





本文來自格隆匯專欄:中金研究,作者: 趙麗萍 於鍾海 等
2012年深度學習元年以來,AI進入學術和商業界發展新階段,2017年大模型路線以“通用智能”思路降低算法邊際成本,逐漸成為學界與產業共識。2022年下半年,AIGC及ChatGPT關注度大幅提升背後,我們認為其本質是弱人工智能到強人工智能的階躍,海外及國內商業落地處在初期,但我們認為新的產業趨勢值得關注。OpenAI的技術進展及投資方向、海外AI獨角獸業務進展、國內龍頭AI公司的跨模態佈局是重要風向標。
摘要
技術層面,ChatGPT和AIGC的持續升温依託於大模型的技術紅利。從2012年的深度學習元年以來,各界產生了海量的數字化需求,大模型技術路線是降低邊際成本的核心,2017年大模型(Transformer)路線逐漸成為學術界與國內外巨頭的發展共識。ChatGPT由GPT-3.5大模型加入基於人類反饋的強化學習訓練而成,帶來弱人工智能向通用智能的階躍。
商業層面,以OpenAI投資方向為風向標,落地仍在探索期,跨模態打開場景空間。對於AIGC領域,AI作畫等跨模態應用是未來的發展趨勢,全球範圍內AIGC獨角獸已初步具備B端為主的變現能力,海外落地節奏顯著快於國內。ChatGPT推出後,海外已有早期合作案例,例如為BuzzFeed提供個性化測試、為Amazon解決客户和工程師技術難題等。此外,以OpenAI前沿投資方向為錨,我們認為文本到圖片/視頻的跨模態生成、垂直領域AI寫作、智能筆記、AI語言學習平台或為潛在落地方向。
展望未來,行業格局有望走向底層集中、垂類多點開花,MaaS是商業模式演進的潛在方向。我們認為,ChatGPT為代表的模式背後,成本、算力、場景、數據等多維度需求鑄就高門檻,大模型路線下,未來行業格局趨向集中,泛化通用大模型能力的廠商有望呈現多強格局;關鍵垂類仍可能有場景、數據優勢,精細調優後的垂類模型仍有差異化競爭潛力。展望未來的商業模式,我們認為以海外Hugging Face為代表的Model-as-a-Service是潛在方向,具備大模型基礎的龍頭有望成為AI開源基礎設施提供商、社區生態建設者。
風險
技術進展不及預期,行業競爭加劇,商業化落地節奏不及預期。
技術篇:ChatGPT和AIGC持續升温背後
本質上是大模型的技術紅利
ChatGPT和AIGC持續升温的本質是背後的AI大模型進入新範式。ChatGPT是基於GPT-3.5的IntructGPT,基於人類反饋的強化學習(RLHF)訓練的語言類大模型。本文梳理了ChatGPT背後的技術演進與應用落地節奏,並對未來AI行業的格局加以展望。
從2012年的深度學習元年開始,上一輪紅利已經持續10年
2012年是深度學習元年,以Hinton團隊在ImageNet大賽中引入深度學習算法為重要節點。Hinton帶領的團隊在ImageNet挑戰賽中,通過構建深度神經網絡AlexNet成功將圖片識別錯誤率降低了10.8pcts,以大幅超越第二名的成績奪冠,證明了深度學習的發展潛力,開始被業界和資本關注。
圖表1:AI從引起業界廣泛關注到目前不足10年

資料來源:量子位,Omdia,中金公司研究部
早年業界一度認為小模型、小算力是方向。此前的共識是通過精妙的算法和更高的模型精度,減少對算力的需求,但行業落地實踐證明其短板明顯:
► 精妙模型路線導致重複研發,無法讓AI賦能千行百業。在AI公司進入大量新場景時,對每個場景都重複研發大大增加了邊際成本。
► 精妙模型路線無法解決長尾場景,完善AI商業化價值閉環。以份額占人工智能行業近一半份額的智慧城市為例,其中的長尾場景如防火防災、電梯事故、垃圾亂扔由於研發難度高,大部分AI公司難以低成本解決,嚴重影響到客户對整套解決方案買單的意願。
圖表2:目前AI模型的神經元總量與人類差距較大

資料來源:阿里雲《中國企業2020:人工智能應用實踐與趨勢》(2019年),中金公司研究部
技術演進視角,大模型是實現通用AI的重要方向。雖然距離完全達到人類智能水平的AI,還有很長一段路要走。但近幾年在長尾場景等問題導致了對更通用的人工智能的剛需,在國內外巨頭紛紛投入大量資源攻克通用人工智能難題的推動下,通用的語言模型、視覺模型甚至多模態模型也開始逐漸取得突破。2020年OpenAI推出1750億參數的GPT-3大模型是行業重要里程碑,為後續大模型迭代、加入人為干預,以及AIGC、ChatGPT的推出打下技術基礎。
圖表3:大規模預訓練模型對於算力需求呈指數增長

資料來源:英偉達官網,中金公司研究部
大模型將AI從感知提升到理解的維度
過去的深度學習在CV(計算機視覺)領域大放光彩,但本質上還是更多的解決感知問題。CNN(卷積神經網絡)已經能夠較好的解決常規的人臉識別、物體識別問題,但在NLP(自然語言處理)領域,對於物體、概念的抽象理解、語義的識別和理解,乃至推理和邏輯仍然是巨大的挑戰。Transformer算法(大模型路線)在NLP領域成果卓越,催化NLP的能力從簡單的感知,向深層次的理解乃至推理不斷髮展。
圖表4:模型的參數大小在不斷提升,性能也在與時俱進

資料來源:Jordi Torres.AI,中金公司研究部
圖表5:AI的能力也在從感知向理解、推理、生成攀爬

資料來源:中金公司研究部
如何簡單的理解大模型(大規模預訓練模型)
基於具備一定通用性的大模型,通過少量的增量訓練蒸餾出小模型,是解決長尾問題的關鍵技術架構。從模型訓練到部署,需要通過剪枝、量化、蒸餾等模型壓縮技術實現更高的經濟性及快速推理。以蒸餾為例,可以將結構複雜、參數規模龐大的大模型,壓縮成結構簡單、易於部署的小模型,相比於直接生產的小模型,大模型蒸餾出的小模型具有更強的泛化能力,邊際成本大幅降低。
大模型+小模型的方式能有效降低AI落地邊際成本。由於避免了“手工作坊”式的AI生產方式,不需要每做一個項目就派出大量專家花數月駐場收集數據、調試模型、訓練模型,並且對長尾場景的解決為客户創造了更多價值。用足夠多的數據和足夠大的算法去訓練一個足夠大的通用模型,再通過量化、剪枝、知識蒸餾等模型壓縮方法把大模型變小,高效的進行模型生產,並且由於算法足夠多,能夠覆蓋各種長尾場景,大大降低了複製成本。因此我們認為,大模型是未來AI行業的必然趨勢。
圖表6:蒸餾技術是類似於老師-學生傳遞知識的過程

