





本文來自格隆匯專欄:半導體行業觀察
在這篇文章中,Locuza和SemiAnalysis 將分享和分析英特爾 Meteor Lake 計算模塊在Intel 4 節點上的試片。通過這個die shot,我們可以分析內核、緩存和結構中的各種結構,我們可以使用這些結構來確定與 Intel 7 節點相比,面積僅減少了大約 40%。這種實現的密度提升與英特爾之前聲明的Intel 4 工藝節點將擁有的 2 倍理論密度提升非常不同。
Intel 4 是 Intel 首個採用 EUV 的製程技術,應該標誌着 Intel 重返與台積電在製程技術上的競爭。我們還將討論 Meteor Lake 和 Arrow Lake 的系統架構,以及重新設計的 Redwood Cove 和 Crestmont 核心中的核心架構變化。
最後,我們將討論產能爬坡時間表,競爭定位,以及對製造成本的一些擔憂。

在幾周前,英特爾舉辦了他們自己的名為 Vision 的會議,會議涵蓋了廣泛的主題,包括當前和即將推出的產品。SemiAnalysis 能夠參加並與英特爾的人們進行了許多精彩的討論。最有趣的事情之一是Pat Gelsinger在回答我們的問題時直截了當地表示,他將收購更多的 SAAS 公司。其他亮點包括能夠查看英特爾的一些產品並親自向工程師詢問技術問題。
我們的亮點之一是有機會為各種英特爾產品拍照!在這裏,我顯然很高興地拿着一些英特爾的網絡產品,Tofino 2、Tofino 3 和 Mount Evans IPU(DPU)。雖然我們還不能深入談論 Tofino 3 的功能,但它是世界上最大的 BGA 封裝。換句話説,那是很多硅。
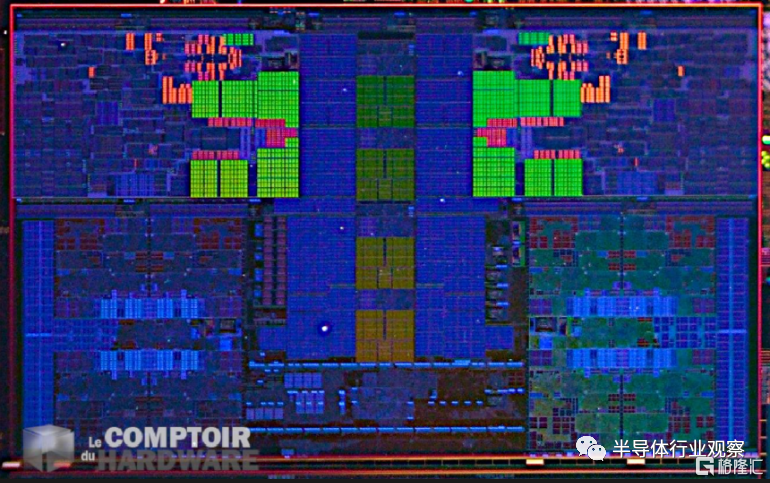
展會上最有趣的實物是硅晶片。其中包括 Alder Lake 桌面 CPU、下一代 Sapphire Rapids 數據中心 CPU 和下一代 Meteor Lake 計算tiles。他們還展示了他們的intel 20A 和英特爾 18A 工藝技術的一些測試晶圓。雖然我們自己拍了幾張Meteor Lake的照片,但我們在Comptoir-Harware的朋友們卻能拍到更好的照片!他們能夠使用 Meteor Lake 晶圓並放大到晶圓上的單個芯片。這張圖片是我們將要進行的大部分分析的基礎。
使用 Meteor Lake 晶圓、封裝和封裝過程視頻的第一方和媒體圖像,我們可以確定英特爾在 Meteor Lake 上使用的小芯片的各種裸片尺寸。由各種 CPU 核心塊以及一些相關結構組成的計算塊只有約 40mm 2。
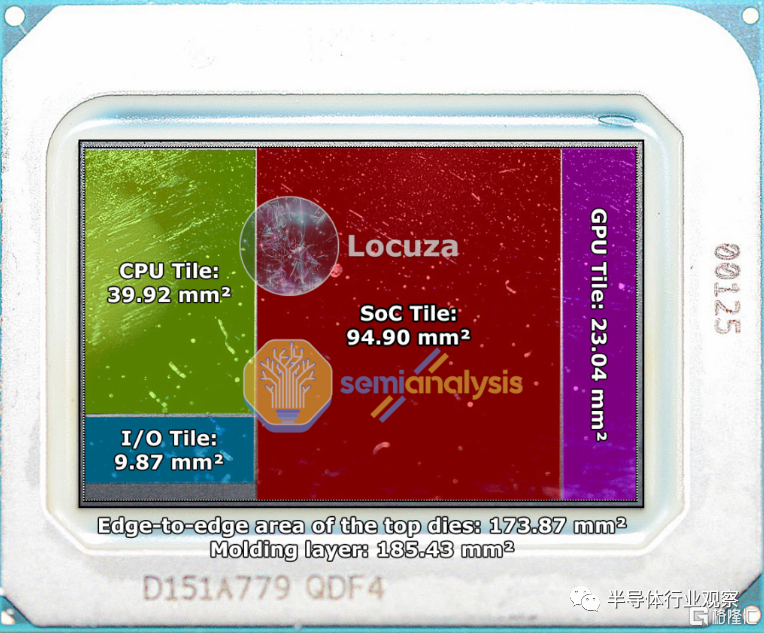
