的加載存儲架構。例如,LDADD 指令從內存中加載一個值,添加到它,然後將結果存儲回內存。A64FX 將其解碼為 4 個微操作。
x86 和 ARM:都因遺留問題而臃腫
這對他們中的任何一個都沒有關係。
在 Anandtech 的採訪中,Jim Keller 指出,隨着軟件需求的發展,x86 和 ARM 都隨着時間的推移增加了功能。當它們進入 64 位時,兩者都得到了一些清理,但仍然是經過多年迭代的舊指令集,迭代不可避免地會帶來臃腫。
Keller 好奇地指出,RISC-V 沒有任何歷史遺留文呢提,因為它“處於複雜性生命週期的早期”。他繼續:
“如果我今天想真正快速地構建一台計算機,並且我希望它能夠快速運行,那麼 RISC-V 是最容易選擇的。它是最簡單的一個,它具有所有正確的功能,它具有您實際需要優化的正確的前八條指令,而且它沒有太多的垃圾。”
如果遺留膨脹起重要作用,我們可以期待很快會出現 RISC-V 的猛攻,但我認為這不太可能。舊版支持並不意味着舊版支持必須快速;它可以進行微編碼,從而最大限度地減少芯片面積的使用。就像可變長度指令解碼一樣,這種開銷在現代高性能 CPU 中不太重要,因為芯片區域由緩存、寬執行單元、大型亂序調度程序和大型分支預測器主導。
結論:實施很重要,而不是ISA
我很高興看到來自 ARM 的競爭,因為高端 CPU 空間需要更多玩家,但由於指令集差異,ARM 玩家並沒有超越 Intel 和 AMD。要贏得勝利,ARM 製造商將不得不依靠其設計團隊的技能。或者,他們可以通過針對特定的功率和性能目標進行優化來超越英特爾和 AMD。AMD 在這裏尤其容易受到攻擊,因為它們使用單核設計來涵蓋從筆記本電腦和台式機到服務器和超級計算機的所有內容。