資料來源:ICCV2019,華為雲,中金公司研究部
2020年超大模型GPT-3發佈,衍生出DALL·E與CLIP模型。隨着GPT-3在多個自然語言處理基準上展現超強性能,該模型延伸至圖像領域,衍生出匹配文字和圖像的CLIP模型,以及由文字生成圖像的DALL·E模型。2022年4月,OpenAI推出DALL·E 2,基於CLIP和Diffusion模型,分辨率提升了4倍,準確率更高,業務更廣:除了生成圖像,還能二次創作。
圖表7:GPT-3衍生出DALL·E與CLIP模型

資料來源:OpenAI官網,中金公司研究部
Stable Diffusion由Stability AI公司提出並於2022年7月開源,是AIGC熱度提升的重要驅動力。Stable Diffusion的重要貢獻在於使用空間降維解決內存和模型推理時長痛點,採用Latent Diffusion Model (LDM) 方式,在模型複雜度和圖像質量之間達到平衡。Stable Diffusion不僅使用户僅在消費級顯卡上就能夠快速生成高分辨率、高清晰度圖像,而且建立開源生態,大大降低用户的使用門檻。
圖表8:Diffusion模型原理示意圖

資料來源:Stability.AI,中金公司研究部
圖表9:Stable Diffusion模型原理示意圖
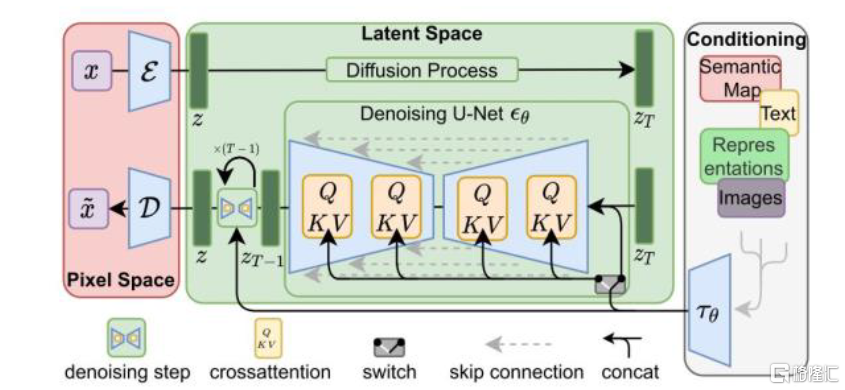
資料來源:CVPR 2022《High-Resolution Image Synthesis with Latent Diffusion Models》,中金公司研究部
ChatGPT:基於GPT-3.5版本的InstructGPT,開放接口,風靡全球
2022年11月30日,OpenAI發佈了語言大模型ChatGPT,通過大規模預訓練(GPT-3.5)和自然語言生成技術實現多輪對話問答。該模型以對話的形式與用户進行自然交互,核心方法是基於人類反饋的強化學習(RLHF),能夠實現“回答後續問題、承認錯誤、質疑不正確的前提和拒絕不適當的請求”的能力。
圖表10:ChatGPT擁有智能問答、多輪對話的能力

資料來源:ChatGPT,中金公司研究部
圖表11:InstructGPT公開API後用户的使用功能和頻率

資料來源:《Training language models to follow instructions with human feedback》(OpenAI,2022),中金公司研究部
ChatGPT基於IntructGPT模型思路,在GPT-3.5基礎上進行微調,在數據源選擇與數據標註領域進行優化。ChatGPT僅僅在訓練數據和微調模型(GPT-3.5)方面與InstructGPT不同,其餘的訓練流程和方法二者相同。相較於GPT-3的訓練集只有文本,ChatGPT的訓練集基於文本和代碼,新增代碼理解和生成的能力。目前,OpenAI仍未公佈ChatGPT的論文,但根據其主頁可以得知它的方法與InstructGPT相同,本文從InstructGPT 展開技術路徑:
圖表12:InstructGPT主要訓練流程分為三步,搭建有監督SFT模型、強化學習模型