其他die的尺寸為~174mm 2、~10mm 2、~95mm 2和~23mm 2。這些芯片中的每一個的確切用途都沒有得到證實,但我們相信我們相信它們是用於 IO、SOC 和 GPU 的。我們將在本文後面的部分中深入探討其中的每一個。
首先,讓我們談談計算tile。
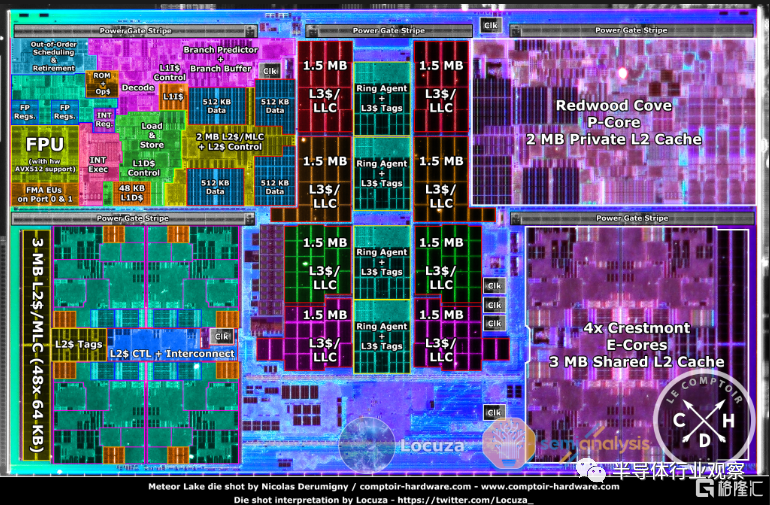
Locuza能夠識別和註釋芯片上的大多數結構,包括 2 P Redwood Cove 內核、8 E Crestmont 內核以及連接到環形總線(ring bus)的最後一級緩存。
這是我們要注意分析並不完美的地方,並且有一些警吿。Meteor Lake 圖像是使用標準 DLSR 相機拍攝的。Locuza 能夠糾正一些因素,比如離軸傾斜(off axis tilt),但它仍然不是最理想的並且限制了準確性。這些圖像不是最高分辨率的,因為它們是在展廳而不是在實驗室中完成的。劃線餘量(scribe line margin)和其他一些因素也存在不確定性。這使我們相信die中結構的潛在誤差範圍在中高個位數範圍內。並非所有結構和結構尺寸都保證 100% 正確,但我們相信我們準確地表示了物理佈局設計。我們將完全按照測量的方式呈現數據。

左邊是當代Alder Lake的Golden Cove,右邊是Meteor Lake的Redwood Cove。從高層次來看,Redwood Cove 似乎並沒有顯著改變,大多數子單元看起來與以前非常相似,沒有改變位置或相對大小比例。在許多結構中,Redwood Cove 主要是一種工藝技術縮小,但仍有不少立即可見的架構變化應該有助於 IPC 和性能。
例如,L1 緩存似乎相對較大(圖像分析表明 40KB 到 45KB),因此我們認為它可能會從當前的 32KB 增加到 48KB。L2 緩存似乎已從 1.25MB 增長到 2MB。L2 緩存的這種變化似乎也將出現在今年晚些時候推出的英特爾 Raptor Lake 中。
英特爾可能確實改進了分支預測邏輯,儘管緩衝區大小似乎(大部分)相同。這種結構基本上是每一代核心的頻繁調整點。加載和存儲緩衝區似乎也更大,因此可以期待更好的內存子系統。亂序區域和分支預測單元之間的區域有幾個塊看起來比以前大。FPU 設計看起來幾乎相同,而AVX512基於指令的各種軟件指標似乎相對沒有變化。FP 和 INT reg 文件似乎也沒有太大,因此我們預計條目大小不會大幅增加。
最後,有一些塊的佈局經過重新設計,包括 SRAM 放置以在垂直方向而不是水平方向佔用更多空間。我們將需要第一方架構討論以及來自網站的深入微基準測試,例如薯條和奶酪真正知道發生了什麼變化。
