本文來自格隆匯專欄:半導體行業觀察 作者: IEEE
蘋果公司發佈的 M1 Ultra再次讓愛好者和分析師感到驚訝。因為這個芯片是 M1 Max 的一種變體,可以有效地將兩個芯片融合為一個,讓雙芯片設計被軟件視為單個硅片。
Nvidia在2022 年 GPU 技術大會上發佈了類似的消息,該公司首席執行官Jensen Huang宣佈公司將把公司的兩個新 Grace CPU 處理器融合到一個“超級芯片”中。
這些公吿針對不同的市場。
蘋果將目光投向了消費者和專業工作站領域,而英偉達則打算在高性能計算領域展開競爭。然而,目的上的分歧只是突顯了迅速終結單片芯片設計時代的廣泛挑戰。
多芯片設計並不是什麼新鮮事,但這個想法在過去五年中迅速流行起來。AMD、蘋果、英特爾和英偉達都不同程度地涉足。AMD通過其 EPYC 和 RYZEN 處理器追求小芯片設計。英特爾計劃效仿 Sapphire Rapids,這是一種即將推出的服務器市場架構,基於使用它稱為“tile”的小芯片而構建。現在,Apple 和 Nvidia 也加入了這一行列——儘管它們的設計針對的是截然不同的市場。

Nvidia 的 Grace CPU 超級芯片
現代芯片製造的挑戰推動了向多芯片設計的轉變。晶體管的小型化已經放緩,但前沿設計中晶體管數量的增長並沒有放緩的跡象。
Apple 的 M1 Ultra 擁有 1140 億個晶體管,芯片面積(或製造面積)約為 860 平方毫米(M1 Ultra 的官方數據無法獲得,但單個 M1 Max 芯片的芯片面積為 432 mm²)。
Nvidia 的 Grace CPU 的晶體管數量仍處於保密狀態,但與 Grace CPU 一起宣佈的 Hopper H100 GPU 包括 800 億個晶體管。從角度來看,AMD 2019 年發佈的 64 核 EYPC Rome 處理器擁有 395 億個晶體管。
晶體管將這種高度推動現代芯片生產推向了極致,使多芯片設計更具吸引力。Counterpoint 研究分析師Akshara Bassi表示:“多芯片模塊封裝使芯片廠商能夠在單片設計方面提供更好的功率效率和性能,因為芯片的裸片尺寸變得更大並且晶圓良率問題變得更加突出。”
從市場現狀看來,除了 Cerebras(一家試圖構建跨越整個硅晶圓的芯片的初創公司)之外,芯片行業似乎一致認為,單片設計正變得比它的價值更麻煩。
這種向小芯片的轉變是在製造商的支持下同步進行的。台積電是領先者,提供一套名為 3DFabric 的先進封裝。AMD 在一些 EPYC 和 RYZEN 處理器設計中使用了屬於 3DFabric 的技術,幾乎可以肯定,Apple 將其用於 M1 Ultra(Apple 尚未證實這一點,但 M1 Ultra 由 TSMC 生產)。英特爾有自己的封裝技術,例如EMIB和Foveros。雖然最初是供英特爾自己使用的,但隨着英特爾代工服務公司的開放,該公司的芯片製造技術正與更廣泛的行業相關聯。
“圍繞基礎半導體設計、製造和封裝的生態系統已經發展到支持設計節點經濟可靠地生產基於小芯片的解決方案的程度,” Hyperion Research 的高級分析師Mark Nossokoff在一封電子郵件中説。“無縫集成各種小芯片功能的軟件設計工具也已經成熟,可以優化目標解決方案的性能。”
