





本文來自格隆匯專欄:中金研究 作者:鄭欣怡 陳昊等
中金研究認為AI大模型快速發展,新投資需求有望驅動算力指數級增長。處理器與處理器間、處理器與存儲間的數據交互將更加頻繁,也對接口傳輸速率提出更高要求。服務器內板上通信技術迎來大規模升級,這將推動接口通信芯片、封裝技術以及PCB材料等規格大幅提升,帶來新的市場機遇。
摘要
PCIe總線持續升級,NVLink引領服務器內部通信新變革。PCIe平均每三年升級一代標準,目前市場呈現多世代並存局面,中金研究認為在高性能服務器需求高增趨勢下,CPU迭代有望加速PCIe 5.0大規模商用進程;同時,PCIe Retimer和Switch芯片在高速PCIe通路中發揮重要作用,市場空間可期。在AI異構計算場景中,算力的持續增強不僅依賴單張GPU卡的性能提升,還需要多卡高效聚合,NVLink成為實現多GPU間高速互聯的關鍵通道,並引入基於NVLink高級通信能力構建的NVSwitch芯片以解決GPU間通訊不均衡問題,進而構成全帶寬連接的多節點GPU集羣。
先進封裝技術不斷進階,ABF載板景氣提升。眾核異構方案推動先進封裝技術向更高連接密度演進,全球先進封裝需求呈增長態勢,其中Fan-out、2.5D/3D封裝市場增速領跑行業。從先進封裝材料看,中金研究認為ABF載板作為CPU、GPU等高運算性能芯片的重要承載,有望受益於AI浪潮帶來的高算力芯片需求激增;同時,Chiplet異構集成下裸片間連接需求增加,ABF載板面積增加、且載板消耗量因良率下降而增加,先進載板需求進一步向上。
PCB高速化帶動板材升級,上游樹脂材料有望向PPO切換。得益於服務器平台持續迭代、疊加以更高端PCB為算力載體的AI服務器需求高升,中金研究認為由M6及以上覆銅板材料製成的超過16層的PCB有望在服務器市場中快速滲透,PCB板有望迎來量價齊升。聚焦覆銅板上游樹脂材料,中金研究看好聚苯醚(PPO)憑藉改性後優異的電化學性能(低介電損耗、高加工穩定性、耐熱性等)逐步取代傳統樹脂,在下游高端服務器需求增長、覆銅板高頻高速化發展的驅動下,改性PPO市場增長空間廣闊。
風險
AI商業落地進展不及預期的風險,雲廠商算力相關資本開支不及預期。
正文
AI高算力需求牽引服務器內高速通信技術迭代升級
AI大模型迭出帶來數據處理量指數級增長,帶動AI雲端算力需求快速拉昇。自2022年下半年以來AIGC(AI-Generated Content,人工智能生成內容)實現技術和產業端的快速發展。以OpenAI GPT系列的版本演進為例,從GPT-1(2018.06)到GPT-2(2019.02)、GPT-3(2020.05)、GPT-3.5(2022.11)、GPT-4(2023.03),參數量和語料庫持續升級。目前AI超大模型的參數已經達到千億、甚至萬億數量級,且在訓練過程中,各類中間變量均需要存儲,以上海量數據對訓練場景下的算力和顯存需求均提出了高要求。中國信通院預計,2030年全球算力總規模有望達到56ZFlps,2021-2030年CAGR約65%,其中智能算力貢獻主要增長動能。
圖表1:大模型參數量對比
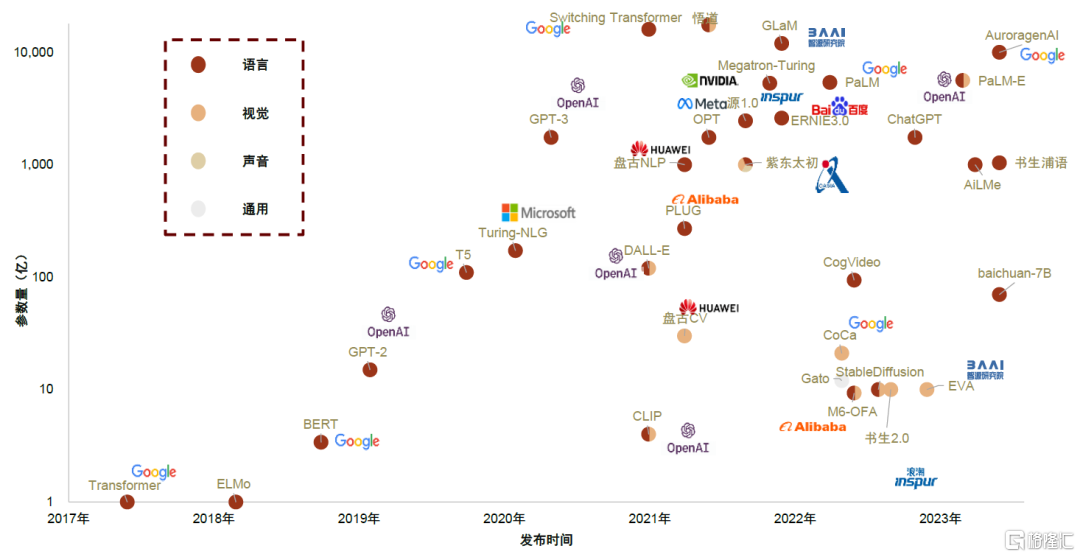
注:截至2023年6月 資料來源:北京智源人工智能研究院,中金公司研究部
服務器內部各種高速連接需求大幅增長,需要承載量更大的傳輸通道作為支撐。中金研究觀察到,GPT-3.5模型訓練所使用的微軟Azure AI雲計算平台採用了分佈式訓練“多卡多機”的模式,涉及大量數據在GPU之間、GPU與CPU、GPU與內存等單元之間的傳輸,並增加了跨服務器的通信需求,服務器內部板上通信技術迎來大規模升級。此外,AI算力的提升方式,除了依靠單體GPU卡的算力迭代,還需要高速的芯片互聯技術作為有力支撐,從而實現多顆GPU之間的高效聚合、提升GPU算力的可擴展性,進而形成強大的集羣算力。中金研究認為,為提升異構並行處理超大數據量的效率,板上芯片間互聯、片內Die間互聯總線均需升級。
主板總線:板內數據運送的管道
PCIe:服務器內主流總線,不斷向高規格演進
總線是服務器主板傳輸數據的通路。總線負責CPU與PCH(Platform Controller Hub,平台管理器中樞)、PCH與功能芯片之間的連接,其類型包括QPI、PCIe、DMI、SATA、SAS、SPI、USB等。其中,CPU與CPU之間通過QPI總線進行通信,CPU與PCIe設備通過PCIe總線連接,PCH與USB、SATA硬盤、SAS硬盤和網卡分別通過USB總線、SATA總線、SAS總線、PCIe總線連接,CPU與內存之間通過內存總線連接。
圖表2:以CPU為核心的服務器主板架構與各類總線
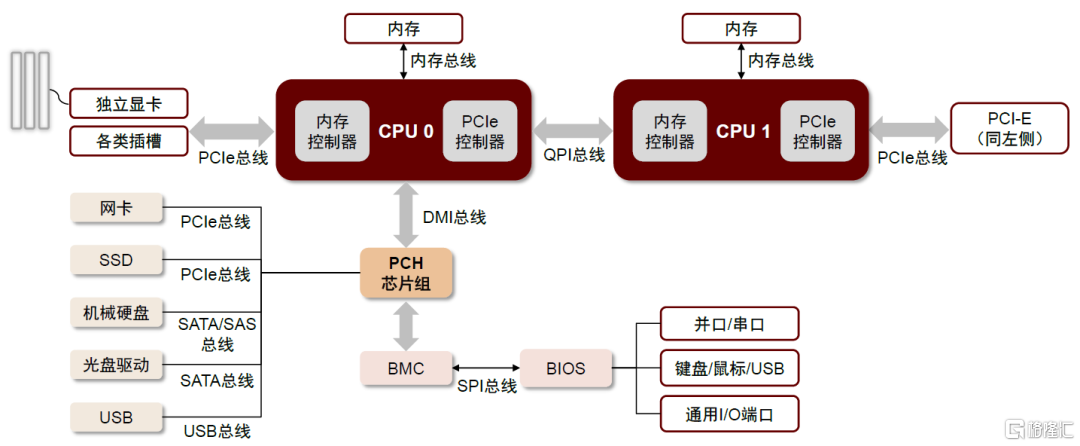
資料來源:CSDN,中金公司研究部
► QPI(Quick Path Interconnect,快速通道互聯):取代前端總線FSB(Front Side Bus)的一種串行式高速點對點連接協議,用於連接CPU、內存控制器和其他處理器組件,還可以實現多個處理器之間的直接互聯和快速通信,具有高帶寬、低功耗、支持熱插拔的特點。
► PCIe(Peripheral Component Interconnect Express,高速串行擴展總線):PCIe主要用於連接CPU與各類高速外圍設備,如GPU、SSD、網卡、顯卡等。相比於上一代採用並行架構的PCI總線,PCIe通過多對高速串行的差分信號進行高速傳輸,其所連接的設備均獨享通道帶寬,可以使用更高的時鐘頻率、更少的信號線和更高的總線帶寬,因此PCIe總線的傳輸效率更高、功耗更低、可擴展性更強,已取代PCI成為服務器中最廣泛使用的系統總線。
► Memory Bus(內存總線):用來實現處理器和內存之間的連接,處理器內集成的內存控制器可以通過內存總線和內存模組進行尋址、讀寫等通訊。DDR即一種內部總線,其版本與內存的頻率和帶寬相關。
► DMI(Direct Media Interface,直接媒體接口):最初用於連接主板南北橋芯片,目前負責CPU和PCH主板芯片組之間的通信。由於DMI是基於PCIe總線協議進行傳輸,因此具有PCIe的優勢。
PCIe的傳輸速率與通道數有關。一般來説,每個PCIe Lane(通道)由一對差分信號組成,發送和接收同時進行,一個發送方向的差分信號包含TX+和TX-兩條數據線,因此一條Lane(也稱為x1)有四根數據線。PCIe連接可以通過增加通道數擴展端口總帶寬,目前有PCIe x1、PCIe x2、PCIe x4、PCIe x8、PCIe x16、PCIe x32六種插槽配置,對應1/2/4/8/16/32通道,插槽長度也隨着通道數的增加而拉長。