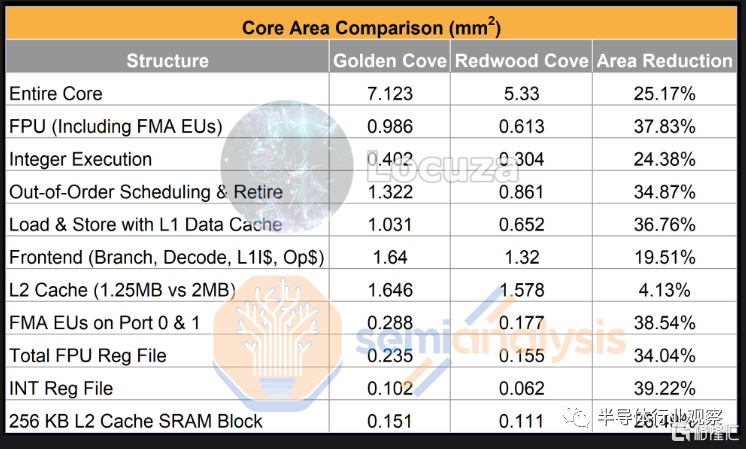
區域比較是事情開始變得有爭議的地方。
如圖所示,整個核心的總面積減少了約 25.17%(密度提高了 1.34 倍)。由於幾個原因,各個區塊的相對微縮率不同。一是兩個內核之間存在明顯的架構變化,因此總面積的比較不是直接比較。另一個原因是 SRAM 和邏輯的收縮量不相等,所以即使結構相同,我們也會根據塊的組成得到不同的微縮倍數。所以我們能夠根據來自 Nvidia 大泄漏的規格和模擬來估計 Nvidia 的下一代 Lovelace 架構的芯片尺寸時,將對此進行更詳細的討論。
純工藝最與架構無關的比較是Intel 4 和Intel 7 上 256 KB 的二級緩存之間的大小差異。我們的數據顯示面積減少了 26.5%(密度提高了 1.36 倍)。實現的縮小與英特爾聲稱的高密度 SRAM 單元非常相似,儘管需要注意的是 L2 緩存可能使用更高性能的 SRAM 單元幷包含一些邏輯,例如輔助電路。單個子單元面積減少最多的是 INT Reg 文件,接近 40%(密度提高了 1.65 倍),因此我們將其設置為實現工藝密度提高的上限。這遠低於聲稱的 2 倍收縮。
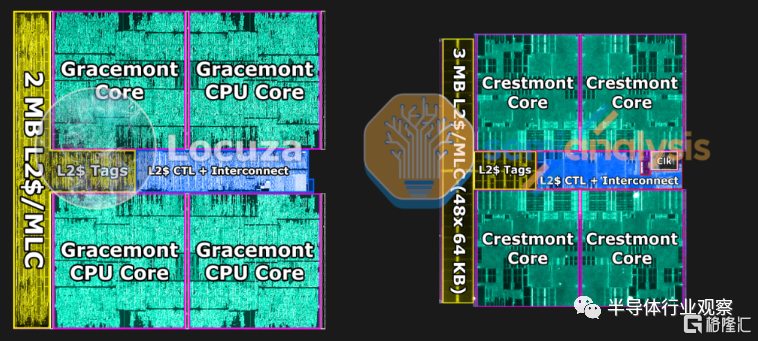
我們可以用於密度比較的計算tile上的另一個主要結構是 E 核。左邊是來自 Alder Lake 的 Gracemont,右邊是來自 Meteor Lake 的 Crestmont。從架構上看,除了 L2 緩存現在看起來是 3MB 而不是 2MB 之外,從這個比較中無法得出什麼結論。奇怪的是,一些泄漏表明 Raptor Lake 在 E 核心上移動到了 4MB L2,這將使 Meteor Lake 的 3MB 處於一個奇怪的中間地帶。Raptor Lake的細節尚未得到證實。

Crestmont 在視覺上似乎沒有對核心進行重大架構更改。面積減少約 34%(密度提高 1.52 倍)支持了這一説法。共享 L2 緩存主要由 SRAM 組成,因此該塊的收縮較小。整個 E 核心簇的面積減少了約 29%(密度提高了 1.4 倍)。具有 L2 緩存的 Golden Cove 比沒有共享 L2 的 Gracemont 大約 4.48 倍。隨着 Meteor Lake,這兩個核心之間的尺寸差異越來越大。Redwood Cove 比 Crestmont 大約 5.1 倍。英特爾的 E 核心戰略非常適合最大限度地提高每單位硅面積的性能。
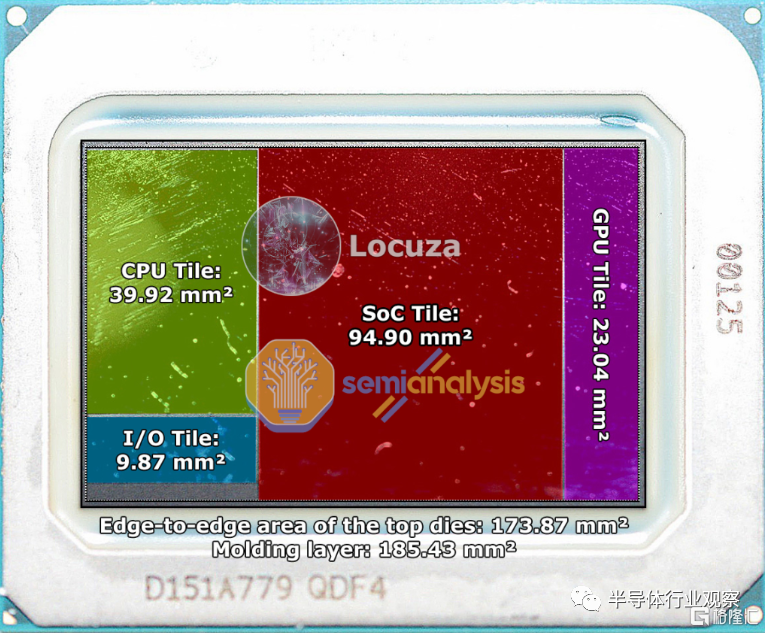