資料來源:《Training language models to follow instructions with human feedback》(OpenAI,2022),中金公司研究部
► 第一步:OpenAI採集了基於prompt(即大量的提示文本)訓練方式的數據集,提示訓練模型“問題在此開始”,並詳細説明了下游任務。將此數據集交給約40人的專業團隊標註人類希望得到的回答,並以該訓練集進行監督學習微調GPT-3(參數數量為175B),得到微調後的模型SFT。(ChatGPT微調的模型是未公開的GPT-3.5,比GPT-3參數量級更大)
► 第二步:將第一步中的數據和GPT-3訓練集的一部分數據混合,使用微調模型SFT進行預測,對每個輸入得到N個結果,此時專業人員會根據選項的好壞對其進行排序,並把排序後的數據用來訓練獎勵模型(RM)。
► 第三步:使用PPO的強化學習方法更新參數,使用SFT再預測一次數據集的結果通過第二步的獎勵模型進行打分,計算獎勵(reward)。最後將獎勵分數通過PPO返回SFT進行訓練。
大模型不僅對應於ChatGPT,更是整個AIGC領域的技術基礎
圖表13:AIGC關鍵技術突破時間軸所示,GAN帶來生成模型雛形,GPT等NLP大模型是通用智能的技術基礎
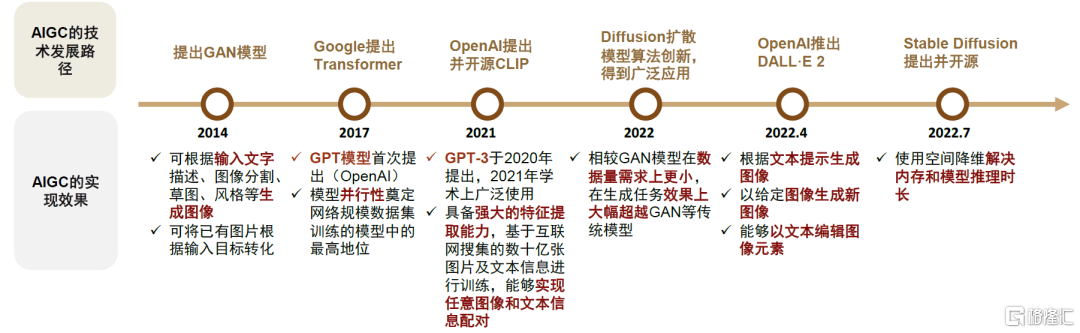
資料來源:OpenAI官網,《Denoising Diffusion Probabilistic Models》(Ho et al. 2020),中金公司研究部
生成對抗網絡GAN不斷演進,助力AI生成圖像逐步完善,為AIGC興起的原始思路。GAN (Generative Adversarial Networks,生成對抗網絡) 於2014年提出,主要原理為,將兩個神經網絡(生成網絡和判別網絡)相互對立,以提高模型輸出結果的質量。通過GAN,計算機可以根據輸入的文字描述、圖像分割、草圖、風格等生成實際不存在的圖像,也可以將已有圖片根據輸入目標轉化,肉眼幾乎無法分辨真假。AI能夠將輸入的簡易指令轉化為圖像等複雜生成結果,具備支撐AIGC的技術條件。
GAN是AIGC發展的基礎框架,但技術方面仍有多處不足。在AIGC由學術界實驗室嚮應用導向的過程中,生產者對於圖像生成的質量、分辨率提出更高的要求,GAN的不足之處體現在:一方面容易生成隨機圖像,對結果的掌控力較差,另一方面是圖像分辨率較低,能夠支撐宏偉圖景、難以滿足細節要求,此外,生成過程中依賴對原有圖像數據的模仿,缺乏創新性。基於以上不足,AIGC發展在學術界、應用界均遇發展瓶頸。
Transformer大模型的計算並行性奠定了網絡規模數據集訓練的模型中的最高地位。2017年穀歌提出Transformer模型,其並行化的語言處理方式使得並行計算的效率得到大幅的提升。基於Transformer模型,OpenAI於2018年首次提出了GPT模型,能夠在無監督的情況下進行訓練,在大語料場景下能夠顯著的改善模型效果,正式將NLP(自然語言處理)帶入預訓練時代。
CLIP模型(Contrastive Lauguage-image Pre-training)由OpenAI提出並在2021年開源,圖像-文本對應能力為AIGC提供落地基礎。CLIP是以文本為監督信號來訓練可遷移的視覺模型,是多模態領域的重要推動力,主要價值在於具備強大的特徵提取能力,基於互聯網蒐集的數十億張圖片及文本信息進行訓練,能夠實現將任意圖像和文本信息配對,為AIGC的主流應用由文本生成圖片和視頻奠定多模態應用基礎。
Diffusion擴散模型在2022年以多維度技術優勢進一步推動AIGC應用。2015年,Diffusion模型最早在ICML的論文《Deep Unsupervised Learning using Nonequilibrium Thermodynamics》被提出,2020年由Jonathan Ho等人在《Denoising Diffusion Probabilistic Models》中提出的DDPM模型引起了學術界更多關注。模型本質分為前向擴散、反向生成兩階段,分別完成對圖像逐步添加高斯噪聲-隨機噪聲、去噪聲的過程,相較GAN模型在數據量需求上更小,在生成任務效果上大幅超越GAN等傳統模型。
DALL·E及升級版DALL·E 2項目基於CLIP和Diffusion大模型開發,AI具備依據文字進行創作的能力,AIGC作畫領域落地進入快車道。DALL·E系統由微軟注資的OpenAI於2021年1月推出,並於2022年4月更新至DALL·E 2,該系統基於CLIP和Diffusion關鍵模型建立,具備三種功能:1)根據文本提示生成圖像,2)以給定圖像生成新圖像,3)以文本編輯圖像元素。2022年7月,DALL·E 2開啟邀請制公測,生成圖像在關注宏偉場景的同時關注人物關係細節,是AIGC早期落地的重要標杆事件。
Stable Diffusion於2022年7月建立完全開源生態,是2022年AIGC落地門檻降低、應用熱度進一步提升的又一重要驅動力。AIGC在2022年已經具備了CLIP開源文本-圖片多模態模型基礎、LAION開源數據庫、Diffusion大模型算法框架創新,Stable Diffusion的重要貢獻在於使用空間降維解決內存和模型推理時長痛點,以及2022年7月構建的完全開源生態。部署在國內的二次元創作Novel AI模型即是基於Stable Diffusion模型發展而來,作畫方式更為多元,包括文本生成圖像、原畫改寫、簡筆畫生成等模式,出圖質量較高,深受二次元愛好者的認可。至此,開源生態推動AIGC的數據、模型與算力問題初步解決,直接降低了使用者的門檻,滲透進多個垂直領域。
展望未來,AI技術逐步進入無監督學習時代,支撐AIGC的產業化發展。2012年以前,AI模型大多為針對特定場景進行訓練的小模型,無法拓展至通用場景,且仍需要人工調參和大量數據來提升模型精度。隨着技術發展,AI可以在圖像、文本等多維度上實現融合互補,在無監督情況下自動學習不同任務、並快速遷移到不同領域。例如,AI驅動虛擬人可以利用現實人臉及聲音等多維度數據生成形象,GAN、Diffusion模型可以通過文字、圖像等數據進行多模態創作。我們認為,AI技術已呈現出能穩定支持內容生產的發展趨勢,未來有望突破“小作坊”式生產,助力AI內容生產進入工業化時代。
商業篇:以OpenAI投資方向為風向標
落地仍在探索期,跨模態打開場景空間
AIGC:跨模態應用是未來發展趨勢,落地尚在早期
在深度學習模型支撐下,早期AIGC在文本生成領域開啟內容創作落地,逐漸向音頻生成、圖像生成等領域推廣。深度學習帶來AI在學術和應用落地領域的分水嶺,大模型進一步將應用接近認知智能。2014年起,AIGC在文本理解、結構化協作領域小範圍應用,按照特定模式提取情感語義,或按照框定模板生成結構化內容。在2018年NLP領域BERT、GPT系列大模型出現後,非結構化協作等高自由度創作具備落地空間。此外,AIGC在音頻-音頻生成、圖像-圖像生成和視頻-視頻生成創作等領域跨越落地門檻,在單模態發展中呈現多點開花局面。
圖表14:AIGC應用全景圖一覽