PCIe具有良好的向後兼容性,平均每三年升級一代標準,單通道速率翻倍增長。根據PCI-SIG官網,伴隨人工智能、自動駕駛、AR/VR等具有高運算要求的應用快速發展,處理器I/O帶寬每三年實現翻番,也促使PCIe基本上按照3年一代的速度更新演進,數據傳輸速率呈現垂直性增長態勢,先行於I/O帶寬需求增長。PCIe最早由Intel於2001年提出,2003年正式推出PCIe 1.0版本,到2022年已迭代至6.0。6.0版本是PCIe問世以來變化最大的一代,相較於PCIe 5.0其突出變化有:1)單通道數據速率從32GT/s翻倍至64GT/s;2)信號調製方式從NRZ轉向PAM4,可以在單個通道、同樣時間內封包更多數據;3)引入FLIT(流控單元)將數據分解為固定大小的數據包,提高了帶寬效率。2022年6月,PCI-SIG聯盟宣佈PCIe 7.0版規範,單條通道(x1)單向可實現128GT/s傳輸速率,計劃於2025年推出最終版本。
圖表3:PCIe技術發展路線及不同版本規格參數
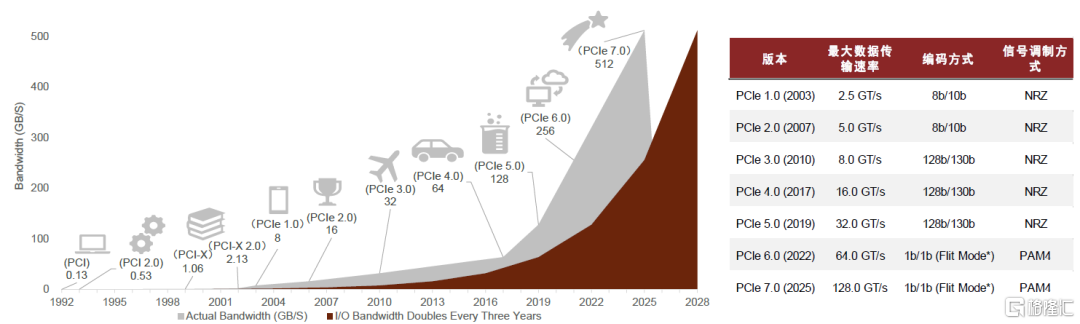
注:Flit Mode*表示流控單元模式,以Flit為最小單位進行數據傳輸 資料來源:PCI-SIG官網,中金公司研究部
從產品落地看,多世代並行競爭,CPU迭代加速PCIe 5.0大規模商用。以PCIe SSD為例,市場呈現出多版本並存的局面,根據Forward Insights(3Q21)數據,2021年PCIe 3.0、4.0在所有數據中心PCIe SSD市場中的份額分別為81%和19%,Forward Insights預測,隨着PCIe 4.0系統生態逐漸構建以及成本下探,到2025年PCIe 4.0的滲透率有望達到77%。同時,各大CPU廠商積極佈局PCIe 5.0硬件平台,英特爾率先在其Alder lake平台上採用支持PCIe 5.0標準的處理器,2023年1月又推出支持PCIe 5.0總線的最新一代CPU平台Sapphire Rapids;AMD於2022年推出支持PCIe 5.0的第四代EPYC處理器Genoa。展望未來,中金研究認為短期來看PCIe 4.0與5.0高低規混合應用仍是市場主流,通用型主機與周邊裝置使用成本較低的PCIe 4.0,PCIe 5.0則率先在數據吞吐量更高的高性能服務器市場中發揮主流價值,但隨着CPU不斷迭代升級,PCIe 5.0大規模商用進程或有望加速。
圖表4:2005-2023年CPU龍頭廠商CPU平台演進情況

資料來源:Intel官網,AMD官網,中金公司研究部
Retimer和Switch芯片為PCIe技術錦上添花
PCIe標準迭代過程中信號插損也隨之增加,引入信號調理技術可有效改善信號質量。PCIe速率持續翻倍增長,但受限於工業標準,服務器主板尺寸的延展空間有限,導致全鏈路的插損預算從PCIe3.0標準下的22dB增加到了PCIe 5.0標準下的36Db@16GHz(包括CPU和AIC芯片封裝在內的端到端總鏈路損耗)。為應對愈演愈烈的信號插損問題,PCIe從4.0時期開始引入信號調理芯片:1)PCIe Retimer:Retimer是一種數模混合器件,其工作原理是通過內部嵌有的時鐘數據恢復(CDR)電路提取輸入信號中的嵌入式時鐘,再使用未經衰減變形的時鐘信號重新傳輸數據,從而提升信號完整性並消除信號抖動影響。2)PCIe Redriver:通過發射端的驅動器和接收端的濾波器提升信號強度,從而實現對信號損耗的補償。對比來看,Retimer的功能原理更加複雜,能夠實現比Redriver更優的降低信道損耗效果,但由於增加了數據處理過程時延有所拉長。
圖表5:PCIe Redriver和PCIe Retimer原理對比

資料來源:TI官網,中金公司研究部
人工智能發展大幅增加高速數據傳輸需求,PCIe Retimer滲透率有望進一步提升。Retimer芯片能夠提升服務器、企業存儲、異構計算和通信系統中數據傳輸時信號的完整性,典型應用場景包括NV Me SSD、AI服務器、Riser Card等。根據Astera Labs公司官網,一台8卡GPU的AI服務器可配置8顆PCIe 4.0 Retimer芯片,主要用於提升GPU與CPU之間、CPU與SSD之間信號通訊的穩定性。中金研究認為,在AI大模型及應用快速發展的浪潮下,AI服務器市場有望維持高景氣度、且服務器內部高速硬件數據交互需求將不斷增長,PCIe Retimer憑藉更好的降低通道物理損耗的效果,在AI服務器和存儲系統的應用比率有望顯著提升,逐漸成為行業主流方案。
圖表6:PCIe Retimer芯片在服務器中的多應用

資料來源:瀾起科技公司官網,中金公司研究部
圖表7:PCIe Retimer芯片在AI服務器中的配置情況
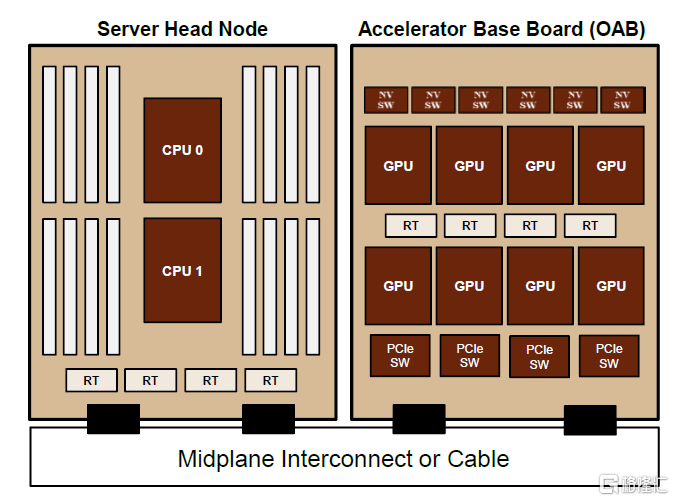
注:圖中RT即PCIe Retimer芯片
資料來源:Astera Labs公司官網,中金公司研究部
PCIe Switch兼具連接、交換功能,有效拓展PCIe鏈路。PCIe採用端到端的連接方式,因此每一條PCIe鏈路兩端只能各連接一個設備,在需要高速數據傳輸和大量設備連接的場景中連接數量和速度受限。PCIe Switch芯片能夠將多條PCIe總線連接在一起,形成一個高速的PCIe互聯網絡,從而實現多設備通信,具有高可拓展性、低功耗、低延遲、高可靠性、高靈活性等優勢,廣泛應用於機器學習、人工智能、超融合部署和存儲系統中。從PCIe Switch內部結構看,其由多個PCI-PCI橋接構成,實現從單條線到多條線的發散。中金研究認為,AI高算力場景推升高速數據互聯需求,PCIe Switch作為數據中心低功耗、高性能解決方案的核心一環有望迎來高增長。根據Transparency市場調研機構數據,2027年全球PCIe Switch市場規模或將達到92億美元,2019-2027年CAGR約15%。
圖表8:PCIe Switch連接多條PCIe總線
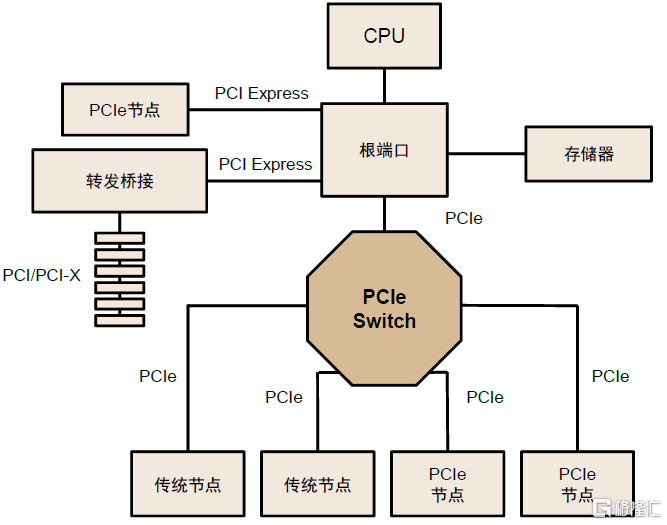
資料來源:PCI-SIG官網,中金公司研究部
NVLink、Infinity Fabric等新技術賦能AI異構計算場景