CPU 計算塊只是 Meteor Lake 中總硅片的一小部分。只有 CPU tile位於 Intel 4 製程節點上。基礎圖塊被認為是使用intel 7 節點的低成本和 Foveros 。鑑於英特爾在 Foveros 上對其進行了品牌推廣,該基礎 tile 應該是活動的,但似乎英特爾正在讓大部分基礎 tile 處於被動狀態,因為有源元素似乎位於其他小芯片上。我們可以分配給此圖塊的唯一功能似乎是供電和連接各種小芯片。該芯片上最大的芯片是“SOC”塊。
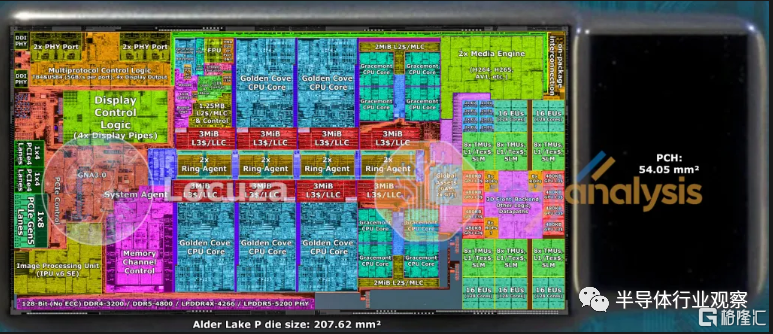
我們相信 SOC tile是現有 CPU 芯片和 PCH 上的 IP 的組合。使用 Meteor Lake,沒有 PCH/芯片組。目前,PCH 建立在 14nm 工藝節點上,作為降低額外 IP 成本的一種方式。Alder Lake 手機上的 PCH 為 54mm 2幷包含 IP,例如更多 PCIe 通道所需的 IO、USB 端口、SATA、英特爾管理引擎和 Wi-Fi 所需的數字邏輯。我們相信所有這些也將包含在 SOC tile中。此外,目前 CPU 上還有許多其他邏輯可以移到那裏。Alder Lake P 左側的整個非核心區域(TB4、顯示 PHY、PCIe PHY、數字控制邏輯、圖像處理單元、GNA AI 加速器、系統代理和內存控制器)佔用 55.9 平方毫米。該 IP 的大部分將移至 SOC 塊,部分 IP 將移至 10mm² IO 塊。
總的來説,我們相信這是14nm的 54mm 2和約 40mm 2的非核心intel 7 硅片將被整合到 SOC 芯片中。芯片組上會有一些宂餘區域,但考慮到英特爾可能會增強其中一些 IP 塊。所有這些 IP 都非常適合 SOC 塊的測量值 ~94.9 mm 2 ,即使它位於稍舊的節點上。我們相信英特爾將在這裏再次使用 14nm 或 16nm 級節點,但有傳言稱他們可能會在此塊上使用台積電 N6 節點。
對於 10mm² IO tile,我們聽到了關於 Uncore IP 位於此處的相互矛盾的傳聞。一些業內人士建議將 Thunderbolt 4 和顯示引擎移至此處,而其他人則建議將內存控制器設在此處。這兩種選擇都是可能的。4x Thunderbolt 端口,顯示引擎在 Alder Lake P 上約為 20mm 2。Alder Lake P 支持 DDR4、DDR5、LPDD4x 和 LPDDR5,並使用 16.7mm²,其中 I/O PHY + 互連分為約 6.8mm² 和9.9mm²對於內存控制器。