Chiplets 將繼續存在,但就目前而言,這是一個孤島世界。AMD、Apple、Intel 和 Nvidia 正在使用他們自己的互連設計,用於特定的封裝技術。
Universal Chiplet Interconnection Express希望將行業聚集在一起。該開放標準於 2022 年 3 月 2 日宣佈,提供了一個針對“成本效益性能”的“標準”2D 包和一個針對前沿設計的“高級”封裝。UCIe 還支持通過 PCIe 和 CXL 進行封裝外連接,從而為在高性能計算環境中跨多台機器連接多個芯片開闢了潛力。
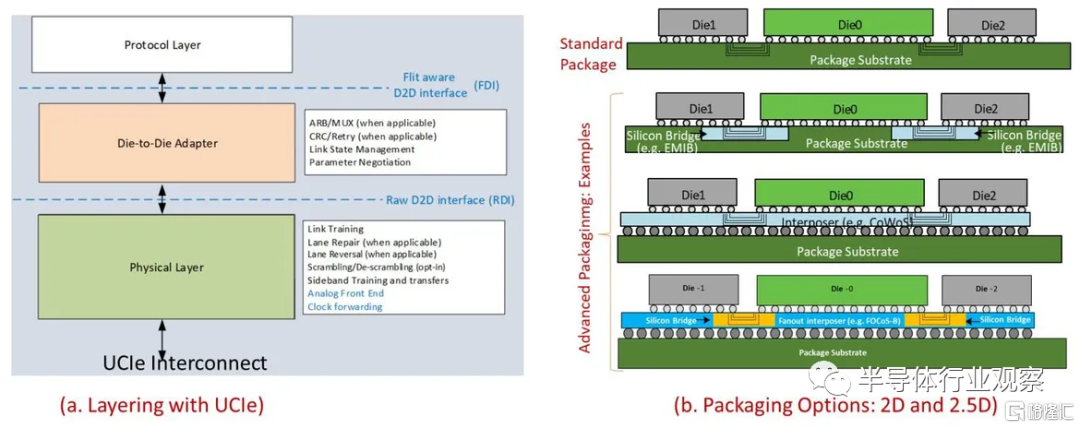
UCIe 白皮書中的 UCIe 封裝選項示例
UCIe 是一個開始,但標準的未來還有待觀察。“最初的 UCIe 發起人的創始成員代表了眾多技術設計和製造領域的傑出貢獻者,包括 HPC 生態系統,”Nossokoff 説,“但很有很多行業主要組織尚未加入,包括 Apple、 AWS、Broadcom、IBM、NVIDIA以及其他硅代工廠和內存供應商。”
Bassi 指出,英偉達可能特別不願意參與。該公司已經開放了自己的用於定製硅集成的 NVLink-C2C 互連,使其成為 UCIe 的潛在競爭對手。
但是,雖然 UCIe 和 NVLink-C2C 等互連的命運將決定遊戲規則,但它們不太可能改變正在玩的遊戲。
Apple 的 M1 Ultra 可以被視為煤礦中的金絲雀。多芯片設計不再僅限於數據中心——它正在出現在您附近的家用計算機上。
3D芯片的三種方法
幾年來,片上系統的開發人員已經開始將他們越來越大的設計分解成更小的小芯片,並將它們在同一個封裝內鏈接在一起,以有效增加硅面積及其他優勢。在 CPU 中,這些鏈接大多是所謂的 2.5D,其中小芯片彼此並排設置,並使用短而密集的互連連接。由於大多數主要製造商已就 2.5D 小芯片到小芯片通信標準達成一致,這種集成的勢頭可能只會增長。
但是,要像在同一個芯片上一樣將真正大量的數據傳輸出去,您需要更短、更密集的連接,而這隻能通過將一個芯片堆疊在另一個芯片上來實現。面對面連接兩個芯片可能意味着每平方毫米有數千個連接。
它需要大量的創新才能使其發揮作用。工程師必須弄清楚如何防止堆棧中一個芯片的熱量殺死另一個芯片,決定哪些功能應該去哪裏以及應該如何製造,防止偶爾出現的壞小芯片導致大量昂貴的啞系統,並處理隨之而來的是一次解決所有這些問題的複雜性。
以下是三個示例,從相當簡單到令人困惑的複雜,展示了 3D 堆疊現在的位置:
AMD 的 Zen 3
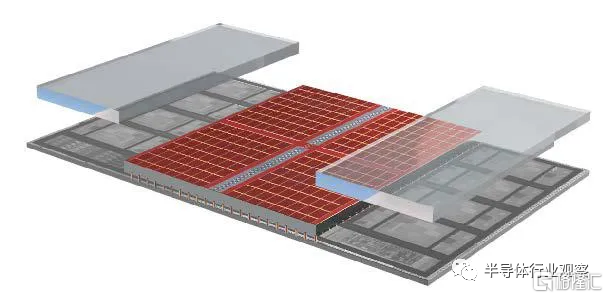 AMD 的 3D V-Cache 技術將一個 64 兆字節的 SRAM 緩存 [紅色] 和兩個空白結構小芯片連接到 Zen 3 計算小芯片上。
AMD 的 3D V-Cache 技術將一個 64 兆字節的 SRAM 緩存 [紅色] 和兩個空白結構小芯片連接到 Zen 3 計算小芯片上。