以CPU+GPU為代表的異構並行計算架構廣泛應用於AI/HPC場景。CPU(中央處理器)大部分面積用於邏輯控制單元和存儲,計算單元只佔小部分,因此並行計算能力受到較大限制;而GPU(圖形處理器)比CPU擁有更多的算力邏輯單元,適合密集型數據的並行處理。在AI雲端場景下,運算對象是大量類型統一的數據,以並行運算為主,採用CPU+GPU異構計算架構能夠滿足海量數據的處理需求,CPU與GPU協同工作,CPU主要負責控制和管理系統的整體運行,而GPU則用於執行高度並行的計算任務。
多GPU間通信時PCle或存在帶寬瓶頸,新互聯技術應運而生。算力的持續增強不僅依靠單張GPU卡的性能提升,往往還需要多GPU卡組合。在多GPU系統內部,GPU間通信的帶寬通常在數百GB/s以上,PCIe總線的數據傳輸速率容易成為瓶頸,且PCIe鏈路接口的串並轉換會產生較大延時,影響GPU並行計算的效率和性能,其他專用互聯技術應運而生,如英偉達提出的NVLink、AMD提出的Infinity Fabric等。根據英偉達官網,對比基於PCIe的系統,基於NVLink的系統在交換/排序/3D FTT性能上分別提升約5倍、1.4倍、2倍。
NVLink+NVSwitch:實現GPU間高速互聯的關鍵使能者
NVLink是GPU之間通信所採用的點對點互聯協議,與GPU體系同步演進。英偉達針對異構計算場景於2016年開發了NVLink技術,NVLink通過GPU之間的直接互聯,可擴展服務器內的多GPU輸入/輸出(I/O),提供相較於傳統PCIe總線更加快速、更低延遲的系統內互聯解決方案。第一代NVLink搭載在基於Pascal架構的NVIDIA P100 GPU上,傳輸速率為160GB/s,之後隨着NVIDIA GPU體系結構的演進而同步迭代升級。根據英偉達官網,目前NVLink已迭代至第四代,可為多GPU系統配置提供高於以往1.5倍的帶寬以及更強的可擴展性,單NVIDIA H100 Tensor Core GPU中包含18條第四代NVLink鏈路,總帶寬達到900 GB/s,是PCIe 5.0帶寬的7倍。
NVSwitch是NVLink技術的延伸,解決GPU間通訊不均衡問題。在DGX P100架構中,8個GPU通過NVLink形成環狀連接,無法完全實現點對點的連接。為了解決上述GPU之間通訊不均衡問題,引入基於NVLink高級通信能力構建的NVSwitch芯片能夠在節點間擴展NVLink,創建無縫、高帶寬的多節點GPU集羣,實現所有GPU在一個具有全帶寬連接的集羣中協同工作。例如,在DGX V100架構中,每張V100 GPU卡上有6路NVLink,分別連接到6顆NVSwitch芯片上構成一個基板,兩塊基板之間再通過NVSwitch的另一側接口完全互聯在一起,形成16路全連接的GPU架構。英偉達在NVIDIA H100 Tensor Core GPU中引入第三代NVSwitch和第四代NVLink,NVSwitch單芯片上共有64個NVLink 4.0端口,能夠以900GB/s的速度互連每對GPU,聚合總帶寬達到7.2TB/s。
圖表9:NVLink的性能發展歷程

資料來源:英偉達官網,中金公司研究部
圖表10:NVLink和NVSwitch各世代規格參數
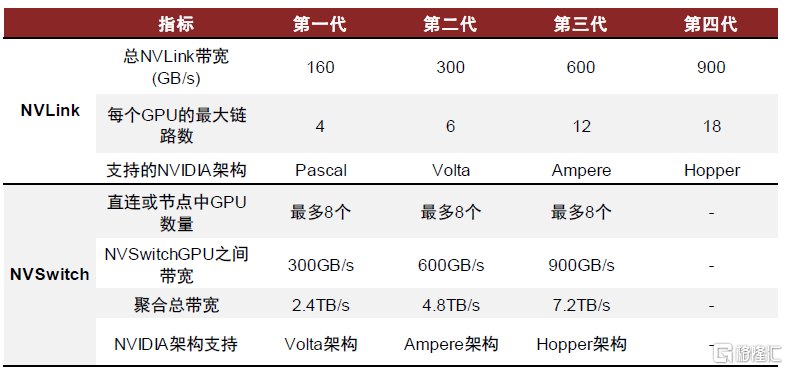
資料來源:英偉達官網,中金公司研究部
AI服務器中包含多種總線協議。以 NVIDIA HGX H100 8-GPU為例,該服務器內部包含NVLink、PCIe和QPI等主板總線。具體來看,該服務器擁有8個H100 Tensor Core GPU和4個第三代NVSwitch,每個H100 GPU共通過18個NVLink 4.0(5+4+4+5)連接到4個NVSwitch芯片。每個NVSwitch相當於一個完全無擁塞的交換機,與8張H100 GPU卡實現完全連接。GPU與CPU之間通過PCIe 5.0總線實現互聯,CPU之間則仍使用QPI總線進行通信。
圖表11:英偉達HGX H100 8-GPU結構框圖
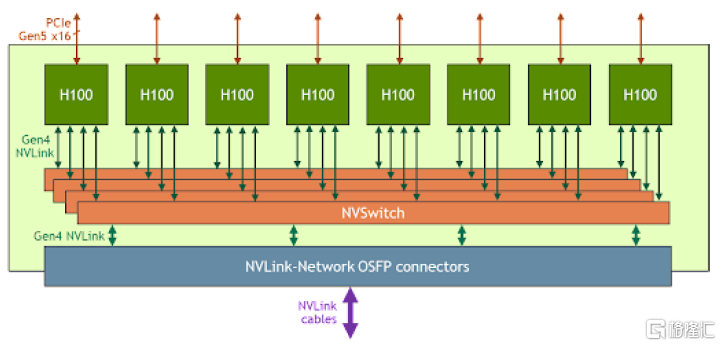
資料來源:英偉達官網,中金公司研究部
Infinity Fabric:片上模塊信息傳輸的高速通路
Infinity Fabric(IF)是基於片上總線架構的高速互聯技術,能夠實現高帶寬和低延遲的數據通信。IF由AMD於2017年首次提出,並在Zen架構中首次引入,用於連接各個CCX模塊、I/O、內存控制器等組件。根據AMD-CDNA2代白皮書,AMD-CDNA2中的IF接口連接可以顯著減少延遲,提供25Gbps的接口帶寬,最大雙向帶寬可達400Gbps。拆分來看,IF由Infinity Scalable Data Fabric (SDF) 和Infinity Scalable Control Fabric (SCF)兩個系統組成。SDF實現數據傳輸的高拓展性,通過數十個連接點路由數據往返,保障了多引擎環境下的可擴展性;SCF則負責傳輸命令和控制。以AMD基於Zen架構和Zeppelin SoC的處理器為例,SDF通過CCM、IOMS等模塊連接CCX核心和I/O組件。
圖表12:Infinity Fabric由SCF、SDF兩個部分組成
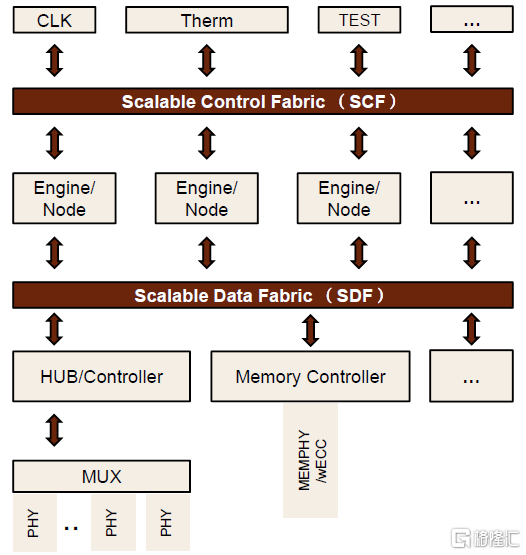
資料來源:Wikichip,中金公司研究部
Die間總線:裸片互聯的關鍵通道
Die間互聯總線是用於實現裸片之間通信的協議。Die間總線作為裸片互聯的關鍵通道,允許每顆裸片訪問其他裸片上的功能模塊,形成Die間資源共享、高效協作,從而實現高帶寬、低延遲和具備可靠性的通信。主流Die間總線包括HBM、IFOP、Interlaken、CCIX、NVLink-C2C等。
► HBM(High-Bandwidth Memory,高帶寬顯存):HBM是一種高端的內存技術標準,由JEDEC(電子工業聯合會)制定和管理,從2013年面世至今已經推出HBM、HBM2、HBM2E、HBM3四個版本,其中HBM2E為目前主流標準。HBM可以利用硅通孔(TSV)技術進行芯片堆疊,並與GPU位於同一物理封裝內,從而節省能耗及空間,以便在系統中安裝更多GPU。通過TSV堆棧的方式,HBM能達到更高的I/O數量,使得顯存位寬達到1,024位,幾乎是GDDR的32x,顯存帶寬顯著提升,此外還具有更低功耗、更小外形等優勢。中金研究認為,顯存帶寬顯著提升解決了過去AI計算“內存牆”的問題,HBM在中高端數據中心GPU中的滲透率有望逐步提高。