這些 IP 塊中的任何一個都可以緊密地安裝在 10mm² I/O 塊中,但先進的封裝顯着提高了 IO 密度,並且更 IP 優化的工藝節點可以解決這個問題。此外,英特爾可能會放棄對 DDR4 和 LPDDR4x 的支持,這可能會節省一些空間。Alder Lake M 有 2 個 Thunderbolt 端口,而 Alder Lake P(實測)有 4 個。英特爾可以在 Meteor Lake M 上保留 2 個 Thunderbolt 端口,並在 Meteor Lake P 上減少到 2 個 Thunderbolt 端口。有傳言説 IO tile 使用了台積電工藝節點,但我們還不太確定那個謠言。台積電使用量出現如此大幅增長令人難以置信,但這是可能的。

至於 GPU,英特爾表示 Meteor Lake 將擁有從 96EU 到 192EU 的圖形。我們認為已經展示的Meteor Lake包括 64EU 或 96EU。GPU 驅動程序代碼似乎表明有效配置是 64EU、128EU 和 192EU,而英特爾幻燈片顯示 96EU 和 192EU。更多關於英特爾如何實現 192EU 的信息。在 Alder Lake 上,96EU 和 2 個媒體引擎在 Intel 7 節點上總共是 42.5mm 2 。隨着英特爾 DG2 Alchemist GPU 中出現的各種架構更改(例如 AV1 編碼支持、指令緩存從 48KB 增加到 96KB、向量寄存器文件從 28KB 增加到 32KB、浮點專用問題端口),該區域可能會增長更多和整數 ALU、RT 硬件和 1024 位矩陣引擎。
起初,這似乎是一項艱鉅的任務,但 SemiAnalysis 可以確認英特爾正在將台積電的 N3B 節點用於 Meteor Lake GPU 塊。通過這種收縮,64/96EU 可以安裝在 ~23mm 2上。與台積電的 N5 相比,N3B 的體積縮小了很多,台積電的 N5 已經比intel 7 密集得多。有些人可能會質疑為什麼台積電會將其最先進節點的晶圓分配給英特爾,但這是有道理的。我們還深入研究了該決定以及英特爾去年將在台積電製造的基礎 IP。

這是一個説明圖,説明了英特爾可以做些什麼來使 GPU 顯著超出 Foveros 中介層允許的大小。正如我們在高級封裝的深入研究中所解釋的那樣,Foveros Omni 將允許對封裝進行懸垂和其他增強,特別是在功率傳輸和設計靈活性方面。這將是與標準 Foveros 不同的封裝流程,標準 Foveros 是晶圓上的芯片流程。對於 Foveros Omni,這種流程似乎是不可能的。英特爾之前曾表示,Foveros Omni 將於 2023 年投入生產。此外,他們還表示這是一款客户端移動產品。