資料來源:量子位智庫,中國信通院,Tom Mason,OpenAI官網,中金公司研究部
DALL·E 2是一個由OpenAI開發的人工智能模型,它具備三種功能:1)以文本提示生成新圖像;2)以給定圖像生成新圖像;3)以文本編輯圖像元素。DALL·E 2的使用方法很簡單,用户只需在軟件提示框中發送文字提示或圖像修改文字,或選擇給定墊圖,AI便會根據輸入生成結果。用户可以隨意輸入想要表達的內容和所希望的藝術風格,DALL·E 2可以模仿許多知名藝術家的風格,並準確地描繪動物和人物,並表達他們之間的關係(例如打架或聊天)。
DALL·E 2目前採取付費購買次數的商業模式:加入Open Beta項目後,首月可以獲得50個免費點數,每一個點數對應一次繪圖,之後每個月可以免費補充15個,測試第一階段的價格是15美元115個點數。花費點數生成圖像後,用户將獲得使用DALL·E創建的圖像商業化的完全使用權,包括重印、銷售和商品化的權利。
圖表15:DALL·E 2 通過文字添加圖片元素

資料來源:DALL·E 2官網,中金公司研究部
圖表16:DALL·E 2通過文字輸入生成圖片結果示例

資料來源:DALL·E 2官網,中金公司研究部
全球範圍內AIGC獨角獸已初步具備B+C端的變現能力,但海外公司明顯領先於國內。AIGC應用層可分為圖像、文本、視頻、音頻,海外AIGC企業如Jasper、Grammarly等已經積累大批用户羣體,年收入超千萬美元;大部分企業都至少啟動了A輪融資,融資金額相對較大。
圖表17:全球AIGC應用層企業梳理

資料來源:鯨準,中金公司研究部
注:統計時間截至2023年1月29日
而國內相關技術企業進展較慢,參與方以應用層為主。要提高國內AIGC獨角獸發展速度,必須加快基礎層建設,提高核心競爭力,同時找到更好的商業模式並具備變現能力。
圖表18:國內AIGC應用層企業梳理

資料來源:鯨準,中金公司研究部
注:統計時間截至2023年1月29日
ChatGPT應用場景廣泛,海外已有龍頭落地成功案例
ChatGPT具備強大自然語言處理、多輪問答能力,可落地於廣泛的應用場景。ChatGPT將在未來投入商業化領域,通過強化的上下文理解能力,優化銀行、電商等客服機器人,生成商品描述和營銷文案,以及協助翻譯工作,大大提高服務質量。目前,ChatGPT已經成功在海外市場得到了應用,為BuzzFeed提供了個性化測試,並幫助Amazon解決了客户和工程師面臨的技術難題。
► 個性化測試:2023年1月,美國新聞聚合網站BuzzFeed官宣將依託OpenAI為其用户互動欄目Quizzes製作和個性化各種小測試。ChatGPT會生成一系列提問,再根據個人的回答產生用户獨有的、可分享的文章。不久前,Meta向BuzzFeed支付了數百萬美元,以讓BuzzFeed為Meta的平台生成內容,並培訓平台上的創作者。
圖表19:BuzzFeed利用ChatGPT個性化Quizzes推送內容

資料來源:BuzzFeed官網,中金公司研究部
► 嵌入微軟全系列產品:2023年世界經濟論壇期間,微軟首席執行官薩蒂亞·納德拉(Satya Nadella)在接受《華爾街日報》採訪上時表示:微軟將擴大對OpenAI技術的訪問並把ChatGPT嵌入到微軟各大系列產品,例如Bing、Office、Outlook等。屆時,ChatGPT將在搜索引擎、日常辦公、收發郵件中發揮其智能的語言理解和問題解答能力,使生產效率更上一層樓。
OpenAI通過戰略投資,產業賦能,加速ChatGPT在實際應用中落地。作為AI行業龍頭OpenAI,公司不止自身持續開發出驚動業界的AI模型如GPT系列模型,而且創立基金投資於AI創業公司,不斷拓寬AI應用邊界,重塑人類的創造力、法律、生產力、教育等方面能力,這四大領域也構成了OpenAI在2022年的四大投資風向標。
Descript:AI驅動多媒體創新,重新定義音視頻剪輯軟件
音視頻轉文字,把繁瑣的剪輯工作變得像編輯文檔。Descript是一個像文檔一樣工作的編輯音視頻的軟件,包括轉錄文字、播客、屏幕錄製等功能。其最大的特色功能是可以將音視頻內容轉錄成文本,將文本中的每個詞和媒體文件的時間戳對應,允許用户通過編輯這個轉錄的文本信息來編輯原始音視頻。Descript主要功能如下:
► 轉錄:將音視頻中的內容轉錄成文本,自動識別不同的講話。按照分鐘數計費,目前支持 22種語言;也可使用人工轉錄。
► 屏幕錄製:支持快速錄製、編輯和分享屏幕錄製的視頻,遠程錄製允許用户在使用Zoom等會議軟件時調用Descript。
► 音視頻編輯:1)刪除:當用户刪除詞句,音頻中對應的詞也會被刪除;2)生成(收購加拿大初創Lyrebird後推出Overdub功能):當用户通過打字添加文本,AI可以生成該用户的聲音;3)一鍵檢測和刪除語氣詞:例如“um”、“uh”等大量重複使用的單詞。
圖表20:Descript操作界面:使用腳本編輯錄音,添加場景來排列視覺效果
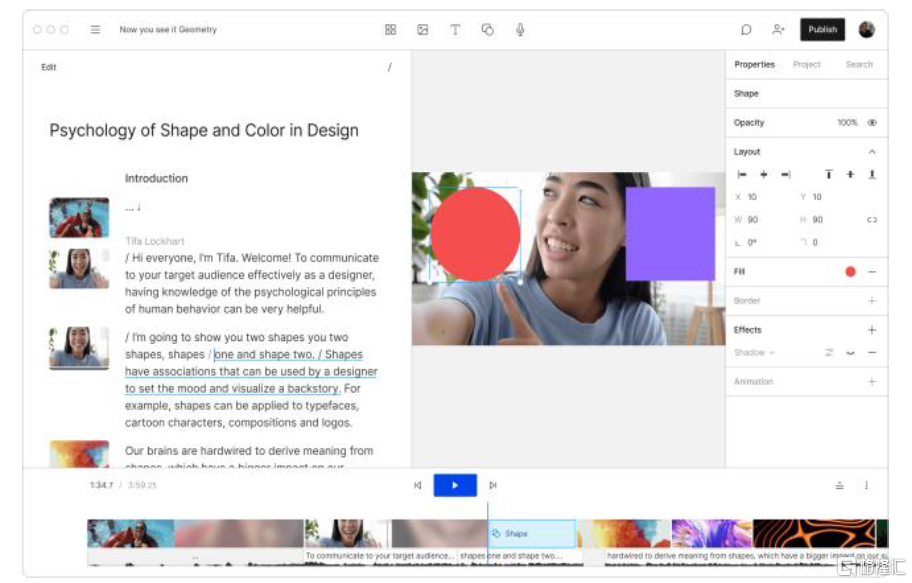
資料來源:Descript官網,中金公司研究部
圖表21:Overdub:創建文本到語音的轉換模型,或選擇超逼真的庫存語音