長期以來,PC 都提供了添加更多內存的選項,從而為超大型應用程序和數據繁重的工作提供更快的速度。由於 3D 芯片堆疊,AMD 的下一代 CPU 小芯片也提供了該選項。當然,這不是售後市場的附加組件,但如果您正在尋找具有更多魅力的計算機,那麼訂購具有超大緩存內存的處理器可能是您的選擇。
儘管Zen 2和新的Zen 3處理器內核都使用相同的台積電製造工藝製造——因此具有相同尺寸的晶體管、互連和其他一切——AMD 進行了如此多的架構改動,這讓他們即使沒有額外的高速緩存的前提下,Zen 3也能平均提供 19% 的性能提升。其中一個架構瑰寶是包含一組硅通孔 (TSV),垂直互連直接穿過大部分硅。TSV 構建在 Zen 3 的最高級別緩存中,即稱為 L3 的 SRAM 塊,它位於計算小芯片的中間,並在其所有八個內核之間共享。
在用於數據繁重工作負載的處理器中,Zen 3 晶圓的背面被減薄,直到 TSV 暴露出來。然後使用所謂的混合鍵合將一個 64 兆字節的 SRAM 小芯片鍵合到那些暴露的 TSV 上——這一過程類似於將銅冷焊在一起。結果是一組密集的連接可以緊密到 9 微米。最後,為了結構穩定性和熱傳導,附加空白硅芯片以覆蓋 Zen 3 CPU 芯片的其餘部分。
通過將額外的內存設置在 CPU 芯片旁邊來添加額外的內存不是一種選擇,因為數據需要很長時間才能到達處理器內核。“儘管 L3 [緩存] 大小增加了三倍,但 3D V-Cache 僅增加了四個 [時鐘] 週期的延遲——這隻能通過 3D 堆疊來實現,” AMD 高級設計工程師 John Wuu表示。
更大的緩存在高端遊戲中佔有一席之地。使用台式機鋭龍 CPU 和 3D V-Cache 可將 1080p 的遊戲速度平均提高 15%。它也適用於更嚴肅的工作,將困難的半導體設計計算的運行時間縮短了 66%。
Wuu 指出,與縮小邏輯的能力相比,業界縮小 SRAM 的能力正在放緩。因此,您可以預期未來的 SRAM 擴展包將繼續使用更成熟的製造工藝製造,而計算芯片則被推向摩爾定律的前沿。
Graphcore 的 Bow AI 處理器

Graphcore Bow AI 加速器使用 3D 芯片堆疊將性能提升 40%。
即使堆棧中的一個芯片上沒有單個晶體管,3D 集成也可以加快計算速度。總部位於英國的 AI 計算機公司Graphcore僅通過在其 AI 處理器上安裝供電芯片,就大幅提高了其系統性能。添加供電硅意味着名為 Bow 的組合芯片可以運行得更快(1.85 GHz 與 1.35 GHz 相比),並且電壓低於其前身。與上一代相比,這意味着計算機訓練神經網絡的速度提高了 40%,能耗降低了 16%。重要的是,用户無需更改其軟件即可獲得這種改進。
電源管理芯片由電容器和硅通孔組合而成。後者只是為處理器芯片提供電力和數據。真正與眾不同的是電容器。與 DRAM 中的位存儲組件一樣,這些電容器形成在硅中又深又窄的溝槽中。由於這些電荷儲存器非常靠近處理器的晶體管,因此功率傳輸變得平滑,從而使處理器內核能夠在較低電壓下更快地運行。如果沒有供電芯片,處理器必須將其工作電壓提高到高於其標稱水平才能在 1.85 GHz 下工作,從而消耗更多的功率。使用電源芯片,它也可以達到該時鐘頻率並消耗更少的功率。