就 Meteor Lake 的推出而言,這是有道理的。Meteor Lake 整體將於 2022 年開始生產,但這並不意味着所有變體。OEM 的朋友吿訴我們,他們首先會獲得 GPU 性能較低的移動 CPU,但今年晚些時候將會有更高 GPU 性能的移動 CPU。我們將在僅限訂閲者的部分更多地討論 Meteor Lake 的推出和斜坡。
藉助 Foveros Omni,英特爾可以設計具有更多執行單元的更大 GPU,並將其封裝在同一個 Meteor Lake P 封裝中。該 GPU 將具有銅柱,可直接從基板和成型提供電力,以幫助結構完整性。這種先進的封裝方法使英特爾能夠在有意義的地方銷售更小、更便宜的 GPU,但當他們想要擴展到更高的性能水平時,不必重新設計那麼多的芯片。這將需要重新設計封裝工藝流程、GPU 塊和基板,但這比重新設計一切的替代方案便宜得多。Foveros Omni 也可能是一種擴展 CPU 核心數量的方法,但我們還沒有聽説過英特爾計劃如何擴展到 2P 核心和 8E 核心之外的任何消息。我們確實知道英特爾計劃在移動設備和台式機上增加內核數量。
我們從英特爾的 VisiON 事件中捕獲的最後一條信息與 Meteor Lake 的最終封裝有關。我們拍了Meteor Lake底部的照片。我們會為您保存圖片,如果它們很無聊,但我們可以從中收集到的細節很有趣。

首先,M Type 4 封裝對於 Meteor Lake 來説要小得多。這可能是因為英特爾正在通過這種設計追求更小的外形尺寸。過去,英特爾曾表示 Meteor Lake 將從 5W 一路縮減至 125W。目前,Alder Lake 聲稱在 Type 4 封裝中可以縮小到 9W,但我們還沒有看到任何採用這種配置的設備。
除了縮小 X 和 Y 尺寸之外,我們認為英特爾還非常注重壓縮 Z 尺寸。由於這種高密度封裝設計,最終可以在 x86 架構上實現 5W 到 10W 級的輕薄和高性能設備。與 Alder Lake M 相比,Meteor Lake M 封裝的焊盤數量要多得多。雖然這可能是由於更多的 IO 和保留/未使用,但這並不是唯一的解釋。
我們在Angstronomics的朋友向我們解釋説,更薄和更密集的封裝需要更多的焊盤,因為它們整合電源和接地的空間更小,這意味着更多的專用焊盤可以為芯片的每個特定區域供電。更緊密的凸塊間距也意味着更小的焊盤,其表面積更小,每個焊盤的功率傳輸能力更低,因此需要更多的焊盤。
總的來説,Meteor Lake 是一個有趣的建築和設計。它標誌着英特爾的許多首創,包括大批量 Foveros(對不起,Lakefield 和 Ponte Veccio 不算在內)、使用intel 4 工藝節點的 EUV 以及台積電 N3B 工藝節點的實現。它標誌着英特爾系統架構的完全重新設計,這將在未來的架構(如 Arrow Lake)中得到反映。正如我們與 GPU 討論的那樣,chiplet tile 架構幫助英特爾完全獨立地驗證和開發單獨的 IP,甚至根據產品定位和時間表切換 IP。