資料來源:Descript官網,中金公司研究部
Descript定位於協同編輯工具,根據團隊用户數和每月轉錄時長進行收費。免費版每月有1小時的轉錄時長;Creator 版本每月10小時轉錄時長,定價12美元;Pro版本每月30小時轉錄時長,定價24美元。Descript目前已完成4輪融資,總融資額達1億美元。2022年11月,OpenAI領投C輪5,000萬美元融資,估值達5.5億美元。
Harvey:AI協助律師撰寫文件,提升法律工作流程效率
Harvey有望作為法律的自然語言接口,大幅減少簡單重複的法律流程工作。Harvey是面向律師羣體的AI助手工具,為法律工作者提供統一的、直觀的操作界面。同時藉助強大的生成式語言模型(主要為GPT-3)的能力,可以在律師的工作流程中幫助處理一系列繁雜的工作,如研究、起草、分析法律相關條文,使律師能夠將更多時間花在工作中高價值部分。
Harvey目前仍處於內部測試階段,但已受到OpenAI的關注和青睞。2022年11月,Harvey AI獲得OpenAI的500萬美元投資,Google AI負責人Jeff Dean、Mixer Labs聯合創始人Elad Gil以及一批天使投資人跟投。本輪融資後,Harvey將正式向律師客户羣體推出服務。
Harvey背靠OpenAI和微軟,享受更多資源領先競爭對手。市場格局中,Casetext同樣利用人工智能技術進行案例搜索,進行法律研究、摘要起草等工作。據OpenAI表示,Harvey將受益於與OpenAI的關係,能夠提前訪問微軟的新OpenAI系統和Azure資源。
Mem:AI學習用户工作、習慣,提供智能化筆記
Mem作為一款輕量筆記工具,致力於打造“世界上第一款自動組織的筆記產品”,提高用户的工作效率與生產潛力。Mem主打快速記錄與內容搜索,利用人工智能技術提供預測、自動整理筆記內容,並且允許用户添加話題標籤、標記其他用户、添加定期提醒等。
目前,Mem為Twitter推出了Mem It應用,允許用户保存推文串,獲得AI生成的內容摘要,並看到類似推文的建議。Mem的內置工作助手Mem X也得到進一步完善,增添了智能寫作和智能編輯等新功能,利用人工智能根據提示生成文本、總結文件、為文件生成標題,並讓用户使用自然語言命令來編輯或格式化文本。
Mem採用Freemium(免費增值)的定價模式,從個人用户向團隊和企業版進行拓展。付費版Mem X套餐價格是10美元/月,在免費版基礎上增加了AI的能力,能夠自動整理和歸類信息;付費團隊和企業版則增加更多存儲空間、團隊管理能力以及安全性等內容,團隊版的定價是15美元/月,企業版需根據具體情況定價。在OpenAI的支持下,Mem計劃進一步開發人工智能驅動的功能和體驗。2022年11月,OpenAI領投A輪2,350萬美元融資,本輪融資中估值1.1億美元,累計融資總額達2,900萬美元。
從AI個性化角度出發,Mem與市場中常見的工作管理軟件形成差異化競爭格局。工作協助平台Glean於2022年5月完成1億美元的C輪融資,為SaaS企業提供一致的搜索體驗,市值估值達10億美元;Atlassian類似維基的協作工作平台Confluence適合於遠程操作的團隊工作,能夠有效的融合知識與協作。Mem致力於生成式知識管理方法,其個性化機器學習模型超越簡單的搜索與記錄。
圖表22:Mem操作界面:利用人工智能技術實時整理筆記

資料來源:Mem官網,中金公司研究部
圖表23:Mem主要功能:九大核心功能打造自動組織的筆記

資料來源:Mem官網,中金公司研究部
Speak:AI驅動語言學習,向學習者提供實時反饋
Speak是具有人工智能功能的英語學習平台。Speak利用AI能力,開發了一系列對話內容,模擬了日常的各種場景和互動,通過和AI導師的互動來提高用户口語。其最大的特點是AI導師可以基於對話內容,提供實時的反饋,包括髮音、語法、詞彙等。
Speak主要通過提供自動續訂的月度和年度訂閲的模式盈利。Speak在韓國有近10萬付費用户,2022年開設約1,500萬節課程,ARR超千萬美元。定價方面,Speak按年度訂閲約100美元/年,按月付22美元/月。
Speak將訓練新的語種,進一步拓展至韓國以外的市場。2022年11月,OpenAI領投B輪2,700萬美元融資。下一步,公司計劃拓展新的語種與市場(例如日本)並投資於利用文本生成模型的功能(例如GPT-3),加速開發新的對話語言體驗。
市場格局方面,Duolingo是成熟的語言學習軟件巨頭。作為全球用户量最大的語言學習平台,Duolingo提供超過40門語言課程,目前月度活躍用户4,000萬,付費用户190萬,ARR達3.6億美元。
圖表24:Speak:提供真正的交互式口語學習體驗產品
資料來源:Speak官網,中金公司研究部
圖表25:最先進的AI語音技術:0.1s延遲,95%準確率,100%實時