圖表13:HBM標準迭代
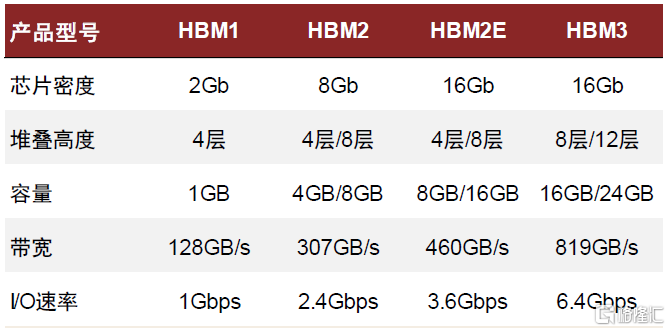
資料來源:SK Hynix官網,中金公司研究部
圖表14:HBM與其餘芯片互聯示意圖
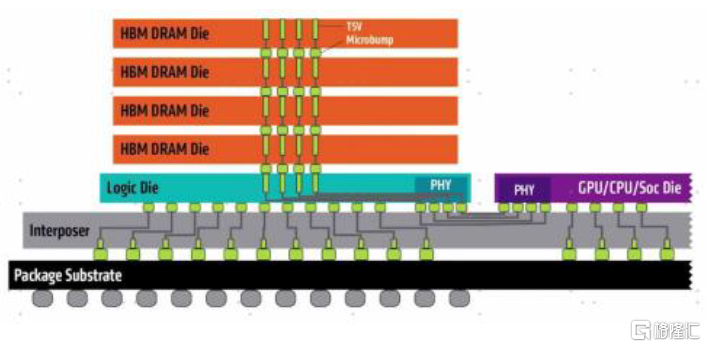
資料來源:SK Hynix官網,英偉達官網,中金公司研究部
► IFOP(Infinity Fabric On-Package):IFOP將Infinity Fabric架構擴展到芯片封裝內部,實現Die間的高速通信。中金研究在上一章節指出Infinity Fabric由傳輸數據的SDF和負責控制的SCF組成,AMD在SDF上設計了一種適用於封裝內部短距離的SerDes,藉助32位低擺幅單端數據傳輸和差分時鐘實現約2pJ/b的功耗效率。得益於片上和Die間IF總線在邏輯層實現互通,片上與Die間連接協議無需轉換,通信效率得到提升。
► NVLink-C2C:NVLink-C2C是對NVLink的拓展,藉助先進封裝技術支持多種裸芯互連,包括CPU、GPU、DPU、NIC及SoC等。相較於NVIDIA芯片上的PCIe Gen 5 PHY,NVLink-C2C在能效方面提升約25倍、面積效率提升約90倍。在Grace Hopper Superchip中,NVLink-C2C支持Grace CPU以900 GB/s的雙向帶寬與Hopper GPU進行通信,總帶寬約為x16 PCIe Gen5鏈路的7倍。此外,NVLink-C2C支持低延遲的內存一致性,能夠減少CPU、GPU之間的等待時間,提升系統效率。
圖表15:NVLink-C2C實現Grace CPU和Hopper GPU之間的高效通信
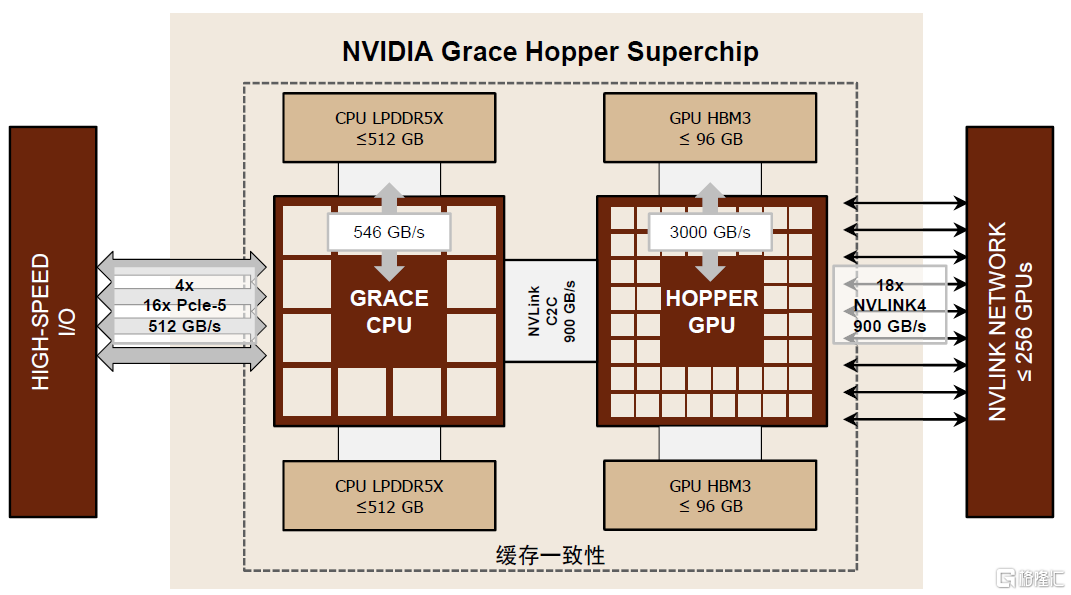
資料來源:英偉達官網,中金公司研究部
後摩爾時代眾核異構更具成本、良率優勢,推動Die間通信需求增長。隨着晶圓製程不斷迭代,每代研發成本增幅擴大,摩爾定律日趨放緩。據IBS統計,開發28nm/16nm/7nm/5nm製程芯片的研發投入分別為0.51/1.06/2.98/5.42億美元,每次迭代成本近乎翻倍。此外,單芯面積與製造良率存在反比關係,舉例來看,在5nm至3nm的迭代過程中,因3nm晶圓製造缺陷密度較高,隨着單顆芯片面積的增長,良率下降幅度較大。進入後摩爾時代,Intel和AMD均採用多Die拓展的技術路線,以確保在可接受的成本下進一步提升集成度和性能,眾核/眾核異構系統逐漸取代單一大芯片,Die與Die之間的通信需求隨之增加。展望未來,中金研究認為隨着AI任務的複雜度不斷提升,AI服務器的算力需求也將同步上升,眾核異構趨勢下Die間通信需求順勢上行,Die間總線作為Die間高效溝通的重要路徑也有望成長進階。
圖表16:不同製程及封裝技術下的芯片良率、成本、面積的關係

注:D為缺陷密度,c為負二項分佈中的集羣參數或Seed’s model中臨界值數量資料來源:Yinxiao Feng and Kaisheng Ma《Chiplet Actuary: A Quantitative Cost Model and Multi-Chiplet Architecture Exploration》(2022),中金公司研究部
Chiplet(芯粒)是眾核異構的熱門方案之一,能夠平衡大芯片的算力需求與成本。Chiplet的實質是硅片級別的IP複用,能夠將一些預先在工藝線上生產好的可實現特定功能的芯片裸片(Die)通過先進封裝技術互連,從而形成系統級芯片。Chiplet的優勢在於:1)成本:基於不同功能的IP(如存儲器、CPU等)靈活選擇不同的製程工藝進行生產,最優配置功能模塊並且不必受限於晶圓廠工藝,實現計算性能與成本的靈活平衡。2)算力:能夠突破單芯的面積限制,實現更高算力的芯片系統。3)通信帶寬:訪存帶寬通常是高性能CPU以及AI芯片的性能瓶頸,Chiplet採用高密度、高速封裝和互連設計,能夠有效提升計算和存儲、計算和計算之間的帶寬與信號傳輸質量,緩解“存儲牆”問題。4)存儲容量:Chiplet方案可以實現在單個封裝體內多次堆疊,在增加存儲容量的同時保持小型化。
圖表17:Chiplet可以實現集成異構化
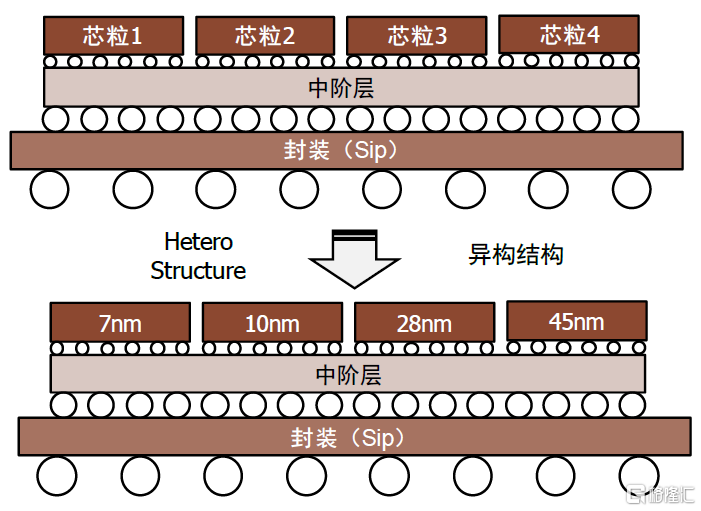
資料來源:eefocus與非網,中金公司研究部
Chiplet各裸片間的互連接口和協議對於Chiplet實現規模應用十分關鍵,是實現異構集成的必要條件之一。Chiplet裸片的互連接口和協議設計需要考慮與工藝製程及封裝技術的適配、系統集成及擴展等複雜要素,同時需要滿足不同應用領域對單位面積傳輸帶寬、每比特功耗等性能指標的差異化要求,通常上述指標要求相互矛盾,因此Chiplet互連接口與協議的設計難度較高。Chiplet互連接口與協議可以分為物理層、數據鏈路層、網絡層以及傳輸層。目前在研的互連接口及協議大多集中在物理層,與工藝、功耗以及性能緊密相關,眾多芯片廠商致力於推動自身的高速互聯協議,當前行業呈現多種協議標準交織的局面;鏈路層及以上接口更多沿用或擴展已有接口標準及協議。中金研究認為,裸片間互連標準的不統一制約了Chiplet的進一步發展,或面臨設計好的成品日後接口不匹配、不同芯粒互連時資源浪費等問題。
圖表18:當前行業呈現多種高速互聯協議交織局面
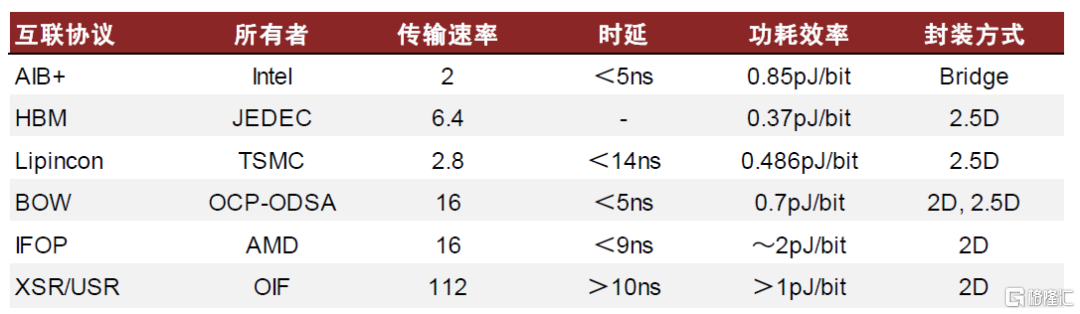
資料來源:半導體行業觀察,中金公司研究部
UCle有望打破不同接口協議之間的壁壘,助力Chiplet接口標準化。2022年3月,英特爾、AMD、Arm、高通、三星、台積電、日月光等芯片廠商,以及Google Cloud、Meta、微軟等雲廠商共同成立Chiplet聯盟,聯合制定Chiplet通用高速互聯標準,即UCIe(Universal Chiplet Interconnect Express)標準。UCIe在物理層、Die-to-Die適配器層、協議層三個維度對Die間連接進行規範,為多Die系統帶來高能效、高邊緣使用效率以及低延遲等多項性能優勢,推動實現Chiplet間高效封裝連接。中金研究認為,在統一的Chiplet互連協議下,來自不同廠商、但基於相同接口標準的Chiplet芯片有望通過先進封裝進一步得到整合,被更靈活地製造成模塊化的大型芯片,Chiplet生態體系有望逐步完善。