用於製造BoW的製造工藝是獨一無二的,但不太可能保持這種狀態。大多數 3D 堆疊是通過將一個小芯片粘合到另一個小芯片上來完成的,而其中一個仍然在晶圓上,稱為晶圓上芯片 [參見上面的“AMD 的 Zen 3”]。相反,Bow 使用了台積電的晶圓對晶圓,其中一種類型的整個晶圓與另一種類型的整個晶圓鍵合,然後切割成芯片。Graphcore 首席技術官Simon Knowles表示,這是市場上第一款使用該技術的芯片,它使兩個裸片之間的連接密度高於使用晶圓上芯片工藝所能達到的密度。
儘管供電小芯片沒有晶體管,但它們可能會出現。Knowles 説,僅將這項技術用於供電“對我們來説只是第一步”。“在不久的將來,它會走得更遠。”
英特爾的 Ponte Vecchio 超級計算機芯片

英特爾的 Ponte Vecchio 處理器將 47 個小芯片集成到一個處理器中。
Aurora 超級計算機旨在成為 美國 首批突破 exaflop障礙的高性能計算機 (HPC)之一——每秒進行 10 億次高精度浮點計算。為了讓 Aurora 達到這些高度,英特爾的 Ponte Vecchio 將 47 塊硅片上的超過 1000 億個晶體管封裝到一個處理器中。英特爾同時使用 2.5D 和 3D 技術,將 3,100 平方毫米的硅片(幾乎等於四個Nvidia A100 GPU )壓縮成 2,330 平方毫米的佔地面積。
英特爾研究員 Wilfred Gomes吿訴參加IEEE 國際固態電路會議的工程師,該處理器將英特爾的 2D 和 3D 小芯片集成技術推向了極限。
每個 Ponte Vecchio 都是使用英特爾 2.5D 集成技術 Co-EMIB 捆綁在一起的兩個 鏡像小芯片集。Co-EMIB 在兩個 3D 小芯片堆棧之間形成高密度互連的橋樑。橋本身是嵌入封裝有機基板中的一小塊硅。硅上的互連線的密度可以是有機襯底上的兩倍。
Co-EMIB 管芯還將高帶寬內存和 I/O 小芯片連接到“基礎塊”,這是堆疊其餘部分的最大小芯片。
基礎tile使用英特爾的 3D 堆疊技術,稱為 Foveros,在其上堆疊計算和緩存小芯片。該技術在兩個芯片之間建立了密集的芯片到芯片垂直連接陣列。這些連接可以是 36 微米,除了短銅柱和焊料微凸塊。信號和電源通過硅通孔進入這個堆棧 ,相當寬的垂直互連直接穿過大部分硅。
八個計算tile、四個緩存tile和八個用於從處理器散熱的空白“熱”tile都連接到基礎tile。基礎本身提供緩存內存和允許任何計算塊訪問任何內存的網絡。
不用説,這一切都不容易。Gomes 説,它在良率管理、時鐘電路、熱調節和功率傳輸方面進行了創新。例如,英特爾工程師選擇為處理器提供高於正常電壓(1.8 伏)的電壓,以便電流足夠低以簡化封裝。基礎塊中的電路將電壓降低到接近 0.7 V 以用於計算塊,並且每個計算塊必須在基礎塊中有自己的電源域。這種能力的關鍵是新型高效電感器,稱為同軸磁性集成電感器。因為這些都內置在封裝基板中,所以在向計算塊提供電壓之前,電路實際上在基礎塊和封裝之間來回蜿蜒。
Gomes 説,從 2008 年的第一台 petaflop 超級計算機到今年的 exaflops機器, 用了整整 14 年。Gomes 吿訴工程師,但高級封裝(如 3D 堆疊)是可以幫助將下一個千倍計算改進縮短到僅六年的技術之一。


More Content