資料來源:Speak官網,中金公司研究部
AI還將不斷增強人類,在更多低腦力領域實現效率倍增
AI將人類從簡單重複的任務中解放出來,專注於高價值、創新型的工作。通過解決密集型勞動、重複性勞動的痛點,AI正在逐步取代部分人工工作,給社會帶來降本增效的價值。在未來,隨着AI技術的不斷提高,它將在更多的低腦力領域提供支持,從而幫助人們實現更高效的工作。
除了消除重複性任務,AI同樣起到簡化決策與提供新洞察等作用,提升決策的速度和效率。據Gartner預測,截至2023年,超過1/3的大型企業將使用決策智能實現結構化決策,隨着決策智能成為業務流程的核心部分,決策制定得比以前更快、更容易,而且成本更低。例如,在醫療領域,AI技術已經成為支持臨牀診斷、疾病預測、個體化治療等的重要工具;在金融領域,AI技術支持了金融機構快速、高效的風險評估、客户服務等。
圖表26:AI在執行環節、低級別決策環節具備替代人工的潛力

資料來源:ARK,中金公司研究部
圖表27:ARK測算:2030年,AI軟硬件公司年收入總和有望達15.7萬億美元

資料來源:ARK,中金公司研究部
格局和展望篇:行業格局有望走向底層集中、垂類多點開花
MaaS是商業模式演進的潛在方向
算法邊際成本是AI競爭核心焦點,碎片化需求使得成本居高不下
低邊際成本是大模型的優勢,碎片化的需求成為降低成本難的關鍵因素。目前國內大部分AI工作是以項目制的形式進行的,落地還停留在“手工作坊”階段,存在重複造輪子情況,邊際成本高。而且目前大部分場景數據規範性差、長尾,且採集方法落後,導致工作量較大,嚴重影響AI大模型進展。
碎片化的本質原因在於現階段AI模型的通用性低,單個模型只適用特定任務。例如,在工廠場景下檢測零部件、在醫療圖像中檢測病理特徵,雖然本質上都是檢測,項目過程中都需要重新收集、標註數據、訓練模型。由於客户需求多樣,以至於幾乎每個項目都要重複進行這一流程,研發流程難以複用,重度依賴人力,邊際成本很高。
► 需求端:全社會的數字化是人工智能的重要目標,同時也意味着大量的建模需求。隨着數字信息世界、物理世界融合,產生的數據量是以前的成千上萬倍,監控和管理這些信息牽制了大量人力,未來需要大量的AI模型來處理這些信息。而大量的模型需求需要較高的AI模型生產效率、較低的算法邊際成本。
► 供給端:AI技術相對較新,引起業界關注僅10年,人才培養不足,導致人才稀缺。從事AI技術研究與開發的人員有限,難以滿足市場大量模型需求。此外,技術快速發展,技術人員和訓練數據集也需要不斷學習更新。
圖表28:弱人工智能階段長尾場景種類繁多導致項目碎片化

資料來源:量子位,中金公司研究部
AI行業不會向碎片化的方向發展,而是強者愈強,用大模型結合底層全棧自研來解決邊際成本問題。在大模型路線下,AI模型的邊際成本還會受益於三個因素的影響大幅降低:
► 底層基礎設施可複用,降低邊際成本。以商湯科技的AI大裝置為例,公司多年累積的硬件、框架和AI算法和落地經驗結合起來,一起融合到AI大裝置,能儘可能的減少重複研發。
► 模型研發流程可複用,大模型提升AI通用性。在大模型壓縮製造小模型的工業化生產方式下,AI公司可以生產大量的、覆蓋不同場景的模型。這樣,在遇到新場景的情形下,可以通過將原有的模型模塊化組裝,快速製造新模型,無需針對新場景再次定製化生產。
► 研發流程自動化(AutoML),開發門檻降低,人員成本降低。AutoML能自動執行AI流程中的大部分工程性任務,減少了AI模型生產過程中對人工的需求量,且由於機器學習門檻的降低,不再需要招聘深度理解AI工程的專家,使得開發人員的成本降低。
圖表29:AutoML在數據、模型和優化三個環節減少對深度學習專家的依賴
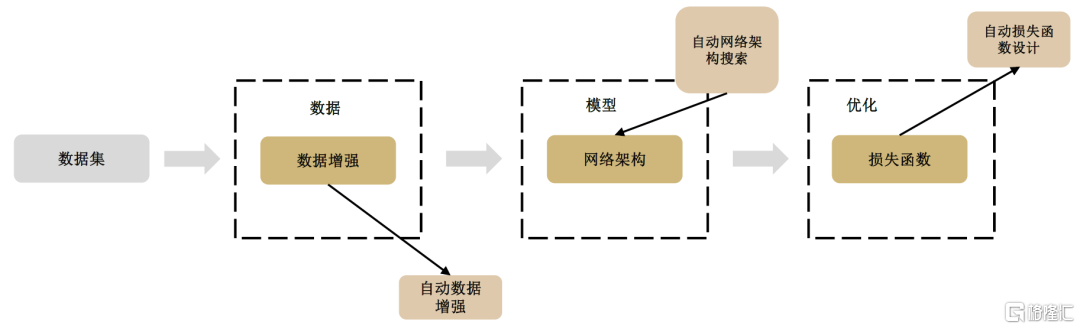
資料來源:CSDN,中金公司研究部
復刻ChatGPT為代表的模式較難,多維度需求鑄就高門檻
ChatGPT基於GPT-3.5微調而來,該超大泛化模型對成本、組織力、工程壁壘、大算力和底層框架都提出極高要求。隨着模型的不斷擴大,模型訓練和維護成本也在不斷增加;在技術層面上,需要先進的底層技術和高效的框架來保證模型訓練的穩定性和效率,而且構建的模型必須要有很高的泛化能力,這需要研發團隊有相當高的技術水平和工程能力。
► 訓練成本:對於訓練基礎模型GPT-3為例,訓練一次所要消耗的成本高達近8400萬元人民幣。這不僅需要資本,也需要公司的組織力和戰略支持。依賴於小規模團隊的試驗探索來創新不再可能。
► 標註數據:由於ChatGPT/InstructGPT模型訓練使用的是prompt方法,在訓練的第一步OpenAI僱傭標註師對1.3萬條數據進行人工回答,同時在第二部分需要對模型給出的3.3萬條答案進行排序。在論文附錄中可以看到OpenAI對於人工標註數據的生成有諸多細節和心得。
► 強大算力:ChatGPT訓練所耗費的算力大約為3640 PF-days,即假設每秒運算一千萬億次,需要連續運行3640天。訓練大模型需要強大的算力,而優化大規模算力背後的技術底層框架需要深度定製和自主研發能力,這些因素都構成了諸多工程壁壘。
除了顯性的成本外,場景、流量、數據壁壘和社會包容度所形成的隱性成本同樣不可小覷。不同的場景需要專門的數據集,數據的獲取和標記需要額外的成本;數據的質量、隱私和安全構建起數據壁壘;此外,公眾對不同規模公司發佈的新模型的包容度是不同的。
► 用户真實體驗:除了標註人員需要標註,也需要用户通過測試API提出實際使用中的問題獲取prompt,得到更多User-Based數據,縮小和用户需求的差距,不斷迭代優化,該過程需要更高昂的數據清洗成本和時間成本。
► 基於場景反饋:ChatGPT/InstructGPT的核心創新點在於RLHF,這不僅侷限於標註師的反饋,也需要實際用户使用中的反饋。例如Midjourney在用户使用中生成4張圖像,用户的點選就會作為reward反饋傳回公司進行迭代強化學習。找到場景、擁有流量,使得廣大愛好者能夠眾包式的迭代模型,也是商業模式上的挑戰。
► 社會包容程度:對於初創公司,這種內測模型更容易發佈,用户包容度更高,但隨着模型表現出色,用户期待值更高,未來再通過免費內測形式會遇到更多問題。例如谷歌、Meta都曾發佈語言模型測試,但因數據質量層次不齊,輸出結果有明顯偏誤,被迅速下架。
圖表30:Midjourney生成圖像用户反饋界面