服務器內部高速通信訴求增加,多產業鏈迎來升級機遇
1# 接口芯片:接口升級推動底層SerDes高速化,高端接口IP增長強勁
SerDes是Serializer(串行器)和Deserializer(解串器)的簡稱,是一種主流的點對點高速串行通信技術。SerDes系統由參考時鐘、PLL模塊、上層協議、編解碼、發送端 (TX)、信道(Channel)、接收端(RX)等部分組成,通常集成在IP核中或以PHY芯片形式存在。SerDes的工作原理是:在發送端將多路低速並行信號轉換成高速串行信號,經過光纜或銅線傳輸後,在接收端將高速串行信號重新恢復為低速並行信號,實現串、並行數據間的轉換。該技術充分利用傳輸介質的信道容量,減少所需的傳輸信道和器件引腳數目,從而減少傳輸線之間的干擾,有效降低了通信成本和功耗。
SerDes為PCIe、以太網等協議提供物理層(Physical Layer,PHY)基礎。SerDes在電信、PC/服務器、數據中心、固態硬盤存儲等領域應用廣泛,高速以太網、DisplayPort、HDMI、PCIe、USB、SATA等高速串行鏈路數據通信協議的底層技術支撐均為SerDes。按照應用連接類型,SerDes技術主要用於芯片與芯片的互聯(如在PCIe PHY中)、以太網互連(如在Ethernet switch PHY中)、芯片與光模塊的互聯(如在ODSP PHY中)。PHY層一般配置PMA(物理介質子層)硬核和PCS(物理編碼子層)軟核。PMA屬於物理電氣子層,含有SerDes功能,負責接收併發送串行通道上的高速串行數據、時鐘數據恢復等;PCS針對不同的PCIe、USB、以太網等高速接口進行差異化編碼,主要功能是執行數據編碼和解碼、加擾和解擾、塊同步化等。
圖表19:接口PHY層架構
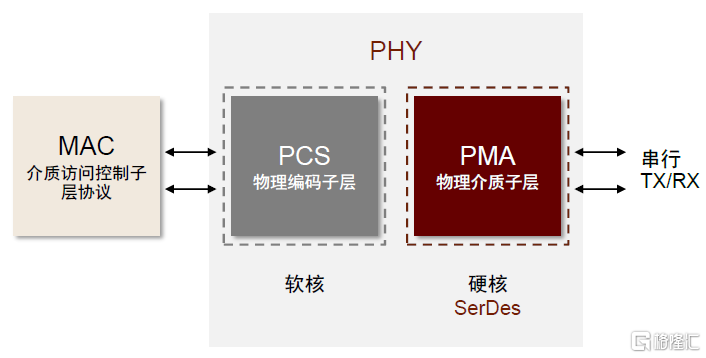
資料來源:《高速SerDes技術淺析和前景展望》(温戈,2021),中金公司研究部
SerDes單通道數據率持續提升,高速SerDes架構發生轉變。SerDes技術最早的單通道數據率一般在1.25-3.125 Gbit/s。當前國際上SerDes技術的最高水平為單通道發送器128 Gbit/s(功耗為1.3 pJ/b)、接收器100 Gbit/s(功耗為1.1 pJ/b),由IBM在ISSCC 2019會議上推出。從編碼方式看,對於單通道56 Gbit/s以下的應用,可採用傳統的NRZ編碼,56 Gbit/s以上的應用則需切換為PAM4編碼,通過犧牲一定信號幅度換取時序上的寬裕,SerDes架構因此發生變化,通常在收發器採用DSP(數字信號處理)和高速ADC(模數轉換器)技術來處理PAM4編碼。如新思科技的112G SerDes PHY即採用了基於ADC的靈活DSP架構。中金研究認為,服務器內部和服務器之間高速數據傳輸需求的增長對接口吞吐量提出更高要求,接口升級有望推動底層傳輸SerDes技術不斷向高速演進。
高速SerDes的設計複雜度提升,且對製造工藝提出更高要求。1)設計複雜度提升:SerDes是複雜的數模混合系統,混合信號設計難度較高,且高速SerDes所採用的PAM4信號對噪聲、反射、非線性和基線漂移更加敏感,收發器的整體設計更加複雜。2)更先進的半導體制程工藝:高速SerDes的收發器已轉向基於ADC和DSP的新架構,工藝進一步走向高端,要實現超過100Gbit的CDR(Clock and Data Recovery,時鐘數據恢復)功能,一般需要使用7nm及以下的先進製程。例如,Synopsys的112G SerDes通過5nm工藝實現。
SerDes設計實現IP化,成為接口IP市場增長的重要驅動力。SerDes早前以獨立的單通道芯片形式存在,目前多將SerDes收發器作為商業化IP模塊嵌入到需要高速I/O接口的大規模集成電路中應用。通過這種方式,芯片商可以從領先的IP設計提供商處購買通過驗證的設計許可,SerDes的複雜性轉移至專門的設計團隊承擔,研發成本可以跨多個芯片、項目甚至行業分擔,有助於降低整體設計成本以及節省研發時間。目前SerDes IP已實現廣泛應用,是全球接口IP市場增長的重要驅動力之一。根據IPnest數據,2022年接口IP在整個IP市場中的市佔率達到25%,僅次於處理器IP(49%),較2017年的18%提升7ppt;IPnest預計2023年全球高速SerDes IP市場容量有望達到5.66億美元,2020-2023年CAGR約12%。
接口IP持續向高速演進,高端接口IP市場張力十足。中金研究認為,AIGC的發展對數據傳輸的帶寬和時延均提出更高要求,將進一步推動PCIe、以太網、SerDes、存儲等接口協議升級,接口IP的產品迭代有望加速。根據IPnest預測,2022-2026年PCIe、DDR、以太網和D2D四類接口IP市場規模的年均複合增速約為27%,其中高端品類2022-2026年CAGR高達75%,貢獻未來接口IP市場主要增量,IPnest預計到2026年四類高端接口IP市場規模合計有望達到21.15億美元。
圖表20:2021-2026年高端接口IP市場規模預測
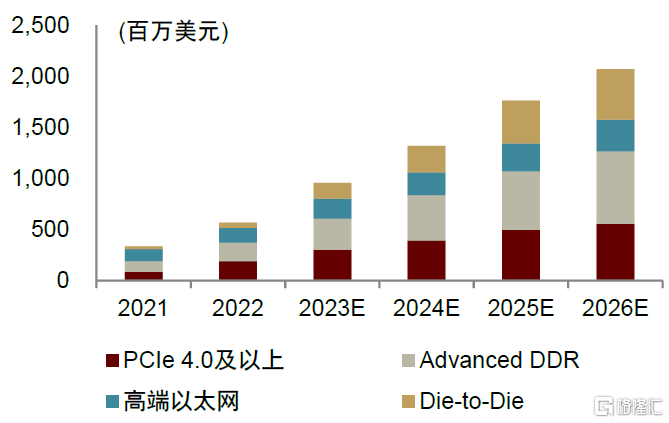
注:高端以太網指基於56G、112G、224G SerDes的PHY資料來源:IPnest,中金公司研究部
SerDes技術供應商集中在北美,國產廠商加速佈局。目前市場上主要存在兩類SerDes廠商:1)第三方SerDes供應商:授權SerDes IP給芯片商使用並收取專利授權費。全球領先的第三方SerDes廠商Synopsys、Cadence、Alphawave、Rambus等均為美國公司,根據EETOP數據,Synopsys在2021年高性能SerDes市場佔據55.6%的份額。海外廠商憑藉先發優勢以及對接口標準進行改進的較高話語權,佔據市場主導位置;當前國內市場SerDes IP自給率仍較低,本土廠商正在突破112 Gbps的SerDes技術。2)自研廠商:英特爾、Marvell等廠商根據自身需求設計SerDes,定製化屬性較強。
2# 先進封裝:芯片封裝進階,ABF先進載板景氣度提升