Meteor Lake 分析中最具開創性或可能令人失望的方面是,與 Intel 7 相比,Intel 4 似乎只減少了不到 40% 的面積(密度提高了 1.67 倍)。而 SRAM、邏輯和模擬往往以非常不同的速度縮小跨進程節點,即使是我們可以識別為相同的最小子單元似乎也遠遠低於傳統的全節點理論縮放。正如我們之前所展示的,像 256KB L2 SRAM Block 這樣的 SRAM 重 IP 似乎只減少了 26.5% 的面積(1.36 倍的密度提升)。
根據 Intel提交給 VLSI 的論文,Intel 4 具有 50nm 柵極間距、30nm 鰭片間距、40nm 最小金屬間距、16 個金屬層、較低層的增強銅以降低線路電阻,以及 8 個 VT 選項 (4N+4P)。高密度 SRAM 單元尺寸現在在 Intel 4 上為 0.024um 2,在 TSMC N5 上為 0.021um 2 ,在 Intel 7 上為 0.0312um 2。即使根據 SRAM 密度,Intel 仍落後於 TSMC 已有 2.5 年曆史的 N5 工藝技術到官方説法。英特爾僅在其高密度 SRAM 單元上實現了 23.08% 的面積減少(密度提高了 1.3 倍)。
SRAM 縮放的問題也不獨立於英特爾。SRAM 擴展性差的一個具體例子是台積電的 N5 工藝技術。TSMC 引用 SRAM 縮放比例為 1.35 倍,而純邏輯為 1.8 倍。SRAM 縮放的崩潰對行業產生了可怕的影響。儘管英特爾 4 似乎並沒有完全縮小現實世界的密度,但它仍然領先於台積電和蘋果從 N7 到 N5的 1.49倍,以及台積電和英偉達從 N7 到 N5 的 1.5 倍。因此,英特爾縮小似乎確實是 SRAM 擴展問題範式中的全節點擴展。英特爾 4 工藝節點名稱的名稱有點奇怪,儘管台積電 N5 的高密度 SRAM 實際上比英特爾 4 的密度提高了 1.14 倍。


More Content

Physical Store(set to open in Q2 2025)
Address:
Shop LMC 307, 3/F, Lok Ma Chau MTR Station, Lok Ma Chau
Opening Hour:
9am - 9pm (Mon - Sat)
10am - 6pm (Sun and Public Holiday)

(set to open in Q2 2025)