資料來源:Midjourney官網,中金公司研究部
圖表31:Meta發佈的語言模型GALACTICA上線僅兩天就因輸出結果有偏誤而光速下架
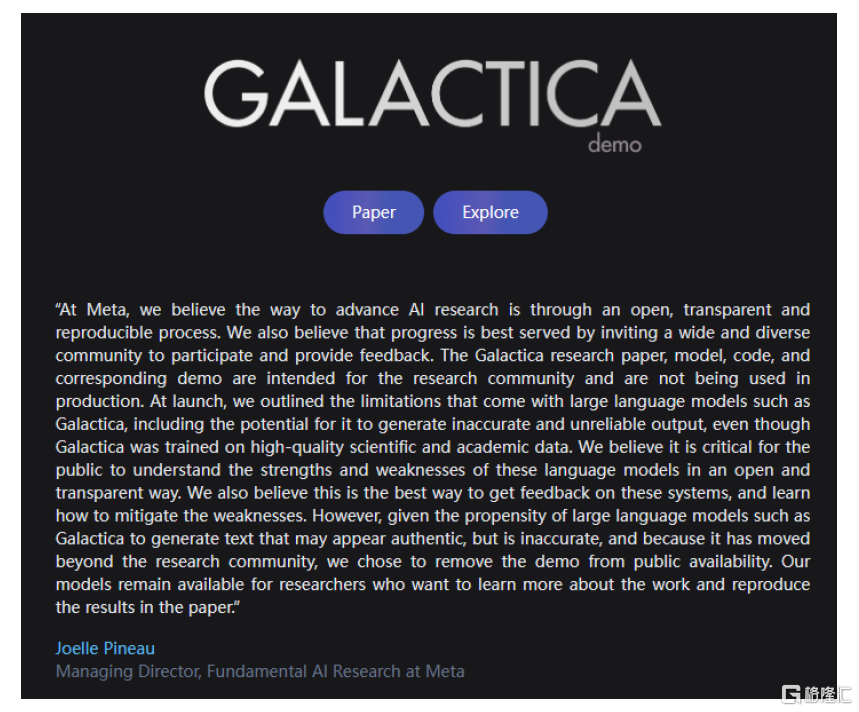
資料來源:GALACTICA官網,中金公司研究部
產業鏈百花齊放,創業公司垂直領域也具備機遇
大模型路線下,行業格局必將走向集中。不同於深度學習的技術路線,大模型路線的高壁壘和“前期投入大,邊際成本低”的模式決定了行業必將走向集中格局,缺少資源的中小參與者難以跟隨技術發展的步伐。
在中長尾走向寡頭市場,在關鍵垂類仍有Know-How的魅力。儘管行業走向集中,我們卻並不認為行業會走向影視作品中一個超級人工智能統領全球的景象。在市場空間足夠大的關鍵垂類中,Know-How和數據壁壘仍舊能夠顯著增加模型的表現,同時獲得足夠的經濟回報。而在更中長尾的場景中,有泛化多模能力的超大模型將呈現多強格局,滋養諸多的ISV在其基礎上搭建應用,或者進一步調優。
圖表32:我們預測的未來格局