封裝技術的精進是實現Chiplet等眾核異構方案的重要支撐。傳統封裝方式主要基於導線將晶片的接合焊盤與基板的引腳相連,實現電氣聯通,最後覆以外殼形成保護,主要方式有DIP、SOP、QFP等。在芯片製程逐漸逼近硅片極限、摩爾定律推進速度放緩的行業趨勢下,先進封裝的出現優化了裸片間的連接方式,可以有效縮短異構集成架構下Die間信號距離,使得性能和功耗都得以優化,在提高芯片集成度、電氣連接以及性能優化的過程中扮演重要角色。中金研究認為,AIGC發展浪潮將加速推進眾核異構方案主流化進程,先進封裝技術有望不斷革新。
先進封裝相比傳統封裝最直觀變化在於連接方式,通過對點或層的合理佈局替代引線。點連接包括Bumping(凸塊)、TSV(硅通孔);層連接包括RDL(重佈線層)和Interposer(中介層)。
► Bumping(凸塊):倒裝技術(Flip-Chip)是整個封裝過程的核心環節,Bumping工藝又是倒裝技術的關鍵一環。對比以往背對基板和貼後鍵合的連接方式,FC封裝技術通過焊球連接晶片和基板,實現了更高的引腳密度和更可靠的電氣連接;其中Bumping能夠實現FC工藝中生長焊球、對接基板引腳的功能。
► TSV(Through Silicon Via,硅通孔):TSV是一種三維芯片堆疊技術,通過硅通孔實現多層芯片垂直互通。按集成類型分,TSV可分為2.5D和3D兩種類型,2.5D通孔位於中介層中,3D通孔貫穿芯片本身,直接連接上下層芯片。
圖表21:2.5D、3DTSV結構示意圖
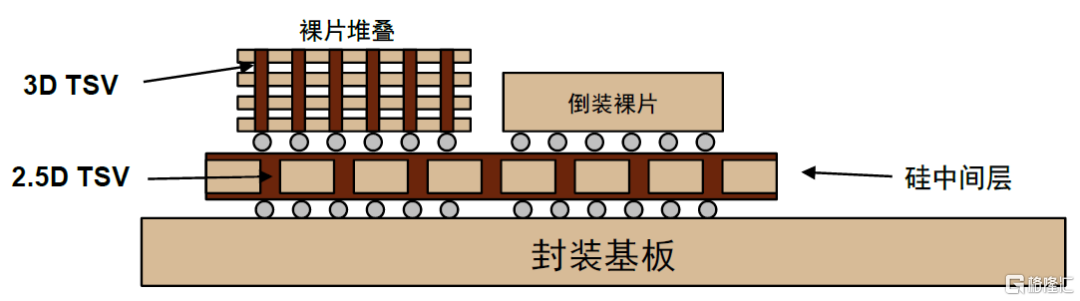
資料來源:李揚《SiP系統級封裝設計與仿真》(2012),中金公司研究部
► RDL(Re-distributed layer,重佈線層):2.5D維度下RDL實現Bump之間的連接;3D維度下則用於I/O之間的校準及電氣互通。根據重布凸點的位置,RDL可分為扇入型(Fan-In)和扇出型(Fan-Out)。扇入型封裝是將線路集中在芯片內部,主要用於低I/O節點數量和較小裸片工藝中;扇出型封裝技術採用在芯片尺寸以外的區域做I/O接點佈線設計以提高I/O接點的數量,主要適用於尺寸較大的芯片類型,如服務器、主機芯片。
► Interposer(中介層):Interposer 是一種中間層,在分佈式系統中通過連接凸點實現上下層之間的互通。中介層通常由硅或有機材料製成,具備較高的細間距I/O密度和TSV形成能力,在2.5D和3D IC芯片封裝中扮演着關鍵角色。
將上述互連的技術路徑排列組合,形成了Fan-out、WLCSP(晶圓級封裝)、Flip-chip(又可細分為FCBGA、FCCSP兩種倒裝)、2.5D/3D封裝、SiP(系統級封裝)等先進封裝形式,“封裝”概念延伸至晶圓、系統層面。中金研究看到,隨着芯片在算速與算力上的需求持續提升,先進封裝不斷向功能多樣化、連接多樣化、堆疊多樣化發展,封裝形式對應的引腳間距越來越小、連接密度越來越高。頭部晶圓廠/IDM、封測代工廠、存儲器製造商逐步開發出多種連接密度更高的先進封裝形式,如超高密度扇出型(UHD Fan-out)、嵌入式硅橋、混合鍵合等。
圖表22:連接密度更高的先進封裝方式及代表廠家
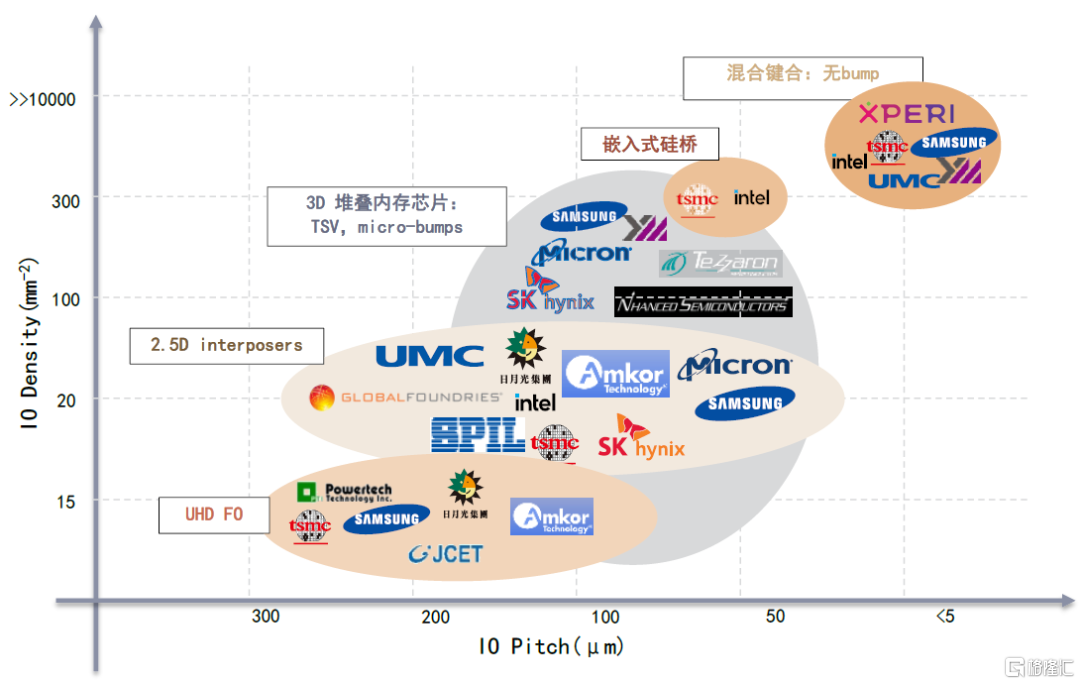
資料來源:Yole,中金公司研究部
全球先進封裝需求呈增長態勢,在整體封裝市場的滲透率持續提升。根據Yole預測,全球先進封裝市場規模有望從2021年的321億美元擴容至2027年的572億美元,2021-2027年複合增長率為10%,其中Fan-out和2.5D/3D封裝的市場增速領先。滲透率方面,Yole預計先進封裝在封裝總市場的佔比將從2021年的45%增長到2025年的49.4%,先進封裝需求持續提升。看到國內市場,國內先進封裝佔比相對較低,根據Frost&Sullivan數據,2021年國內先進封裝銷售規模約399億元,在整體封裝市場滲透率約15%,Frost&Sullivan預計2025年國內先進封裝市場規模有望增長至1136.6億元,2021-2025年CAGR為29.9%,遠高於傳統封裝增速(1.7%)。中金研究認為未來先進封裝將成為國內突破晶圓製造工藝掣肘的重要發展趨勢。
圖表23:全球先進封裝市場及細分市場收入
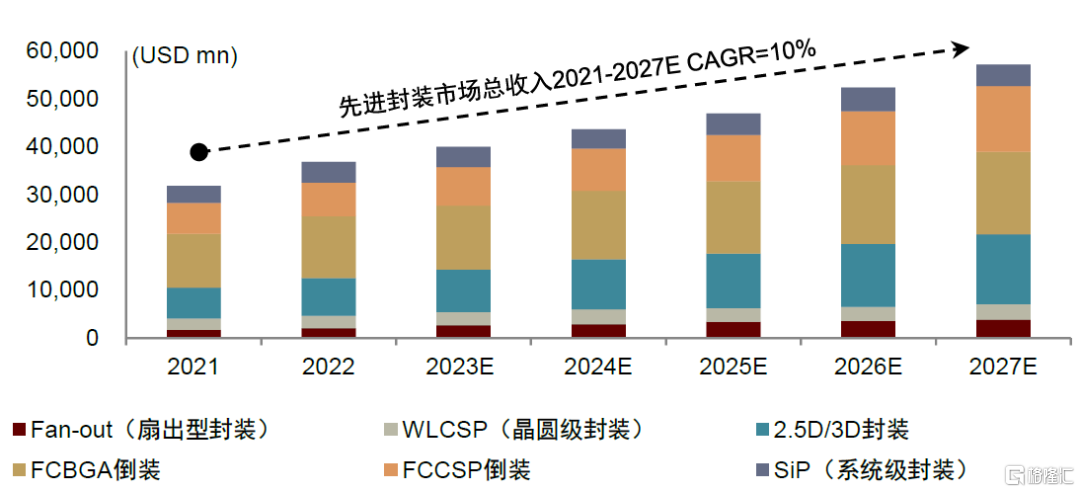
資料來源:Yole,中金公司研究部
圖表24:全球先進封裝和傳統封裝市場佔比
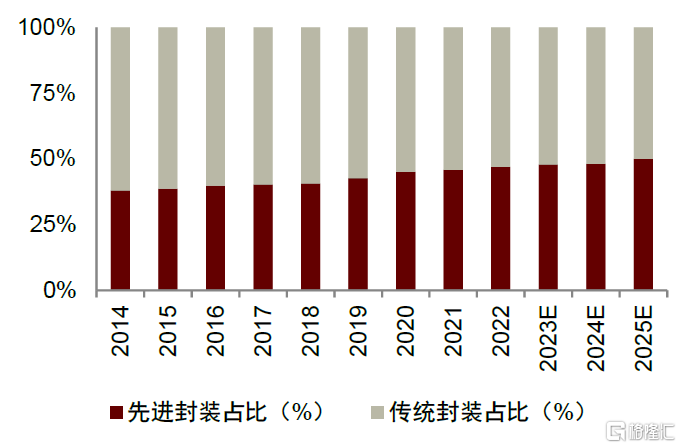
資料來源:Yole,中金公司研究部
高算力芯片需求攀升,有望帶動ABF載板景氣上行。封裝基板(即IC載板)向上承載芯片,為芯片提供保護、固定支撐及散熱作用;向下則對接PCB模板,在PCB與芯片之間提供電子連接,是先進封裝的必備材料。根據中國半導體協會封裝分會數據,IC載板在傳統引線鍵合類封裝中的成本佔比為40-50%;在高端倒裝芯片中的成本佔比高達70-80%。按照基板材料分類,主流IC載板可分為BT、ABF載板兩類,其中ABF載板以ABF膜(日本味之素堆積膜)為基材,主要用於CPU、GPU、FPGA、ASIC等高運算性能芯片。根據IC載板統計,2021年服務器是ABF載板最大的應用市場,約佔55%。中金研究認為,AI浪潮推動AI服務器(包含搭載GPU、FPGA、ASIC等服務器)出貨量預期快速增長,AI服務器相比於傳統服務器芯片用量增加牽引高算力芯片需求激增,有望帶動ABF載板需求向上。
圖表25:2021年ABF載板應用端分佈情況

資料來源:IC載板,中金公司研究部
Chiplet異構集成下ABF載板面積更大,良率降低使得載板消耗量提升。Chiplet將不同製程、材料的芯片整合至一處以實現異構集成,因此需要面積更大的ABF載板放置。以AMD高端CPU-EPYC為例,EPYC採用4個獨立Die一起封裝的方式,實現了單CPU 64核128線程的設計目標。EPYC最終的封裝面積為852平方毫米,是單Die封裝面積的4倍;且ABF載板耗用面積增大引起生產良率降低,造成一定產能損失,因此ABF載板消耗量將進一步增加。根據Prismark預測,2021年全球ABF載板市場規模(也稱作FCBGA封裝基板)為70億美元,2026年有望達到121億美元,2021-2026年複合增長率為11.6%,高於整體封裝基板市場8.3%的CAGR。
圖表26:AMD CPU-EPYC(64核)示意圖
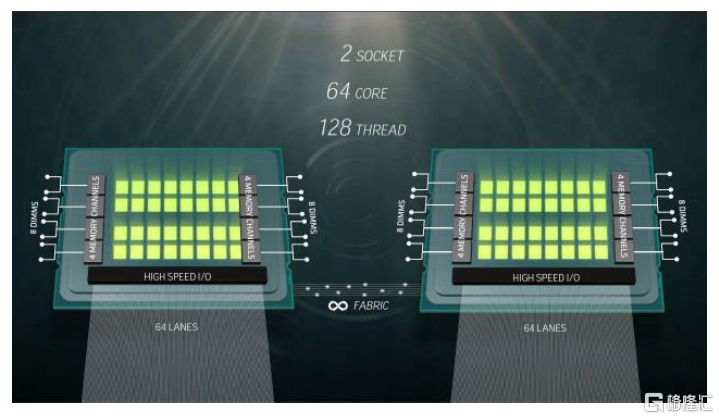
資料來源:TechPowerUp,中金公司研究部
圖表27:全球ABF載板市場規模及同比增速
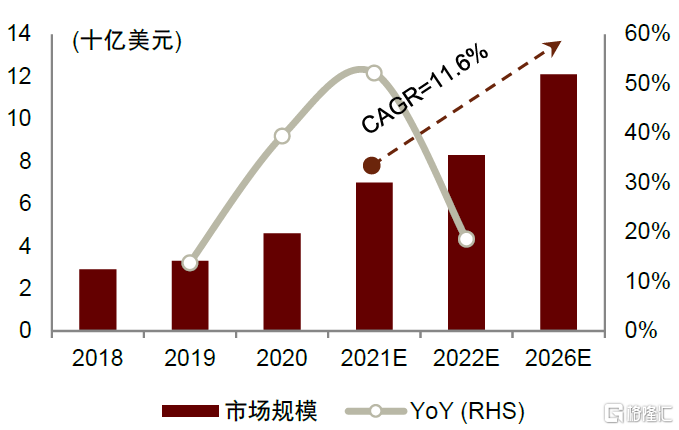
資料來源:Prismark,中金公司研究部
全球封裝基板競爭格局相對分散,多為中國台灣及日韓廠商。目前中國大陸廠商封裝基板擴產項目多,但具備量產能力廠商少,ABF載板國產化率幾乎為零,主要參與廠商為興森科技、深南電路、珠海越亞等企業,其中興森科技規劃珠海及廣州兩個FCBGA項目,合計共投資72億元,深南電路深圳、無錫工廠總共具備90萬平方米/年的設計產能,珠海越亞作為現有珠海、南通兩個封裝基板工廠;此外,博敏電子、中京電子、景旺電子、東山精密、勝宏科技等廠商也先後宣佈了各自的封裝基板擴產規劃,中金研究認為隨着國內高算力處理器芯片的迅速發展,IC載板國產化率有望迅速提升。
3# PCB:AI時代海量算力推動PCB全產業鏈升級
服務器平台迭代、AI服務器需求高升,共促PCB主板與板材升級
PCB是承載服務器內各種走線的關鍵部件,其功能是連接各電子元件並實現通信。根據Prismark數據,2021年服務器/數據存儲PCB市場規模為78.12億美元,佔PCB總規模的9.7%;Prismark預計2026年服務器/數據存儲市場規模有望擴容至125.74億美元,2021-2026年CAGR為10%,高於行業平均水平4.8%,服務器/數據存儲是PCB產值增速最快的下游應用領域。一般來説,服務器中的主板、電源背板、硬盤背板、網卡、內存、CPU板組、GPU板組等核心部分均需要用到PCB,服務器對PCB產品需求以6層以上為主,其中主板層數在16層以上,背板層數在20層以上,網卡PCB層數在10層以上。根據Prismark,2021年服務器/存儲設備中6層及以上PCB市場佔比為56.82%,中金研究測算得到這部分市場規模約為44.39(78.12*56.82%)億美元。
圖表28:全球服務器/數據存儲PCB產值及增長率
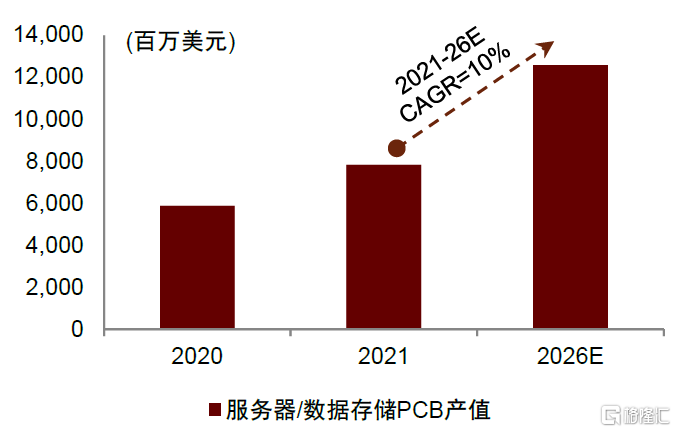
資料來源:Prismark,中金公司研究部
圖表29:2021年服務器/存儲PCB需求分佈
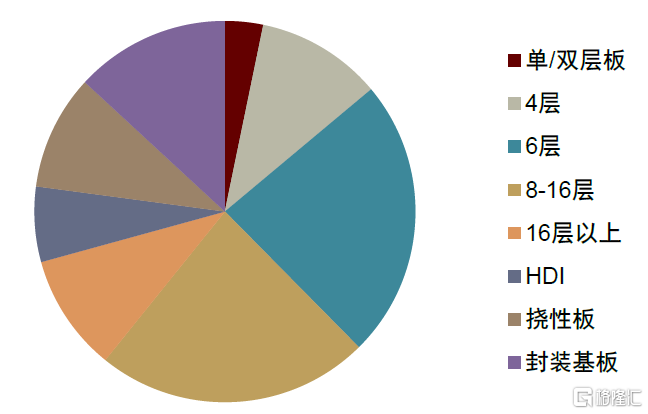
資料來源:Prismark,中金公司研究部
服務器平台的升級推動PCB層數增加、上游基材性能提升。以Intel為例,服務器平台從支持PCIe 3.0的Purely演進至支持PCIe 5.0的Eagle,PCIe總線升級同步帶來更加嚴重的信號鏈路插損問題。增加PCB板層數、使用介質損耗更低的覆銅板(Copper Clad Laminate,簡稱CCL)是解決PCIe信號鏈路插損問題的關鍵舉措。1)從層數看,PCB層數越多,設計的靈活性越大,可以起到電路阻抗的作用,從而實現芯片組間高速電路信號的高速傳輸。2)從材料看,CCL是生產PCB的核心原材料,CCL的Df值(介電損耗因子)越小,CCL的介質損耗越低,能夠有效減少PCB中的信號衰減。
具體來看,根據Prismark數據,PCIe 3.0總線標準下,信號傳輸速率為8Gbps,服務器主板PCB為8~12層,相對應的CCL材料Df值在0.014~0.02之間,屬於中損耗等級;PCIe 4.0總線16Gbps的傳輸速率,PCB層數需要提高到12~16層,CCL材料Df值在0.008~0.014之間,屬於低損耗等級;當總線標準提升至PCIe 5.0,數據傳輸速率達到36Gbps,PCB層數需要達到16層以上,CCL材料Df值降至0.004~0.008區間,屬於超低損耗材等級。中金研究認為,PCIe總線向高速演進將帶動PCB規格持續升級,由M6(Df區間在0.004-0.008)及以上覆銅板材料製成的超過16層的PCB有望成為服務器標配。根據Prismark,2021年8-16層板的平均價格為456美元/平米,18層以上板的價格為1538美元/平米,高層板的價值量大幅增長。
圖表30:PCIe總線升級帶來主板PCB層數與上游基材CCL的升級

注:M2/4/6代表CCL龍頭企業松下的產品型號,其中M代表Megtron 資料來源:Prismark,Panasonic公司官網,中金公司研究部
AI服務器需要更高層數、更高密度的PCB作為算力載體,有望打開PCB新一輪成長週期。AI服務器PCB相比普通服務器最大的價值增量來自GPU板組。以英偉達DGX H100服務器為例,單台H100配置8顆GPU形成GPU模組,多卡互聯場景下GPU板組的走線更多、更密集;同時,高端GPU對針腳數、顯存顆粒、供電模塊的需求增加,PCB層數需進一步增加。此外,高算力AI服務器對CCL的散熱性及電特性提出更高要求。中金研究觀察到,通用服務器PCB的層數一般在16-20層,AI訓練服務器的PCB則普遍在20-48層,且關鍵材料CCL升級到M7/M8。中金研究估測單台AI服務器的PCB價值量約為單台通用服務器的3-4倍。中金研究認為,AI大模型等需要海量數據的應用發展將推動算力持續上行,大容量、高速、高性能的AI服務器滲透率有望持續提升,帶來PCB高層板增量空間。
圖表31:AI服務器和通用服務器PCB對比

資料來源:人工智能與創新公眾號,中金公司研究部
高速PCB相比於普通PCB的難度主要體現在材料和工藝:一方面,特定厚度的高速基材CCL,提高了PCB生產商對材料的應用要求;另一方面,PCB層數越多,對對位精度、阻抗控制等製造工藝提出更高的要求,生產設備的配置要求也更高,工藝流程更加複雜,生產時間也更長。
從全球PCB供應格局看,全球PCB廠商眾多(根據NTI估計,超過2000家),但掌握多層高速工藝技術的有限,頭部企業集中在中國台灣、日韓、美國。大陸PCB廠商在全球的產值佔比已過半,但大部分廠商供給以8層板以下為主,高端產品滲透空間仍較大。目前,具備多層高速PCB技術和產品的國內廠商主要包括滬電股份、深南電路、勝宏科技、生益電子等。
圖表32:2020年全球PCB企業競爭格局
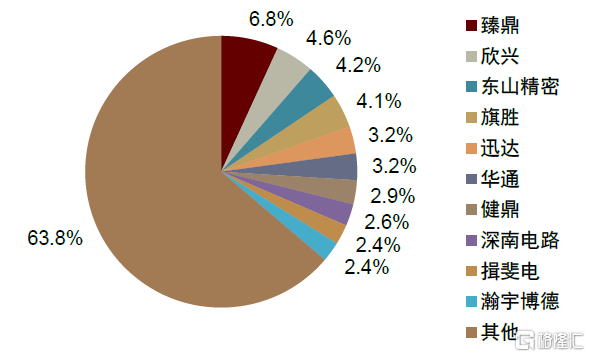
資料來源:億渡數據,中金公司研究部
高速CCL市場較集中,國內廠商進軍高速市場。全球前六大CCL廠商為建滔化工、生益科技、南亞塑料、松下電工、台光電子和聯茂電子,Prismark數據顯示2020年合計市場份額超過50%。高速CCL市場集中度相對更高,2021年前四家佔據近65%份額,主要參與者包括松下、依索拉(Isola)、聯茂(ITEQ)、台耀(TUC)等(根據Prismark數據)。國內廠商也已實現技術突破。