資料來源:中金公司研究部
圖表33:InstructGPT論文顯示:經過知識調優後的小參數模型效果遠超未調優的大模型
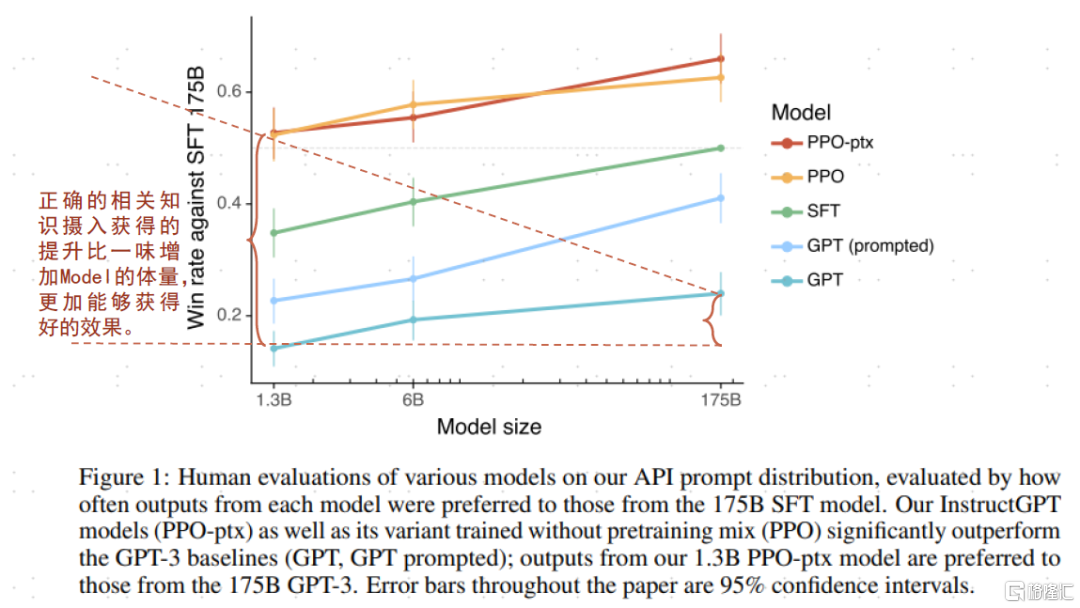
資料來源:《Training language models to follow instructions with human feedback》(OpenAI,2022),中金公司研究部
未來商業模式探討:Model-as-a-Service是潛在方向
目前ChatGPT還沒有明確的盈利商業模式,但我們認為MaaS是一個潛在方向。未來的商業模式可以參照Hugging Face踐行的AI開源社區模式以及潛在方向:模型即服務Model-as-a-Service,即Hugging Face提供的AutoTrain和Inference API & Infinity解決方案。MaaS將模型訓練、維護和部署的過程轉移到雲服務上。這樣的方式不僅提高了效率,還降低了客户對模型開發和維護的依賴,使其能夠更加專注於業務上的投入。
圖表34:Hugging Face商業模式
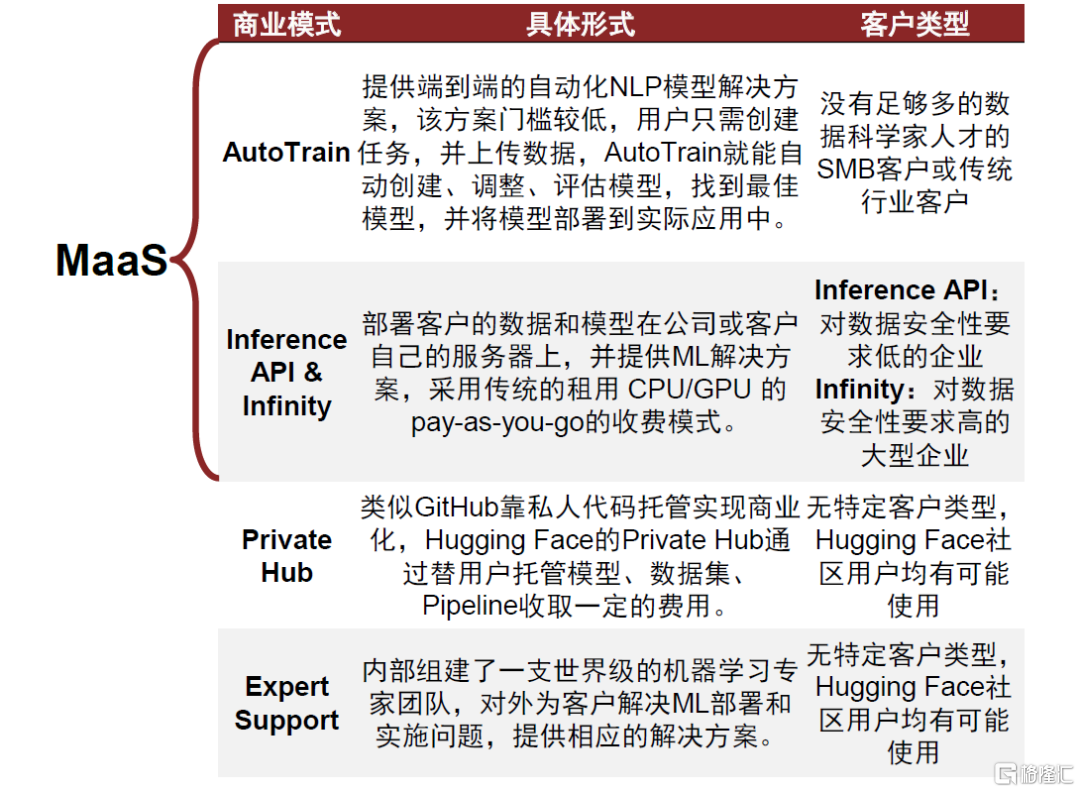
資料來源:元宇宙官網,中金公司研究部
商湯科技是國內領先的人工智能公司,其自主研發的AI基礎設施SenseCore,實現了通過AI平台化賦能百業,商業模式類似MaaS。與傳統的AI技術不同,商湯把人工智能的核心底層基礎設施、軟件平台和應用層打造成了一個通用的生態系統,可以被各種應用程序和服務輕鬆使用,而不需要對模型進行專門的開發。這種模型即服務(Model-as-a-Service)的架構,可以幫助企業更快速地實現人工智能的價值。
圖表35:商湯建立了包括底層基礎設施、AI軟件平台及應用層平台的AI生態系統

資料來源:弗若斯特沙利文,商湯科技,中金公司研究部
風險
技術進展不及預期:人工智能作為前沿新興技術,仍處於技術的快速發展期,其進展有一定的不確定性,若技術進展不及預期,可能導致產業化進展緩慢。
行業競爭加劇:人工智能是產業的熱點,未來商業價值顯著,科技巨頭、初創公司均在此領域佈局,未來垂類及應用層的行業競爭可能會進一步加劇。
商業化落地節奏不及預期:商業化落地是人工智能能否順利走向下一階段的關鍵點,若商業化落地節奏不及預期,對人工智能的進展將帶來負面影響。


More Content

Physical Store(set to open in Q2 2025)
Address:
Shop LMC 307, 3/F, Lok Ma Chau MTR Station, Lok Ma Chau
Opening Hour:
9am - 9pm (Mon - Sat)
10am - 6pm (Sun and Public Holiday)

(set to open in Q2 2025)