圖表33:2020年全球覆銅板企業競爭格局
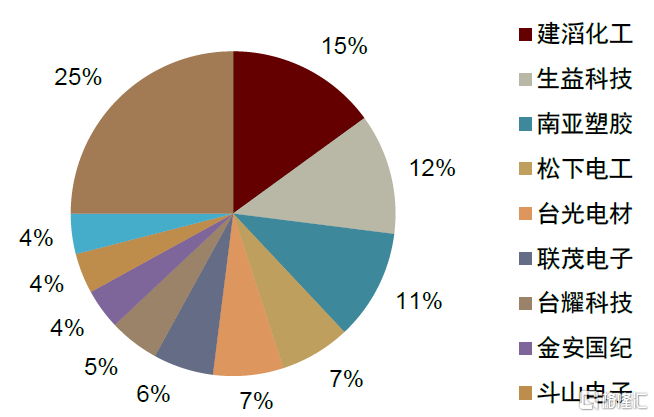
資料來源:Prismark,中金公司研究部
電子級PPO持續滲透高速CCL,彰顯高增長潛能
樹脂是CCL的核心原材料(樹脂、銅箔、增強材料)之一,用於提升CCL電熱性能。CCL是將增強材料(玻璃纖維布等)浸以樹脂膠液形成粘結板,隨後將其一面或兩面覆以電解銅箔,經熱壓而成的板狀材料。其中,樹脂主要承擔板材的結構支撐、導通互聯及絕緣的功能,對CCL的介電性能、熱加工穩定性、阻燃性、尺寸穩定性等性能起到決定性作用。根據南亞新材招股書,2017-2019年樹脂佔覆銅板原材料成本比重持續提升,2019年達到25.5%。一般而言,降低Df(介電損耗)主要通過樹脂、基板及基板樹脂含量來實現。各種樹脂按照Df由大到小排序,依次包括環氧樹脂(Epoxy)、聚酰亞胺樹脂(PI)、雙馬來酰亞胺樹脂(BMI)、氰酸酯樹脂(CE)、聚苯醚樹脂(PPO)、聚四氟乙烯樹脂(PTPE)等。
圖表34:2017-2019年覆銅板原材料成本構成
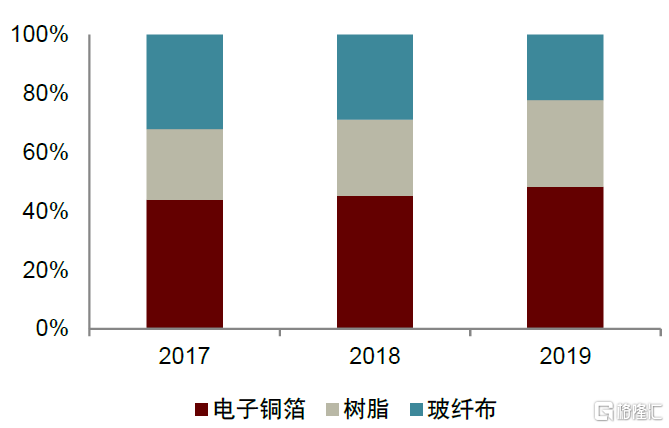
資料來源: 南亞新材招股書,中金公司研究部
PPO(聚苯醚樹脂)是一種熱塑性工程塑料,改性後電化學性能優異。PPO分子結構中無強極性基團,因此介電常數和介電損耗較低,且具有良好的耐水性、阻燃性、耐熱性;同時,PPO可沿用傳統環氧樹脂基材的成型工藝及設備,材料升級成本較低。但在IC領域實際使用過程中,基材需承受焊接高温以及芳香烴、鹵代烴等溶劑沖洗銅箔表面,純PPO材料由於分子量高存在熔融加工困難、交聯固化程度較低等缺陷,需通過物理或化學方式對其改性。改性PPO樹脂及組合物(簡稱MPPO)具有質輕、優異的耐高低温性、電絕緣性、耐蒸汽性、尺寸穩定性和抗蠕變性等特點,是覆銅板理想的基體樹脂材料。
高速覆銅板應用提高MPPO使用率,MPPO市場需求可觀。普通CCL主要使用FR-4等級的環氧樹脂(Epoxy)作為基體樹脂,傳輸損耗較大。低損耗等級以上(即基材介電損耗係數Df≤0.008)的高頻高速CCL所使用的樹脂體系主要有兩條路線:1)以PTFE為代表的熱塑性樹脂體系;2)以MPPO為代表的熱固性樹脂體系。由於AI服務器使用的高速覆銅板對耐熱性及尺寸穩定性有較嚴格的要求,PTFE的熱膨脹係數及加工穩定性相對較差,極低損耗和超低損耗等級的高速覆銅板多采用MPPO作為主要樹脂體系,如松下的M6、M7N,聯茂的IT968、IT988GSE。中金研究認為,MPPO有望受益於AI算力提升帶來的高端服務器需求量增長以及覆銅板高頻高速化發展趨勢,滲透率有望持續提升。根據新思界產業研究中心預測,2022年全球MPPO需求量超過75萬噸,未來3-5年全球MPPO需求量有望以超過12%的年均複合增速快速增長。
圖表35:PPO與其他電子樹脂性能比較
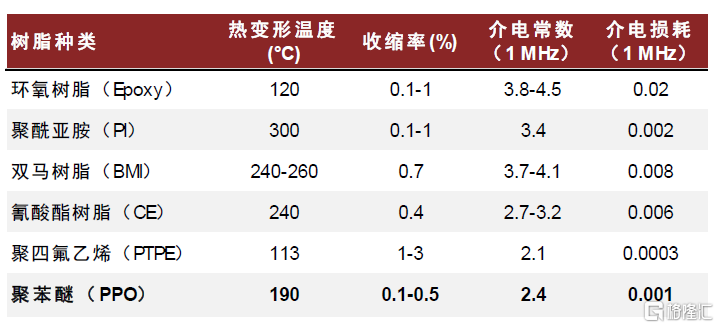
資料來源:《高速高頻覆銅板用改性聚苯醚的合成與性能表徵》(2012,閆沁宇),中金公司研究部
圖表36:各損耗等級下基材使用情況
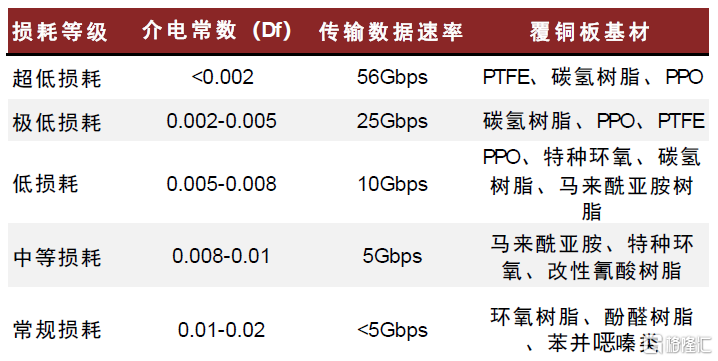
資料來源:深南電路招股書,中金公司研究部
MPPO技術壁壘高,海外廠商佔據主導地位。PPO在1957年由美國GE公司的Hay通過氧化偶聯法制得2,6位取代基聚合物,於1965年實現工業化生產。隨着超高頻通信的發展,聚苯醚樹脂的改性成為主要研發方向。1967年GE公司成功研發出改性工程塑料PPO,此後一直壟斷該項技術。到1979年,日本旭化成開發了苯乙烯改性的聚苯醚,打破了GE公司的壟斷。20世紀80年代,SABIC(收購了GE工程塑料業務)在以 PPO為原材料的樹脂片“Noryl”上覆上銅箔後壓制成覆銅板,PPO開始成為覆銅板上游基材。改性PPO的技術難點在於:1)通過再分配反應降低分子量,以增強層壓材料的粘結性;2)在PPO分子結構中引入活性官能團,以提升可交聯性。海外廠商技術壁壘及產能先發優勢突出,SABIC、旭化成等少數化工跨國企業佔據主要市場地位。根據立木信息諮詢數據,2021年SABIC PPO產能佔全球市場的46.6%。
產品認證週期長,構成一定客户壁壘。MPPO的產品認證時間較長,一般需經過覆銅板、PCB以及服務器等設備終端三個環節的層層認證,整體認證週期超過一年半。此外,採用MPPO材料的PCB板層數多、價格高,下游客户在確定上游供應商後更換意願較低,構成較強的客户粘性。中金研究認為,率先通過客户認證並實現批量供應的國產廠商先發優勢顯著,有望優先受益於國產替代趨勢以及下游高速CCL需求釋放。
圖表37:PPO產業鏈簡圖

資料來源:聖泉集團招股書,中金公司研究部
高頻高速覆銅板樹脂供應商本土化提速。近年來隨着我國5G、AI 服務器等新興需求的出現,低Df/Dk的特種電子樹脂本土化提速。目前我國已經掌握MPPO生產技術,且實現了MPPO的規模化生產。
風險提示
AI商業落地進展不及預期的風險。隨着全社會數字化轉型及智能化滲透率的提升,人工智能持續賦能各行各業。而人工智能依賴於海量數據進行模型訓練及推理應用,推動全社會算力需求提升,拉動服務器、網絡設備等上游硬件基礎設施投資水平向上。如果人工智能發展及應用落地不及預期,可能會使上游硬件設備受到需求側的壓制,發展不及預期。
雲廠商算力相關資本開支不及預期。AI服務器的採購需求受雲廠商的資本開支影響,若下游廠商對算力基礎設施的投資力度不及預期,或影響AI服務器出貨量。
注:本文摘自中金研究於2023年7月19日已經發布的《AI浪潮之巔系列:大模型推動大算力,通信傳輸再升級》,分析師:鄭欣怡 S0080122070103;陳昊 S0080520120009;李詩雯 S0080521070008 ;彭虎 S0080521020001 ;唐宗其 S0080521050014;江磊 S0080523070007


More Content

Physical Store(set to open in Q2 2025)
Address:
Shop LMC 307, 3/F, Lok Ma Chau MTR Station, Lok Ma Chau
Opening Hour:
9am - 9pm (Mon - Sat)
10am - 6pm (Sun and Public Holiday)

(set to open in Q2 2025)





